 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSustainable LLM Inference for Edge AI: Evaluating Quantized LLMs for Energy Efficiency, Output Accuracy, and Inference Latency
Apr 04, 2025



Deploying Large Language Models (LLMs) on edge devices presents significant challenges due to computational constraints, memory limitations, inference speed, and energy consumption. Model quantization has emerged as a key technique to enable efficient LLM inference by reducing model size and computational overhead. In this study, we conduct a comprehensive analysis of 28 quantized LLMs from the Ollama library, which applies by default Post-Training Quantization (PTQ) and weight-only quantization techniques, deployed on an edge device (Raspberry Pi 4 with 4GB RAM). We evaluate energy efficiency, inference performance, and output accuracy across multiple quantization levels and task types. Models are benchmarked on five standardized datasets (CommonsenseQA, BIG-Bench Hard, TruthfulQA, GSM8K, and HumanEval), and we employ a high-resolution, hardware-based energy measurement tool to capture real-world power consumption. Our findings reveal the trade-offs between energy efficiency, inference speed, and accuracy in different quantization settings, highlighting configurations that optimize LLM deployment for resource-constrained environments. By integrating hardware-level energy profiling with LLM benchmarking, this study provides actionable insights for sustainable AI, bridging a critical gap in existing research on energy-aware LLM deployment.
Aligning the Norwegian UD Treebank with Entity and Coreference Information
May 25, 2023



This paper presents a merged collection of entity and coreference annotated data grounded in the Universal Dependencies (UD) treebanks for the two written forms of Norwegian: Bokm{\aa}l and Nynorsk. The aligned and converted corpora are the Norwegian Named Entities (NorNE) and Norwegian Anaphora Resolution Corpus (NARC). While NorNE is aligned with an older version of the treebank, NARC is misaligned and requires extensive transformation from the original annotations to the UD structure and CoNLL-U format. We here demonstrate the conversion and alignment processes, along with an analysis of discovered issues and errors in the data - some of which include data split overlaps in the original treebank. These procedures and the developed system may prove helpful for future corpus alignment and coreference annotation endeavors. The merged corpora comprise the first Norwegian UD treebank enriched with named entities and coreference information.
Annotating Norwegian Language Varieties on Twitter for Part-of-Speech
Oct 12, 2022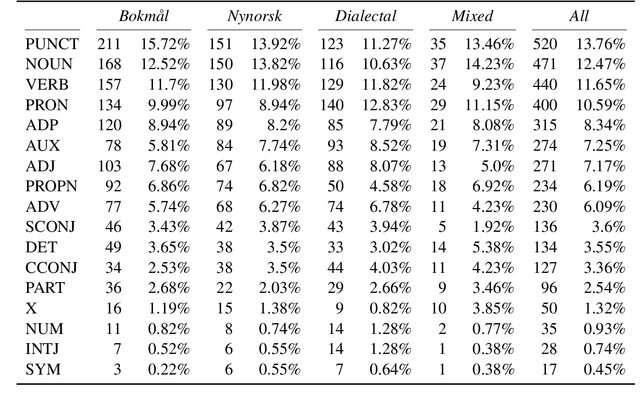
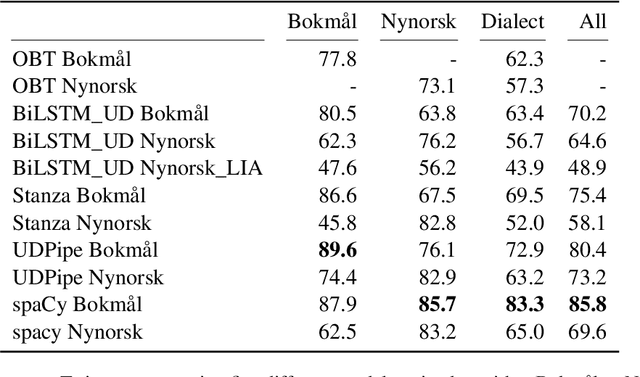
Norwegian Twitter data poses an interesting challenge for Natural Language Processing (NLP) tasks. These texts are difficult for models trained on standardized text in one of the two Norwegian written forms (Bokm{\aa}l and Nynorsk), as they contain both the typical variation of social media text, as well as a large amount of dialectal variety. In this paper we present a novel Norwegian Twitter dataset annotated with POS-tags. We show that models trained on Universal Dependency (UD) data perform worse when evaluated against this dataset, and that models trained on Bokm{\aa}l generally perform better than those trained on Nynorsk. We also see that performance on dialectal tweets is comparable to the written standards for some models. Finally we perform a detailed analysis of the errors that models commonly make on this data.