 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSustainable LLM Inference for Edge AI: Evaluating Quantized LLMs for Energy Efficiency, Output Accuracy, and Inference Latency
Apr 04, 2025



Deploying Large Language Models (LLMs) on edge devices presents significant challenges due to computational constraints, memory limitations, inference speed, and energy consumption. Model quantization has emerged as a key technique to enable efficient LLM inference by reducing model size and computational overhead. In this study, we conduct a comprehensive analysis of 28 quantized LLMs from the Ollama library, which applies by default Post-Training Quantization (PTQ) and weight-only quantization techniques, deployed on an edge device (Raspberry Pi 4 with 4GB RAM). We evaluate energy efficiency, inference performance, and output accuracy across multiple quantization levels and task types. Models are benchmarked on five standardized datasets (CommonsenseQA, BIG-Bench Hard, TruthfulQA, GSM8K, and HumanEval), and we employ a high-resolution, hardware-based energy measurement tool to capture real-world power consumption. Our findings reveal the trade-offs between energy efficiency, inference speed, and accuracy in different quantization settings, highlighting configurations that optimize LLM deployment for resource-constrained environments. By integrating hardware-level energy profiling with LLM benchmarking, this study provides actionable insights for sustainable AI, bridging a critical gap in existing research on energy-aware LLM deployment.
A Comparative Study on Large Language Models for Log Parsing
Sep 04, 2024Background: Log messages provide valuable information about the status of software systems. This information is provided in an unstructured fashion and automated approaches are applied to extract relevant parameters. To ease this process, log parsing can be applied, which transforms log messages into structured log templates. Recent advances in language models have led to several studies that apply ChatGPT to the task of log parsing with promising results. However, the performance of other state-of-the-art large language models (LLMs) on the log parsing task remains unclear. Aims: In this study, we investigate the current capability of state-of-the-art LLMs to perform log parsing. Method: We select six recent LLMs, including both paid proprietary (GPT-3.5, Claude 2.1) and four free-to-use open models, and compare their performance on system logs obtained from a selection of mature open-source projects. We design two different prompting approaches and apply the LLMs on 1, 354 log templates across 16 different projects. We evaluate their effectiveness, in the number of correctly identified templates, and the syntactic similarity between the generated templates and the ground truth. Results: We found that free-to-use models are able to compete with paid models, with CodeLlama extracting 10% more log templates correctly than GPT-3.5. Moreover, we provide qualitative insights into the usability of language models (e.g., how easy it is to use their responses). Conclusions: Our results reveal that some of the smaller, free-to-use LLMs can considerably assist log parsing compared to their paid proprietary competitors, especially code-specialized models.
On Evaluating Self-Adaptive and Self-Healing Systems using Chaos Engineering
Aug 28, 2022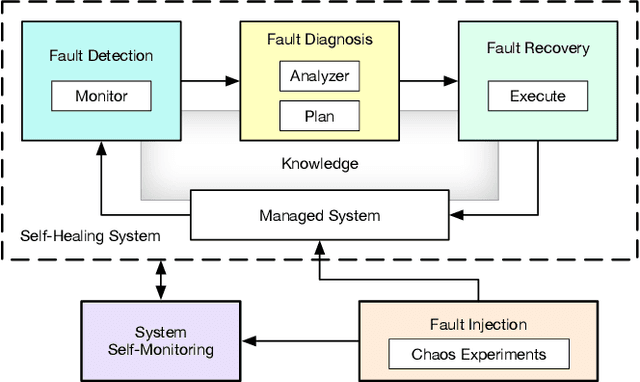
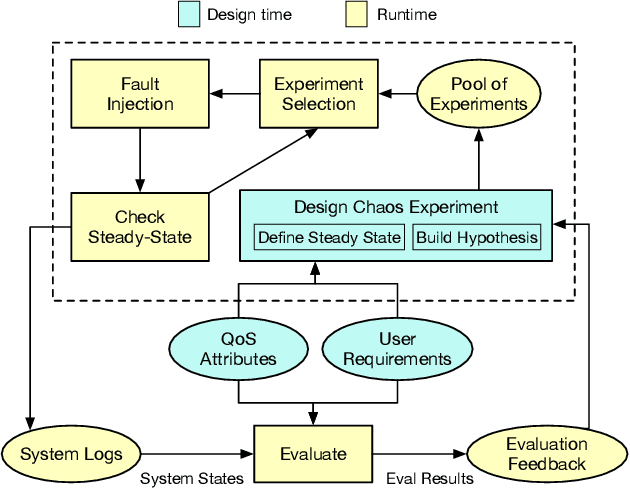
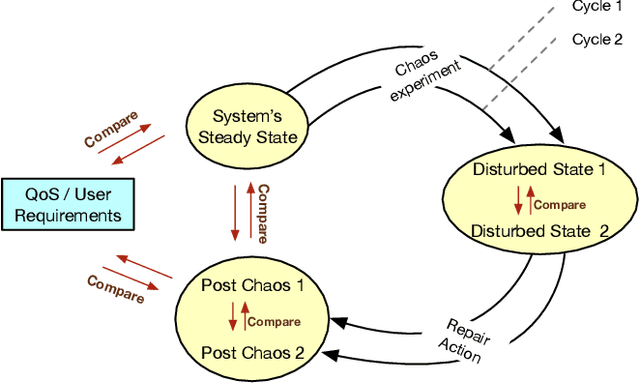
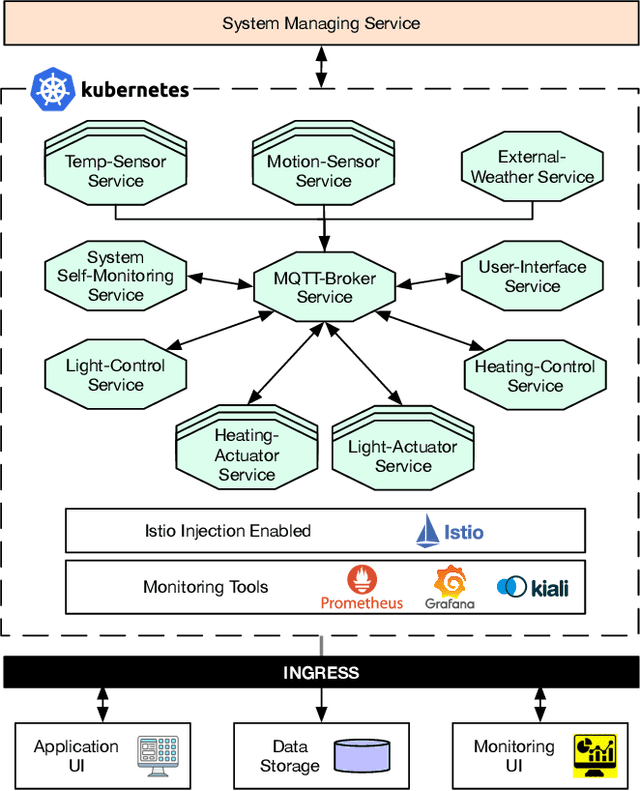
With the growing adoption of self-adaptive systems in various domains, there is an increasing need for strategies to assess their correct behavior. In particular self-healing systems, which aim to provide resilience and fault-tolerance, often deal with unanticipated failures in critical and highly dynamic environments. Their reactive and complex behavior makes it challenging to assess if these systems execute according to the desired goals. Recently, several studies have expressed concern about the lack of systematic evaluation methods for self-healing behavior. In this paper, we propose CHESS, an approach for the systematic evaluation of self-adaptive and self-healing systems that builds on chaos engineering. Chaos engineering is a methodology for subjecting a system to unexpected conditions and scenarios. It has shown great promise in helping developers build resilient microservice architectures and cyber-physical systems. CHESS turns this idea around by using chaos engineering to evaluate how well a self-healing system can withstand such perturbations. We investigate the viability of this approach through an exploratory study on a self-healing smart office environment. The study helps us explore the promises and limitations of the approach, as well as identify directions where additional work is needed. We conclude with a summary of lessons learned.
Adaptive Immunity for Software: Towards Autonomous Self-healing Systems
Jan 07, 2021

Testing and code reviews are known techniques to improve the quality and robustness of software. Unfortunately, the complexity of modern software systems makes it impossible to anticipate all possible problems that can occur at runtime, which limits what issues can be found using testing and reviews. Thus, it is of interest to consider autonomous self-healing software systems, which can automatically detect, diagnose, and contain unanticipated problems at runtime. Most research in this area has adopted a model-driven approach, where actual behavior is checked against a model specifying the intended behavior, and a controller takes action when the system behaves outside of the specification. However, it is not easy to develop these specifications, nor to keep them up-to-date as the system evolves. We pose that, with the recent advances in machine learning, such models may be learned by observing the system. Moreover, we argue that artificial immune systems (AISs) are particularly well-suited for building self-healing systems, because of their anomaly detection and diagnosis capabilities. We present the state-of-the-art in self-healing systems and in AISs, surveying some of the research directions that have been considered up to now. To help advance the state-of-the-art, we develop a research agenda for building self-healing software systems using AISs, identifying required foundations, and promising research directions.