 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWisdom and Delusion of LLM Ensembles for Code Generation and Repair
Oct 24, 2025Today's pursuit of a single Large Language Model (LMM) for all software engineering tasks is resource-intensive and overlooks the potential benefits of complementarity, where different models contribute unique strengths. However, the degree to which coding LLMs complement each other and the best strategy for maximizing an ensemble's potential are unclear, leaving practitioners without a clear path to move beyond single-model systems. To address this gap, we empirically compare ten individual LLMs from five families, and three ensembles of these LLMs across three software engineering benchmarks covering code generation and program repair. We assess the complementarity between models and the performance gap between the best individual model and the ensembles. Next, we evaluate various selection heuristics to identify correct solutions from an ensemble's candidate pool. We find that the theoretical upperbound for an ensemble's performance can be 83% above the best single model. Our results show that consensus-based strategies for selecting solutions fall into a "popularity trap," amplifying common but incorrect outputs. In contrast, a diversity-based strategy realizes up to 95% of this theoretical potential, and proves effective even in small two-model ensembles, enabling a cost-efficient way to enhance performance by leveraging multiple LLMs.
The Art of Repair: Optimizing Iterative Program Repair with Instruction-Tuned Models
May 05, 2025



Automatic program repair (APR) aims to reduce the manual efforts required to identify and fix errors in source code. Before the rise of LLM-based agents, a common strategy was to increase the number of generated patches, sometimes to the thousands, to achieve better repair results on benchmarks. More recently, self-iterative capabilities enabled LLMs to refine patches over multiple rounds guided by feedback. However, literature often focuses on many iterations and disregards different numbers of outputs. We investigate an APR pipeline that balances these two approaches, the generation of multiple outputs and multiple rounds of iteration, while imposing a limit of 10 total patches per bug. We apply three SOTA instruction-tuned LLMs - DeepSeekCoder-Instruct, Codellama-Instruct, Llama3.1-Instruct - to the APR task. We further fine-tune each model on an APR dataset with three sizes (1K, 30K, 65K) and two techniques (Full Fine-Tuning and LoRA), allowing us to assess their repair capabilities on two APR benchmarks: HumanEval-Java and Defects4J. Our results show that by using only a fraction (<1%) of the fine-tuning dataset, we can achieve improvements of up to 78% in the number of plausible patches generated, challenging prior studies that reported limited gains using Full Fine-Tuning. However, we find that exceeding certain thresholds leads to diminishing outcomes, likely due to overfitting. Moreover, we show that base models greatly benefit from creating patches in an iterative fashion rather than generating them all at once. In addition, the benefit of iterative strategies becomes more pronounced in complex benchmarks. Even fine-tuned models, while benefiting less from iterations, still gain advantages, particularly on complex benchmarks. The research underscores the need for balanced APR strategies that combine multi-output generation and iterative refinement.
Semantic-Preserving Transformations as Mutation Operators: A Study on Their Effectiveness in Defect Detection
Mar 30, 2025



Recent advances in defect detection use language models. Existing works enhanced the training data to improve the models' robustness when applied to semantically identical code (i.e., predictions should be the same). However, the use of semantically identical code has not been considered for improving the tools during their application - a concept closely related to metamorphic testing. The goal of our study is to determine whether we can use semantic-preserving transformations, analogue to mutation operators, to improve the performance of defect detection tools in the testing stage. We first collect existing publications which implemented semantic-preserving transformations and share their implementation, such that we can reuse them. We empirically study the effectiveness of three different ensemble strategies for enhancing defect detection tools. We apply the collected transformations on the Devign dataset, considering vulnerabilities as a type of defect, and two fine-tuned large language models for defect detection (VulBERTa, PLBART). We found 28 publications with 94 different transformations. We choose to implement 39 transformations from four of the publications, but a manual check revealed that 23 out 39 transformations change code semantics. Using the 16 remaining, correct transformations and three ensemble strategies, we were not able to increase the accuracy of the defect detection models. Our results show that reusing shared semantic-preserving transformation is difficult, sometimes even causing wrongful changes to the semantics. Keywords: defect detection, language model, semantic-preserving transformation, ensemble
Codehacks: A Dataset of Adversarial Tests for Competitive Programming Problems Obtained from Codeforces
Mar 30, 2025Software is used in critical applications in our day-to-day life and it is important to ensure its correctness. One popular approach to assess correctness is to evaluate software on tests. If a test fails, it indicates a fault in the software under test; if all tests pass correctly, one may assume that the software is correct. However, the reliability of these results depends on the test suite considered, and there is a risk of false negatives (i.e. software that passes all available tests but contains bugs because some cases are not tested). Therefore, it is important to consider error-inducing test cases when evaluating software. To support data-driven creation of such a test-suite, which is especially of interest for testing software synthesized from large language models, we curate a dataset (Codehacks) of programming problems together with corresponding error-inducing test cases (i.e., "hacks"). This dataset is collected from the wild, in particular, from the Codeforces online judge platform. The dataset comprises 288,617 hacks for 5,578 programming problems, each with a natural language description, as well as the source code for 2,196 submitted solutions to these problems that can be broken with their corresponding hacks. Keywords: competitive programming, language model, dataset
Fully Autonomous Programming using Iterative Multi-Agent Debugging with Large Language Models
Mar 10, 2025Program synthesis with Large Language Models (LLMs) suffers from a "near-miss syndrome": the generated code closely resembles a correct solution but fails unit tests due to minor errors. We address this with a multi-agent framework called Synthesize, Execute, Instruct, Debug, and Repair (SEIDR). Effectively applying SEIDR to instruction-tuned LLMs requires determining (a) optimal prompts for LLMs, (b) what ranking algorithm selects the best programs in debugging rounds, and (c) balancing the repair of unsuccessful programs with the generation of new ones. We empirically explore these trade-offs by comparing replace-focused, repair-focused, and hybrid debug strategies. We also evaluate lexicase and tournament selection to rank candidates in each generation. On Program Synthesis Benchmark 2 (PSB2), our framework outperforms both conventional use of OpenAI Codex without a repair phase and traditional genetic programming approaches. SEIDR outperforms the use of an LLM alone, solving 18 problems in C++ and 20 in Python on PSB2 at least once across experiments. To assess generalizability, we employ GPT-3.5 and Llama 3 on the PSB2 and HumanEval-X benchmarks. Although SEIDR with these models does not surpass current state-of-the-art methods on the Python benchmarks, the results on HumanEval-C++ are promising. SEIDR with Llama 3-8B achieves an average pass@100 of 84.2%. Across all SEIDR runs, 163 of 164 problems are solved at least once with GPT-3.5 in HumanEval-C++, and 162 of 164 with the smaller Llama 3-8B. We conclude that SEIDR effectively overcomes the near-miss syndrome in program synthesis with LLMs.
A Comparative Study on Large Language Models for Log Parsing
Sep 04, 2024Background: Log messages provide valuable information about the status of software systems. This information is provided in an unstructured fashion and automated approaches are applied to extract relevant parameters. To ease this process, log parsing can be applied, which transforms log messages into structured log templates. Recent advances in language models have led to several studies that apply ChatGPT to the task of log parsing with promising results. However, the performance of other state-of-the-art large language models (LLMs) on the log parsing task remains unclear. Aims: In this study, we investigate the current capability of state-of-the-art LLMs to perform log parsing. Method: We select six recent LLMs, including both paid proprietary (GPT-3.5, Claude 2.1) and four free-to-use open models, and compare their performance on system logs obtained from a selection of mature open-source projects. We design two different prompting approaches and apply the LLMs on 1, 354 log templates across 16 different projects. We evaluate their effectiveness, in the number of correctly identified templates, and the syntactic similarity between the generated templates and the ground truth. Results: We found that free-to-use models are able to compete with paid models, with CodeLlama extracting 10% more log templates correctly than GPT-3.5. Moreover, we provide qualitative insights into the usability of language models (e.g., how easy it is to use their responses). Conclusions: Our results reveal that some of the smaller, free-to-use LLMs can considerably assist log parsing compared to their paid proprietary competitors, especially code-specialized models.
A Novel Approach for Automatic Program Repair using Round-Trip Translation with Large Language Models
Jan 15, 2024Research shows that grammatical mistakes in a sentence can be corrected by translating it to another language and back using neural machine translation with language models. We investigate whether this correction capability of Large Language Models (LLMs) extends to Automatic Program Repair (APR). Current generative models for APR are pre-trained on source code and fine-tuned for repair. This paper proposes bypassing the fine-tuning step and using Round-Trip Translation (RTT): translation of code from one programming language to another programming or natural language, and back. We hypothesize that RTT with LLMs restores the most commonly seen patterns in code during pre-training, i.e., performs a regression toward the mean, which removes bugs as they are a form of noise w.r.t. the more frequent, natural, bug-free code in the training data. To test this hypothesis, we employ eight recent LLMs pre-trained on code, including the latest GPT versions, and four common program repair benchmarks in Java. We find that RTT with English as an intermediate language repaired 101 of 164 bugs with GPT-4 on the HumanEval-Java dataset. Moreover, 46 of these are unique bugs that are not repaired by other LLMs fine-tuned for APR. Our findings highlight the viability of round-trip translation with LLMs as a technique for automated program repair and its potential for research in software engineering. Keywords: automated program repair, large language model, machine translation
An Exploratory Literature Study on Sharing and Energy Use of Language Models for Source Code
Jul 05, 2023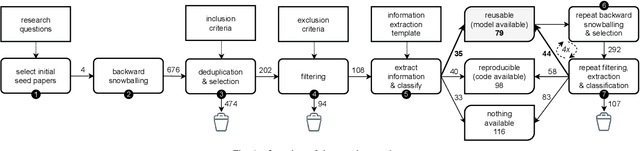

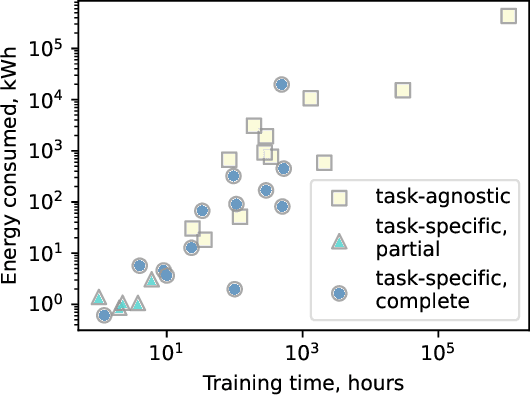

Large language models trained on source code can support a variety of software development tasks, such as code recommendation and program repair. Large amounts of data for training such models benefit the models' performance. However, the size of the data and models results in long training times and high energy consumption. While publishing source code allows for replicability, users need to repeat the expensive training process if models are not shared. The main goal of the study is to investigate if publications that trained language models for software engineering (SE) tasks share source code and trained artifacts. The second goal is to analyze the transparency on training energy usage. We perform a snowballing-based literature search to find publications on language models for source code, and analyze their reusability from a sustainability standpoint. From 494 unique publications, we identified 293 relevant publications that use language models to address code-related tasks. Among them, 27% (79 out of 293) make artifacts available for reuse. This can be in the form of tools or IDE plugins designed for specific tasks or task-agnostic models that can be fine-tuned for a variety of downstream tasks. Moreover, we collect insights on the hardware used for model training, as well as training time, which together determine the energy consumption of the development process. We find that there are deficiencies in the sharing of information and artifacts for current studies on source code models for software engineering tasks, with 40% of the surveyed papers not sharing source code or trained artifacts. We recommend the sharing of source code as well as trained artifacts, to enable sustainable reproducibility. Moreover, comprehensive information on training times and hardware configurations should be shared for transparency on a model's carbon footprint.
Constructing a Knowledge Graph from Textual Descriptions of Software Vulnerabilities in the National Vulnerability Database
May 15, 2023



Knowledge graphs have shown promise for several cybersecurity tasks, such as vulnerability assessment and threat analysis. In this work, we present a new method for constructing a vulnerability knowledge graph from information in the National Vulnerability Database (NVD). Our approach combines named entity recognition (NER), relation extraction (RE), and entity prediction using a combination of neural models, heuristic rules, and knowledge graph embeddings. We demonstrate how our method helps to fix missing entities in knowledge graphs used for cybersecurity and evaluate the performance.
The EarlyBIRD Catches the Bug: On Exploiting Early Layers of Encoder Models for More Efficient Code Classification
May 08, 2023



The use of modern Natural Language Processing (NLP) techniques has shown to be beneficial for software engineering tasks, such as vulnerability detection and type inference. However, training deep NLP models requires significant computational resources. This paper explores techniques that aim at achieving the best usage of resources and available information in these models. We propose a generic approach, EarlyBIRD, to build composite representations of code from the early layers of a pre-trained transformer model. We empirically investigate the viability of this approach on the CodeBERT model by comparing the performance of 12 strategies for creating composite representations with the standard practice of only using the last encoder layer. Our evaluation on four datasets shows that several early layer combinations yield better performance on defect detection, and some combinations improve multi-class classification. More specifically, we obtain a +2 average improvement of detection accuracy on Devign with only 3 out of 12 layers of CodeBERT and a 3.3x speed-up of fine-tuning. These findings show that early layers can be used to obtain better results using the same resources, as well as to reduce resource usage during fine-tuning and inference.