 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Autonomous Programming using Iterative Multi-Agent Debugging with Large Language Models
Mar 10, 2025Program synthesis with Large Language Models (LLMs) suffers from a "near-miss syndrome": the generated code closely resembles a correct solution but fails unit tests due to minor errors. We address this with a multi-agent framework called Synthesize, Execute, Instruct, Debug, and Repair (SEIDR). Effectively applying SEIDR to instruction-tuned LLMs requires determining (a) optimal prompts for LLMs, (b) what ranking algorithm selects the best programs in debugging rounds, and (c) balancing the repair of unsuccessful programs with the generation of new ones. We empirically explore these trade-offs by comparing replace-focused, repair-focused, and hybrid debug strategies. We also evaluate lexicase and tournament selection to rank candidates in each generation. On Program Synthesis Benchmark 2 (PSB2), our framework outperforms both conventional use of OpenAI Codex without a repair phase and traditional genetic programming approaches. SEIDR outperforms the use of an LLM alone, solving 18 problems in C++ and 20 in Python on PSB2 at least once across experiments. To assess generalizability, we employ GPT-3.5 and Llama 3 on the PSB2 and HumanEval-X benchmarks. Although SEIDR with these models does not surpass current state-of-the-art methods on the Python benchmarks, the results on HumanEval-C++ are promising. SEIDR with Llama 3-8B achieves an average pass@100 of 84.2%. Across all SEIDR runs, 163 of 164 problems are solved at least once with GPT-3.5 in HumanEval-C++, and 162 of 164 with the smaller Llama 3-8B. We conclude that SEIDR effectively overcomes the near-miss syndrome in program synthesis with LLMs.
PhilHumans: Benchmarking Machine Learning for Personal Health
May 04, 2024



The use of machine learning in Healthcare has the potential to improve patient outcomes as well as broaden the reach and affordability of Healthcare. The history of other application areas indicates that strong benchmarks are essential for the development of intelligent systems. We present Personal Health Interfaces Leveraging HUman-MAchine Natural interactions (PhilHumans), a holistic suite of benchmarks for machine learning across different Healthcare settings - talk therapy, diet coaching, emergency care, intensive care, obstetric sonography - as well as different learning settings, such as action anticipation, timeseries modeling, insight mining, language modeling, computer vision, reinforcement learning and program synthesis
Intensive Care as One Big Sequence Modeling Problem
Feb 27, 2024



Reinforcement Learning in Healthcare is typically concerned with narrow self-contained tasks such as sepsis prediction or anesthesia control. However, previous research has demonstrated the potential of generalist models (the prime example being Large Language Models) to outperform task-specific approaches due to their capability for implicit transfer learning. To enable training of foundation models for Healthcare as well as leverage the capabilities of state of the art Transformer architectures, we propose the paradigm of Healthcare as Sequence Modeling, in which interaction between the patient and the healthcare provider is represented as an event stream and tasks like diagnosis and treatment selection are modeled as prediction of future events in the stream. To explore this paradigm experimentally we develop MIMIC-SEQ, a sequence modeling benchmark derived by translating heterogenous clinical records from MIMIC-IV dataset into a uniform event stream format, train a baseline model and explore its capabilities.
Fully Autonomous Programming with Large Language Models
Apr 20, 2023



Current approaches to program synthesis with Large Language Models (LLMs) exhibit a "near miss syndrome": they tend to generate programs that semantically resemble the correct answer (as measured by text similarity metrics or human evaluation), but achieve a low or even zero accuracy as measured by unit tests due to small imperfections, such as the wrong input or output format. This calls for an approach known as Synthesize, Execute, Debug (SED), whereby a draft of the solution is generated first, followed by a program repair phase addressing the failed tests. To effectively apply this approach to instruction-driven LLMs, one needs to determine which prompts perform best as instructions for LLMs, as well as strike a balance between repairing unsuccessful programs and replacing them with newly generated ones. We explore these trade-offs empirically, comparing replace-focused, repair-focused, and hybrid debug strategies, as well as different template-based and model-based prompt-generation techniques. We use OpenAI Codex as the LLM and Program Synthesis Benchmark 2 as a database of problem descriptions and tests for evaluation. The resulting framework outperforms both conventional usage of Codex without the repair phase and traditional genetic programming approaches.
Autoencoders as Tools for Program Synthesis
Sep 05, 2021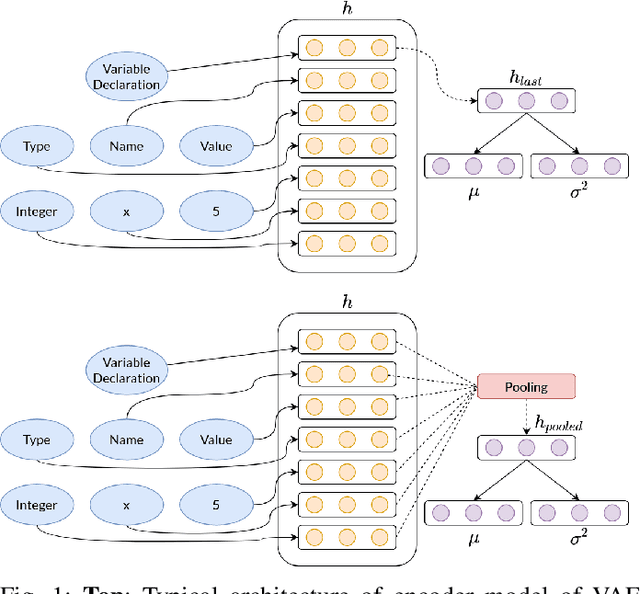
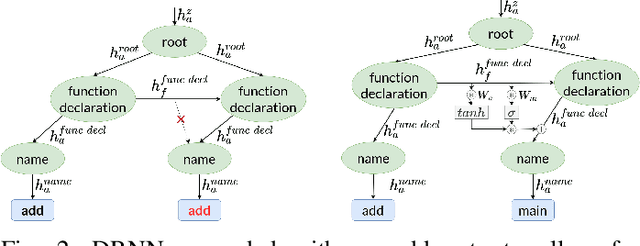
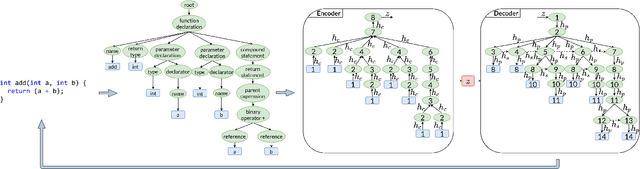
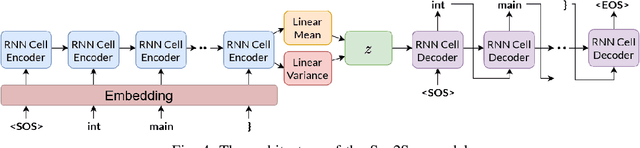
Recently there have been many advances in research on language modeling of source code. Applications range from code suggestion and completion to code summarization. However, complete program synthesis of industry-grade programming languages remains an open problem. In this work, we introduce and experimentally validate a variational autoencoder model for program synthesis of industry-grade programming languages. This model makes use of the inherent tree structure of code and can be used in conjunction with gradient free optimization techniques like evolutionary methods to generate programs that maximize a given fitness function, for instance, passing a set of test cases. A demonstration is avaliable at https://tree2tree.app
BF++: a language for general-purpose program synthesis
Feb 18, 2021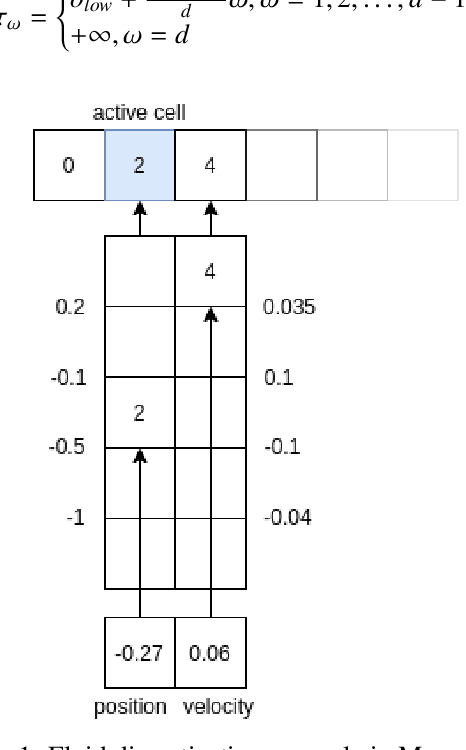
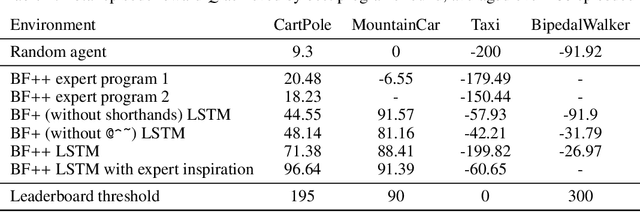
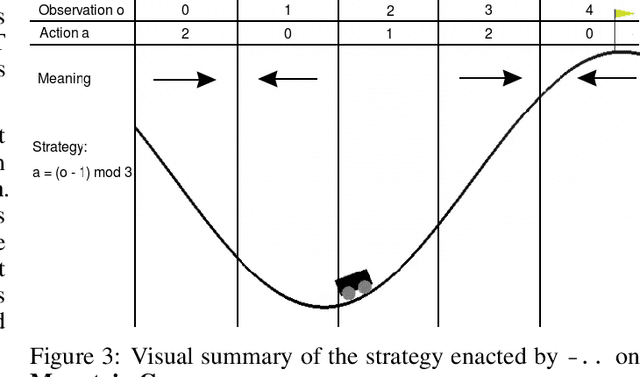
Most state of the art decision systems based on Reinforcement Learning (RL) are data-driven black-box neural models, where it is often difficult to incorporate expert knowledge into the models or let experts review and validate the learned decision mechanisms. Knowledge-insertion and model review are important requirements in many applications involving human health and safety. One way to bridge the gap between data and knowledge driven systems is program synthesis: replacing a neural network that outputs decisions with a symbolic program generated by a neural network or by means of genetic programming. We propose a new programming language, BF++, designed specifically for automatic programming of agents in a Partially Observable Markov Decision Process (POMDP) setting and apply neural program synthesis to solve standard OpenAI Gym benchmarks.
Neurogenetic Programming Framework for Explainable Reinforcement Learning
Feb 08, 2021
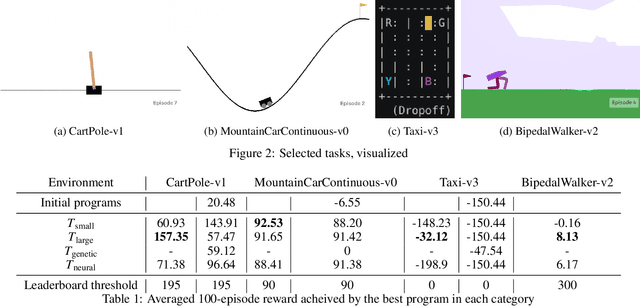
Automatic programming, the task of generating computer programs compliant with a specification without a human developer, is usually tackled either via genetic programming methods based on mutation and recombination of programs, or via neural language models. We propose a novel method that combines both approaches using a concept of a virtual neuro-genetic programmer: using evolutionary methods as an alternative to gradient descent for neural network training}, or scrum team. We demonstrate its ability to provide performant and explainable solutions for various OpenAI Gym tasks, as well as inject expert knowledge into the otherwise data-driven search for solutions.