 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhilHumans: Benchmarking Machine Learning for Personal Health
May 04, 2024



The use of machine learning in Healthcare has the potential to improve patient outcomes as well as broaden the reach and affordability of Healthcare. The history of other application areas indicates that strong benchmarks are essential for the development of intelligent systems. We present Personal Health Interfaces Leveraging HUman-MAchine Natural interactions (PhilHumans), a holistic suite of benchmarks for machine learning across different Healthcare settings - talk therapy, diet coaching, emergency care, intensive care, obstetric sonography - as well as different learning settings, such as action anticipation, timeseries modeling, insight mining, language modeling, computer vision, reinforcement learning and program synthesis
Towards Detecting Need for Empathetic Response in Motivational Interviewing
May 20, 2021
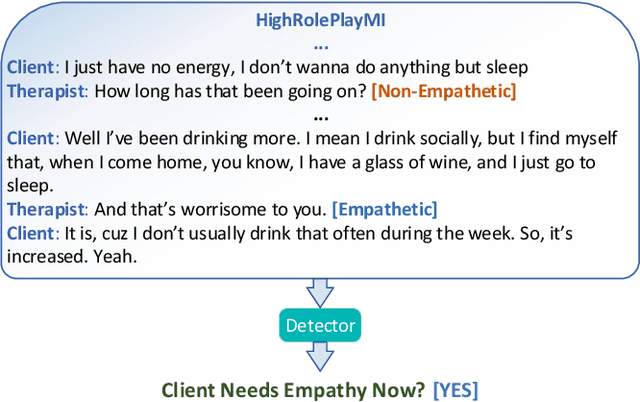
Empathetic response from the therapist is key to the success of clinical psychotherapy, especially motivational interviewing. Previous work on computational modelling of empathy in motivational interviewing has focused on offline, session-level assessment of therapist empathy, where empathy captures all efforts that the therapist makes to understand the client's perspective and convey that understanding to the client. In this position paper, we propose a novel task of turn-level detection of client need for empathy. Concretely, we propose to leverage pre-trained language models and empathy-related general conversation corpora in a unique labeller-detector framework, where the labeller automatically annotates a motivational interviewing conversation corpus with empathy labels to train the detector that determines the need for therapist empathy. We also lay out our strategies of extending the detector with additional-input and multi-task setups to improve its detection and explainability.
Transformer-based Cascaded Multimodal Speech Translation
Nov 08, 2019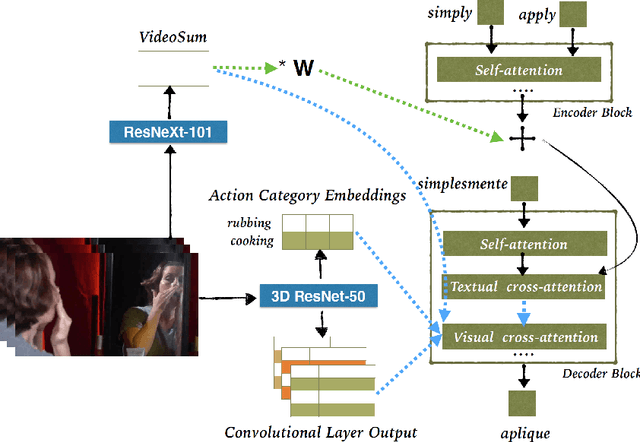
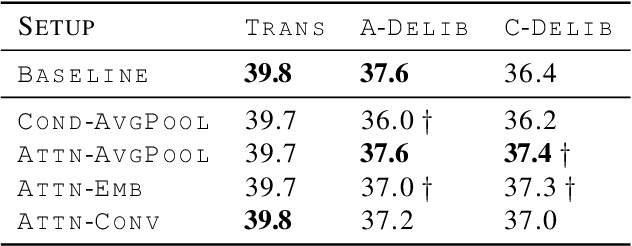
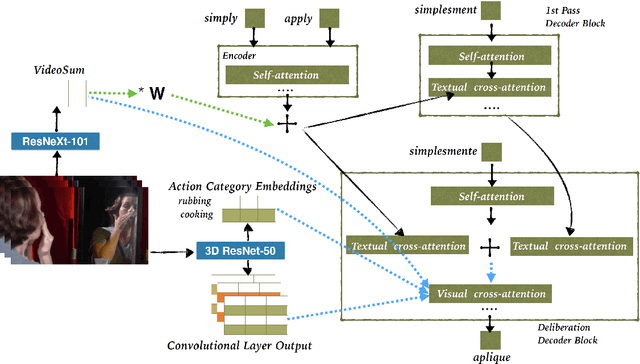
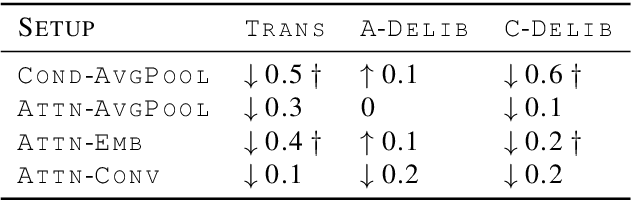
This paper describes the cascaded multimodal speech translation systems developed by Imperial College London for the IWSLT 2019 evaluation campaign. The architecture consists of an automatic speech recognition (ASR) system followed by a Transformer-based multimodal machine translation (MMT) system. While the ASR component is identical across the experiments, the MMT model varies in terms of the way of integrating the visual context (simple conditioning vs. attention), the type of visual features exploited (pooled, convolutional, action categories) and the underlying architecture. For the latter, we explore both the canonical transformer and its deliberation version with additive and cascade variants which differ in how they integrate the textual attention. Upon conducting extensive experiments, we found that (i) the explored visual integration schemes often harm the translation performance for the transformer and additive deliberation, but considerably improve the cascade deliberation; (ii) the transformer and cascade deliberation integrate the visual modality better than the additive deliberation, as shown by the incongruence analysis.
Imperial College London Submission to VATEX Video Captioning Task
Oct 16, 2019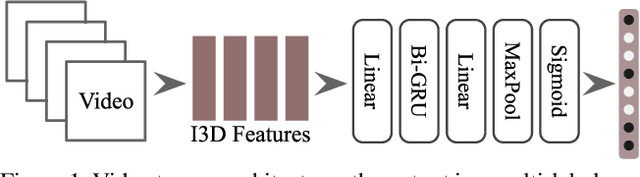
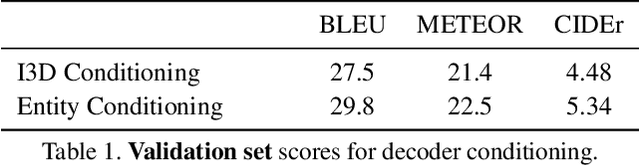
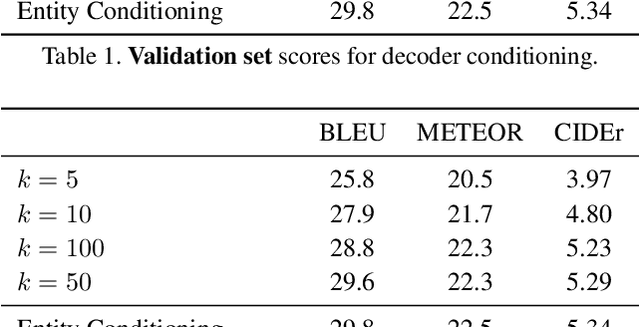

This paper describes the Imperial College London team's submission to the 2019' VATEX video captioning challenge, where we first explore two sequence-to-sequence models, namely a recurrent (GRU) model and a transformer model, which generate captions from the I3D action features. We then investigate the effect of dropping the encoder and the attention mechanism and instead conditioning the GRU decoder over two different vectorial representations: (i) a max-pooled action feature vector and (ii) the output of a multi-label classifier trained to predict visual entities from the action features. Our baselines achieved scores comparable to the official baseline. Conditioning over entity predictions performed substantially better than conditioning on the max-pooled feature vector, and only marginally worse than the GRU-based sequence-to-sequence baseline.
Predicting Actions to Help Predict Translations
Aug 18, 2019



We address the task of text translation on the How2 dataset using a state of the art transformer-based multimodal approach. The question we ask ourselves is whether visual features can support the translation process, in particular, given that this is a dataset extracted from videos, we focus on the translation of actions, which we believe are poorly captured in current static image-text datasets currently used for multimodal translation. For that purpose, we extract different types of action features from the videos and carefully investigate how helpful this visual information is by testing whether it can increase translation quality when used in conjunction with (i) the original text and (ii) the original text where action-related words (or all verbs) are masked out. The latter is a simulation that helps us assess the utility of the image in cases where the text does not provide enough context about the action, or in the presence of noise in the input text.