 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperial College London Submission to VATEX Video Captioning Task
Paper and Code
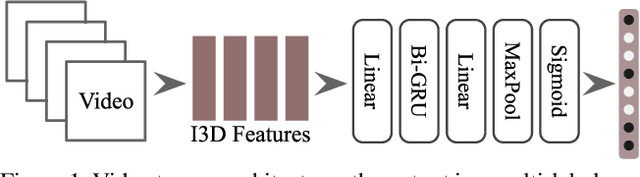
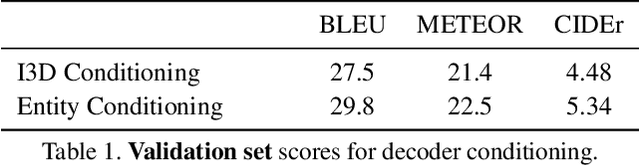
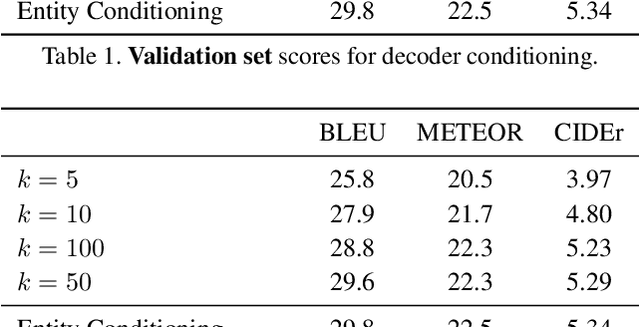

This paper describes the Imperial College London team's submission to the 2019' VATEX video captioning challenge, where we first explore two sequence-to-sequence models, namely a recurrent (GRU) model and a transformer model, which generate captions from the I3D action features. We then investigate the effect of dropping the encoder and the attention mechanism and instead conditioning the GRU decoder over two different vectorial representations: (i) a max-pooled action feature vector and (ii) the output of a multi-label classifier trained to predict visual entities from the action features. Our baselines achieved scores comparable to the official baseline. Conditioning over entity predictions performed substantially better than conditioning on the max-pooled feature vector, and only marginally worse than the GRU-based sequence-to-sequence baseline.