 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cognitively Grounded Bayesian Framework for Misinformation Susceptibility
May 10, 2026In this (work in progress) paper, we present Bounded Pragmatic Listener (or BPL), a cognitively grounded Bayesian framework for modelling susceptibility to information disorder. BPL extends Rational Speech Act theory with three cognitively motivated bounds derived from the bounded rationality literature with a) a recursion depth bound (that emphasises working memory limits);b) a prior compression parameter (which is oriented at capturing information bottleneck); and c) an availability sample size (that operationalises importance sampling with saliency-weighted proposals). This allows us to test predictions about misinformation susceptibility, annotator disagreement, and the differential vulnerability to mis-, dis-, and mal-information as defined in the Information Disorder framework. We validate BPL on the LIAR and MultiFC benchmarks showcasing competitive veracity classification and experimental support for the depth-mismatch paradox.
Working Memory Constraints Scaffold Learning in Transformers under Data Scarcity
Apr 22, 2026We investigate the integration of human-like working memory constraints into the Transformer architecture and implement several cognitively inspired attention variants, including fixed-width windows based and temporal decay based attention mechanisms. Our modified GPT-2 models are trained from scratch on developmentally plausible datasets (10M and 100M words). Performance is evaluated on grammatical judgment tasks (BLiMP) and alignment with human reading time data. Our results indicate that these cognitively-inspired constraints, particularly fixed-width attention, can significantly improve grammatical accuracy especially when training data is scarce. These constrained models also tend to show a stronger alignment with human processing metrics. The findings suggest that such constraints may serve as a beneficial inductive bias, guiding models towards more robust linguistic representations, especially in data-limited settings.
Learning and Enforcing Context-Sensitive Control for LLMs
Apr 12, 2026Controlling the output of Large Language Models (LLMs) through context-sensitive constraints has emerged as a promising approach to overcome the limitations of Context-Free Grammars (CFGs) in guaranteeing generation validity. However, such constraints typically require manual specification -- a significant barrier demanding specialized expertise. We introduce a framework that automatically learns context-sensitive constraints from LLM interactions through a two-phase process: syntactic exploration to gather diverse outputs for constraint learning, followed by constraint exploitation to enforce these learned rules during generation. Experiments demonstrate that our method enables even small LLMs (1B parameters) to learn and generate with perfect constraint adherence, outperforming larger counterparts and state-of-the-art reasoning models. This work represents the first integration of context-sensitive grammar learning with LLM generation, eliminating manual specification while maintaining generation validity.
* ACL 2025 Student Research Workshop
Noise or Nuance: An Investigation Into Useful Information and Filtering For LLM Driven AKBC
Sep 10, 2025RAG and fine-tuning are prevalent strategies for improving the quality of LLM outputs. However, in constrained situations, such as that of the 2025 LM-KBC challenge, such techniques are restricted. In this work we investigate three facets of the triple completion task: generation, quality assurance, and LLM response parsing. Our work finds that in this constrained setting: additional information improves generation quality, LLMs can be effective at filtering poor quality triples, and the tradeoff between flexibility and consistency with LLM response parsing is setting dependent.
Chart Question Answering from Real-World Analytical Narratives
Jul 02, 2025We present a new dataset for chart question answering (CQA) constructed from visualization notebooks. The dataset features real-world, multi-view charts paired with natural language questions grounded in analytical narratives. Unlike prior benchmarks, our data reflects ecologically valid reasoning workflows. Benchmarking state-of-the-art multimodal large language models reveals a significant performance gap, with GPT-4.1 achieving an accuracy of 69.3%, underscoring the challenges posed by this more authentic CQA setting.
IYKYK: Using language models to decode extremist cryptolects
Jun 05, 2025Extremist groups develop complex in-group language, also referred to as cryptolects, to exclude or mislead outsiders. We investigate the ability of current language technologies to detect and interpret the cryptolects of two online extremist platforms. Evaluating eight models across six tasks, our results indicate that general purpose LLMs cannot consistently detect or decode extremist language. However, performance can be significantly improved by domain adaptation and specialised prompting techniques. These results provide important insights to inform the development and deployment of automated moderation technologies. We further develop and release novel labelled and unlabelled datasets, including 19.4M posts from extremist platforms and lexicons validated by human experts.
An Empirical Study of Conformal Prediction in LLM with ASP Scaffolds for Robust Reasoning
Mar 07, 2025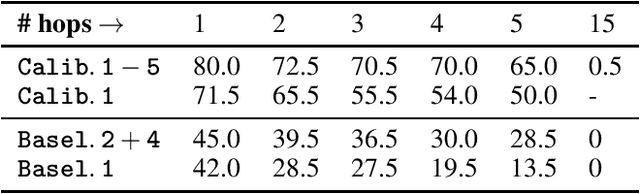

In this paper, we examine the use of Conformal Language Modelling (CLM) alongside Answer Set Programming (ASP) to enhance the performance of standard open-weight LLMs on complex multi-step reasoning tasks. Using the StepGame dataset, which requires spatial reasoning, we apply CLM to generate sets of ASP programs from an LLM, providing statistical guarantees on the correctness of the outputs. Experimental results show that CLM significantly outperforms baseline models that use standard sampling methods, achieving substantial accuracy improvements across different levels of reasoning complexity. Additionally, the LLM-as-Judge metric enhances CLM's performance, especially in assessing structurally and logically correct ASP outputs. However, calibrating CLM with diverse calibration sets did not improve generalizability for tasks requiring much longer reasoning steps, indicating limitations in handling more complex tasks.
$\texttt{SEM-CTRL}$: Semantically Controlled Decoding
Mar 03, 2025Ensuring both syntactic and semantic correctness in Large Language Model (LLM) outputs remains a significant challenge, despite being critical for real-world deployment. In this paper, we introduce $\texttt{SEM-CTRL}$, a unified approach that enforces rich context-sensitive constraints and task- and instance-specific semantics directly on an LLM decoder. Our approach integrates token-level MCTS, which is guided by specific syntactic and semantic constraints. The constraints over the desired outputs are expressed using Answer Set Grammars -- a logic-based formalism that generalizes context-sensitive grammars while incorporating background knowledge to represent task-specific semantics. We show that our approach guarantees correct completions for any off-the-shelf LLM without the need for fine-tuning. We evaluate $\texttt{SEM-CTRL}$ on a range of tasks, including synthetic grammar synthesis, combinatorial reasoning, and planning. Our results demonstrate that $\texttt{SEM-CTRL}$ allows small pre-trained LLMs to efficiently outperform larger variants and state-of-the-art reasoning models (e.g., o1-preview) while simultaneously guaranteeing solution correctness.
LLM-Assisted Visual Analytics: Opportunities and Challenges
Sep 04, 2024We explore the integration of large language models (LLMs) into visual analytics (VA) systems to transform their capabilities through intuitive natural language interactions. We survey current research directions in this emerging field, examining how LLMs are integrated into data management, language interaction, visualisation generation, and language generation processes. We highlight the new possibilities that LLMs bring to VA, especially how they can change VA processes beyond the usual use cases. We especially highlight building new visualisation-language models, allowing access of a breadth of domain knowledge, multimodal interaction, and opportunities with guidance. Finally, we carefully consider the prominent challenges of using current LLMs in VA tasks. Our discussions in this paper aim to guide future researchers working on LLM-assisted VA systems and help them navigate common obstacles when developing these systems.
Are words equally surprising in audio and audio-visual comprehension?
Jul 14, 2023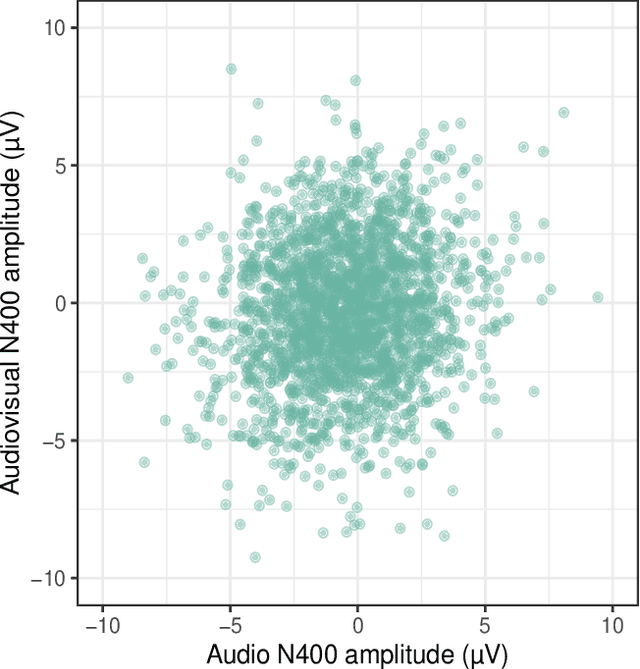
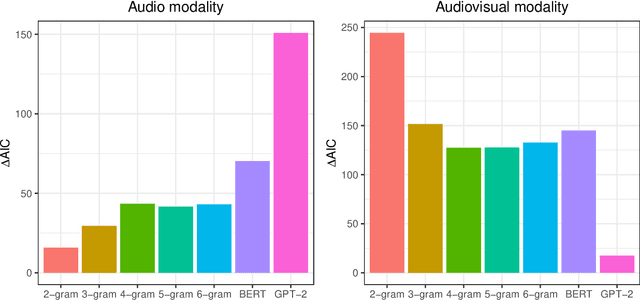
We report a controlled study investigating the effect of visual information (i.e., seeing the speaker) on spoken language comprehension. We compare the ERP signature (N400) associated with each word in audio-only and audio-visual presentations of the same verbal stimuli. We assess the extent to which surprisal measures (which quantify the predictability of words in their lexical context) are generated on the basis of different types of language models (specifically n-gram and Transformer models) that predict N400 responses for each word. Our results indicate that cognitive effort differs significantly between multimodal and unimodal settings. In addition, our findings suggest that while Transformer-based models, which have access to a larger lexical context, provide a better fit in the audio-only setting, 2-gram language models are more effective in the multimodal setting. This highlights the significant impact of local lexical context on cognitive processing in a multimodal environment.