 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Long-Term Generalization of Counting Behavior in RNNs
Paper and Code

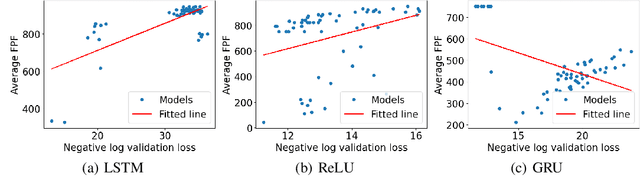

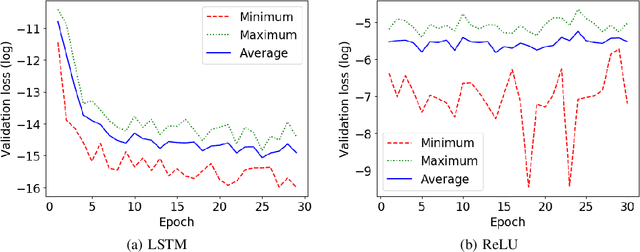
In this study, we investigate the generalization of LSTM, ReLU and GRU models on counting tasks over long sequences. Previous theoretical work has established that RNNs with ReLU activation and LSTMs have the capacity for counting with suitable configuration, while GRUs have limitations that prevent correct counting over longer sequences. Despite this and some positive empirical results for LSTMs on Dyck-1 languages, our experimental results show that LSTMs fail to learn correct counting behavior for sequences that are significantly longer than in the training data. ReLUs show much larger variance in behavior and in most cases worse generalization. The long sequence generalization is empirically related to validation loss, but reliable long sequence generalization seems not practically achievable through backpropagation with current techniques. We demonstrate different failure modes for LSTMs, GRUs and ReLUs. In particular, we observe that the saturation of activation functions in LSTMs and the correct weight setting for ReLUs to generalize counting behavior are not achieved in standard training regimens. In summary, learning generalizable counting behavior is still an open problem and we discuss potential approaches for further research.