 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Word Orders Facilitate Length Generalization in LMs? An Investigation with GCG-Based Artificial Languages
Oct 14, 2025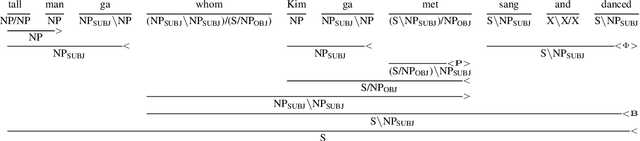


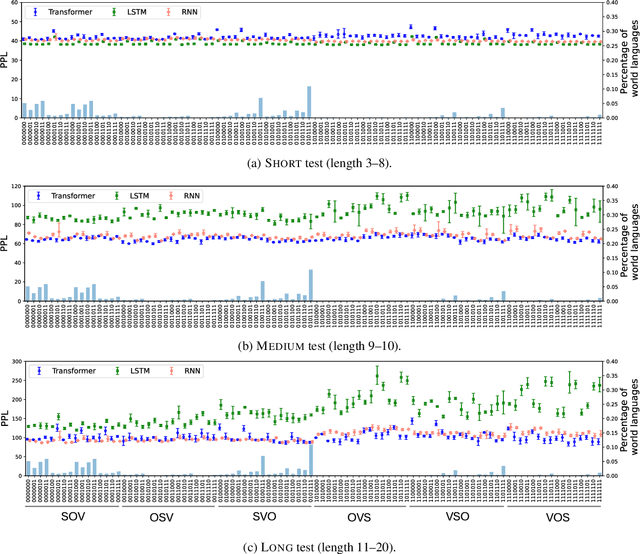
Whether language models (LMs) have inductive biases that favor typologically frequent grammatical properties over rare, implausible ones has been investigated, typically using artificial languages (ALs) (White and Cotterell, 2021; Kuribayashi et al., 2024). In this paper, we extend these works from two perspectives. First, we extend their context-free AL formalization by adopting Generalized Categorial Grammar (GCG) (Wood, 2014), which allows ALs to cover attested but previously overlooked constructions, such as unbounded dependency and mildly context-sensitive structures. Second, our evaluation focuses more on the generalization ability of LMs to process unseen longer test sentences. Thus, our ALs better capture features of natural languages and our experimental paradigm leads to clearer conclusions -- typologically plausible word orders tend to be easier for LMs to productively generalize.
Theoretical Conditions and Empirical Failure of Bracket Counting on Long Sequences with Linear Recurrent Networks
Apr 07, 2023


Previous work has established that RNNs with an unbounded activation function have the capacity to count exactly. However, it has also been shown that RNNs are challenging to train effectively and generally do not learn exact counting behaviour. In this paper, we focus on this problem by studying the simplest possible RNN, a linear single-cell network. We conduct a theoretical analysis of linear RNNs and identify conditions for the models to exhibit exact counting behaviour. We provide a formal proof that these conditions are necessary and sufficient. We also conduct an empirical analysis using tasks involving a Dyck-1-like Balanced Bracket language under two different settings. We observe that linear RNNs generally do not meet the necessary and sufficient conditions for counting behaviour when trained with the standard approach. We investigate how varying the length of training sequences and utilising different target classes impacts model behaviour during training and the ability of linear RNN models to effectively approximate the indicator conditions.
Exploring the Long-Term Generalization of Counting Behavior in RNNs
Nov 29, 2022
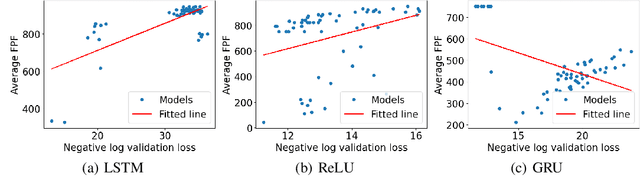

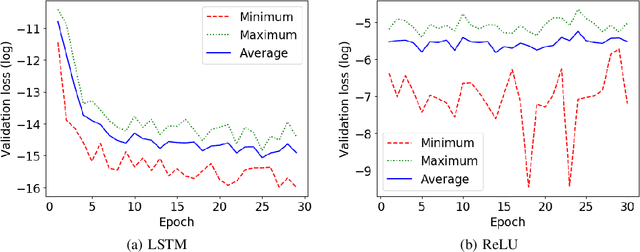
In this study, we investigate the generalization of LSTM, ReLU and GRU models on counting tasks over long sequences. Previous theoretical work has established that RNNs with ReLU activation and LSTMs have the capacity for counting with suitable configuration, while GRUs have limitations that prevent correct counting over longer sequences. Despite this and some positive empirical results for LSTMs on Dyck-1 languages, our experimental results show that LSTMs fail to learn correct counting behavior for sequences that are significantly longer than in the training data. ReLUs show much larger variance in behavior and in most cases worse generalization. The long sequence generalization is empirically related to validation loss, but reliable long sequence generalization seems not practically achievable through backpropagation with current techniques. We demonstrate different failure modes for LSTMs, GRUs and ReLUs. In particular, we observe that the saturation of activation functions in LSTMs and the correct weight setting for ReLUs to generalize counting behavior are not achieved in standard training regimens. In summary, learning generalizable counting behavior is still an open problem and we discuss potential approaches for further research.