 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-CRAFT: Knowledge Graph-based Contrastive Reasoning with LLMs for Enhancing Automated Fact-checking
Jan 27, 2026Claim verification is a core component of automated fact-checking systems, aimed at determining the truthfulness of a statement by assessing it against reliable evidence sources such as documents or knowledge bases. This work presents KG-CRAFT, a method that improves automatic claim verification by leveraging large language models (LLMs) augmented with contrastive questions grounded in a knowledge graph. KG-CRAFT first constructs a knowledge graph from claims and associated reports, then formulates contextually relevant contrastive questions based on the knowledge graph structure. These questions guide the distillation of evidence-based reports, which are synthesised into a concise summary that is used for veracity assessment by LLMs. Extensive evaluations on two real-world datasets (LIAR-RAW and RAWFC) demonstrate that our method achieves a new state-of-the-art in predictive performance. Comprehensive analyses validate in detail the effectiveness of our knowledge graph-based contrastive reasoning approach in improving LLMs' fact-checking capabilities.
Disentangling concept semantics via multilingual averaging in Sparse Autoencoders
Aug 19, 2025Connecting LLMs with formal knowledge representation and reasoning is a promising approach to address their shortcomings. Embeddings and sparse autoencoders are widely used to represent textual content, but the semantics are entangled with syntactic and language-specific information. We propose a method that isolates concept semantics in Large Langue Models by averaging concept activations derived via Sparse Autoencoders. We create English text representations from OWL ontology classes, translate the English into French and Chinese and then pass these texts as prompts to the Gemma 2B LLM. Using the open source Gemma Scope suite of Sparse Autoencoders, we obtain concept activations for each class and language version. We average the different language activations to derive a conceptual average. We then correlate the conceptual averages with a ground truth mapping between ontology classes. Our results give a strong indication that the conceptual average aligns to the true relationship between classes when compared with a single language by itself. The result hints at a new technique which enables mechanistic interpretation of internal network states with higher accuracy.
Wavelet-Filtering of Symbolic Music Representations for Folk Tune Segmentation and Classification
Apr 29, 2025The aim of this study is to evaluate a machine-learning method in which symbolic representations of folk songs are segmented and classified into tune families with Haar-wavelet filtering. The method is compared with previously proposed Gestalt-based method. Melodies are represented as discrete symbolic pitch-time signals. We apply the continuous wavelet transform (CWT) with the Haar wavelet at specific scales, obtaining filtered versions of melodies emphasizing their information at particular time-scales. We use the filtered signal for representation and segmentation, using the wavelet coefficients' local maxima to indicate local boundaries and classify segments by means of k-nearest neighbours based on standard vector-metrics (Euclidean, cityblock), and compare the results to a Gestalt-based segmentation method and metrics applied directly to the pitch signal. We found that the wavelet based segmentation and wavelet-filtering of the pitch signal lead to better classification accuracy in cross-validated evaluation when the time-scale and other parameters are optimized.
An approach to melodic segmentation and classification based on filtering with the Haar-wavelet
Apr 29, 2025We present a novel method of classification and segmentation of melodies in symbolic representation. The method is based on filtering pitch as a signal over time with the Haar-wavelet, and we evaluate it on two tasks. The filtered signal corresponds to a single-scale signal ws from the continuous Haar wavelet transform. The melodies are first segmented using local maxima or zero-crossings of w_s. The segments of w_s are then classified using the k-nearest neighbour algorithm with Euclidian and city-block distances. The method proves more effective than using unfiltered pitch signals and Gestalt-based segmentation when used to recognize the parent works of segments from Bach's Two-Part Inventions (BWV 772-786). When used to classify 360 Dutch folk tunes into 26 tune families, the performance of the method is comparable to the use of pitch signals, but not as good as that of string-matching methods based on multiple features.
OWL2Vec4OA: Tailoring Knowledge Graph Embeddings for Ontology Alignment
Aug 12, 2024



Ontology alignment is integral to achieving semantic interoperability as the number of available ontologies covering intersecting domains is increasing. This paper proposes OWL2Vec4OA, an extension of the ontology embedding system OWL2Vec*. While OWL2Vec* has emerged as a powerful technique for ontology embedding, it currently lacks a mechanism to tailor the embedding to the ontology alignment task. OWL2Vec4OA incorporates edge confidence values from seed mappings to guide the random walk strategy. We present the theoretical foundations, implementation details, and experimental evaluation of our proposed extension, demonstrating its potential effectiveness for ontology alignment tasks.
When to Accept Automated Predictions and When to Defer to Human Judgment?
Jul 10, 2024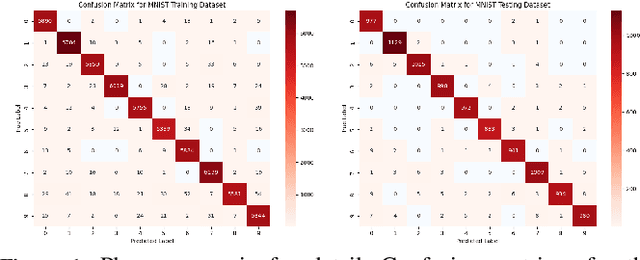
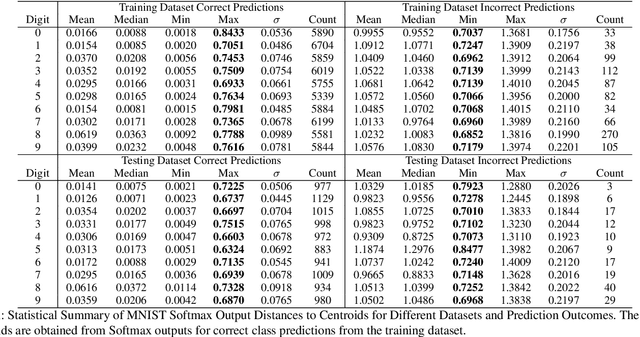
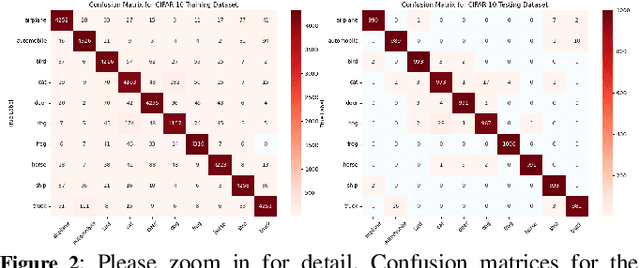
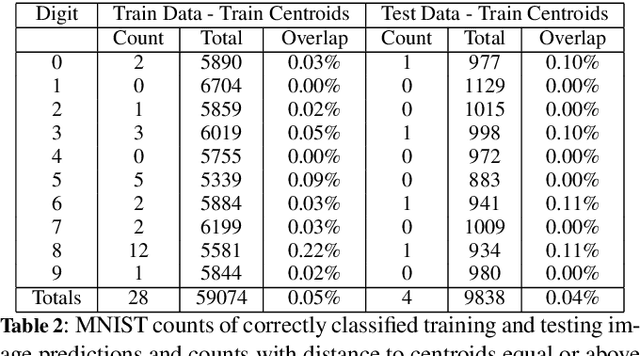
Ensuring the reliability and safety of automated decision-making is crucial. It is well-known that data distribution shifts in machine learning can produce unreliable outcomes. This paper proposes a new approach for measuring the reliability of predictions under distribution shifts. We analyze how the outputs of a trained neural network change using clustering to measure distances between outputs and class centroids. We propose this distance as a metric to evaluate the confidence of predictions under distribution shifts. We assign each prediction to a cluster with centroid representing the mean softmax output for all correct predictions of a given class. We then define a safety threshold for a class as the smallest distance from an incorrect prediction to the given class centroid. We evaluate the approach on the MNIST and CIFAR-10 datasets using a Convolutional Neural Network and a Vision Transformer, respectively. The results show that our approach is consistent across these data sets and network models, and indicate that the proposed metric can offer an efficient way of determining when automated predictions are acceptable and when they should be deferred to human operators given a distribution shift.
The Misclassification Likelihood Matrix: Some Classes Are More Likely To Be Misclassified Than Others
Jul 10, 2024



This study introduces the Misclassification Likelihood Matrix (MLM) as a novel tool for quantifying the reliability of neural network predictions under distribution shifts. The MLM is obtained by leveraging softmax outputs and clustering techniques to measure the distances between the predictions of a trained neural network and class centroids. By analyzing these distances, the MLM provides a comprehensive view of the model's misclassification tendencies, enabling decision-makers to identify the most common and critical sources of errors. The MLM allows for the prioritization of model improvements and the establishment of decision thresholds based on acceptable risk levels. The approach is evaluated on the MNIST dataset using a Convolutional Neural Network (CNN) and a perturbed version of the dataset to simulate distribution shifts. The results demonstrate the effectiveness of the MLM in assessing the reliability of predictions and highlight its potential in enhancing the interpretability and risk mitigation capabilities of neural networks. The implications of this work extend beyond image classification, with ongoing applications in autonomous systems, such as self-driving cars, to improve the safety and reliability of decision-making in complex, real-world environments.
Derivative-based regularization for regression
May 01, 2024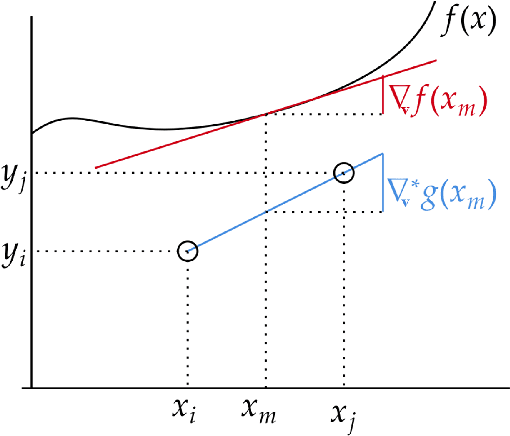
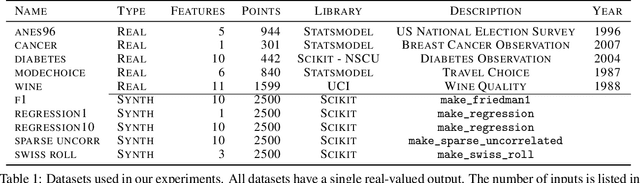
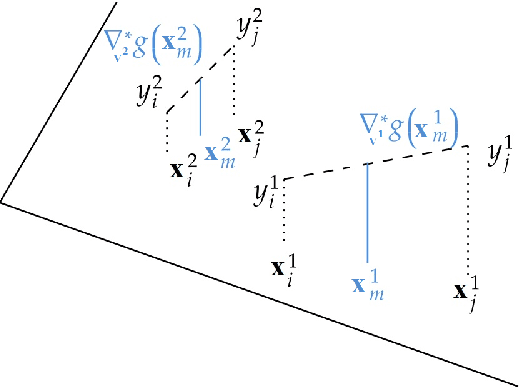

In this work, we introduce a novel approach to regularization in multivariable regression problems. Our regularizer, called DLoss, penalises differences between the model's derivatives and derivatives of the data generating function as estimated from the training data. We call these estimated derivatives data derivatives. The goal of our method is to align the model to the data, not only in terms of target values but also in terms of the derivatives involved. To estimate data derivatives, we select (from the training data) 2-tuples of input-value pairs, using either nearest neighbour or random, selection. On synthetic and real datasets, we evaluate the effectiveness of adding DLoss, with different weights, to the standard mean squared error loss. The experimental results show that with DLoss (using nearest neighbour selection) we obtain, on average, the best rank with respect to MSE on validation data sets, compared to no regularization, L2 regularization, and Dropout.
Improved Data Generation for Enhanced Asset Allocation: A Synthetic Dataset Approach for the Fixed Income Universe
Nov 27, 2023



We present a novel process for generating synthetic datasets tailored to assess asset allocation methods and construct portfolios within the fixed income universe. Our approach begins by enhancing the CorrGAN model to generate synthetic correlation matrices. Subsequently, we propose an Encoder-Decoder model that samples additional data conditioned on a given correlation matrix. The resulting synthetic dataset facilitates in-depth analyses of asset allocation methods across diverse asset universes. Additionally, we provide a case study that exemplifies the use of the synthetic dataset to improve portfolios constructed within a simulation-based asset allocation process.
NeSy4VRD: A Multifaceted Resource for Neurosymbolic AI Research using Knowledge Graphs in Visual Relationship Detection
May 22, 2023NeSy4VRD is a multifaceted resource designed to support the development of neurosymbolic AI (NeSy) research. NeSy4VRD re-establishes public access to the images of the VRD dataset and couples them with an extensively revised, quality-improved version of the VRD visual relationship annotations. Crucially, NeSy4VRD provides a well-aligned, companion OWL ontology that describes the dataset domain.It comes with open source infrastructure that provides comprehensive support for extensibility of the annotations (which, in turn, facilitates extensibility of the ontology), and open source code for loading the annotations to/from a knowledge graph. We are contributing NeSy4VRD to the computer vision, NeSy and Semantic Web communities to help foster more NeSy research using OWL-based knowledge graphs.