 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Comparisons of Reinforcement Learning Algorithms for Sequential Experimental Design
Mar 07, 2025


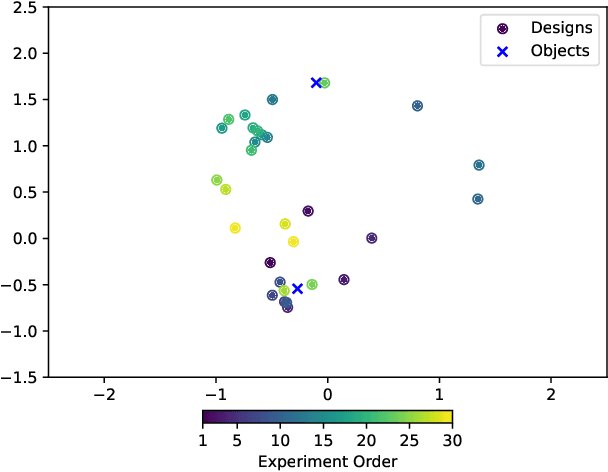
Recent developments in sequential experimental design look to construct a policy that can efficiently navigate the design space, in a way that maximises the expected information gain. Whilst there is work on achieving tractable policies for experimental design problems, there is significantly less work on obtaining policies that are able to generalise well - i.e. able to give good performance despite a change in the underlying statistical properties of the experiments. Conducting experiments sequentially has recently brought about the use of reinforcement learning, where an agent is trained to navigate the design space to select the most informative designs for experimentation. However, there is still a lack of understanding about the benefits and drawbacks of using certain reinforcement learning algorithms to train these agents. In our work, we investigate several reinforcement learning algorithms and their efficacy in producing agents that take maximally informative design decisions in sequential experimental design scenarios. We find that agent performance is impacted depending on the algorithm used for training, and that particular algorithms, using dropout or ensemble approaches, empirically showcase attractive generalisation properties.
Derivative-based regularization for regression
May 01, 2024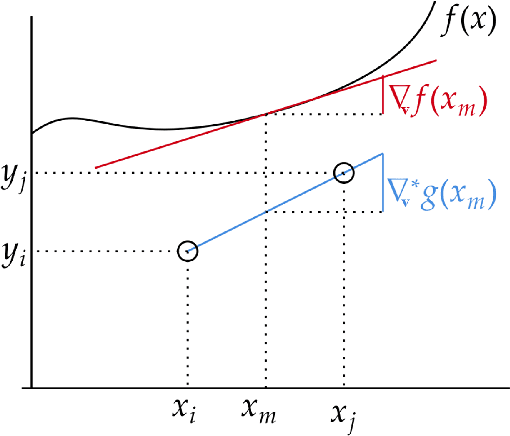
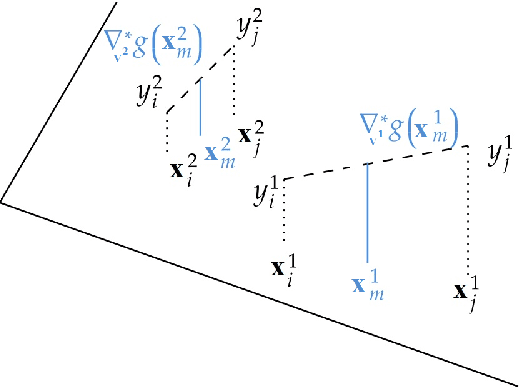

In this work, we introduce a novel approach to regularization in multivariable regression problems. Our regularizer, called DLoss, penalises differences between the model's derivatives and derivatives of the data generating function as estimated from the training data. We call these estimated derivatives data derivatives. The goal of our method is to align the model to the data, not only in terms of target values but also in terms of the derivatives involved. To estimate data derivatives, we select (from the training data) 2-tuples of input-value pairs, using either nearest neighbour or random, selection. On synthetic and real datasets, we evaluate the effectiveness of adding DLoss, with different weights, to the standard mean squared error loss. The experimental results show that with DLoss (using nearest neighbour selection) we obtain, on average, the best rank with respect to MSE on validation data sets, compared to no regularization, L2 regularization, and Dropout.
Assessing Safety-Critical Systems from Operational Testing: A Study on Autonomous Vehicles
Aug 19, 2020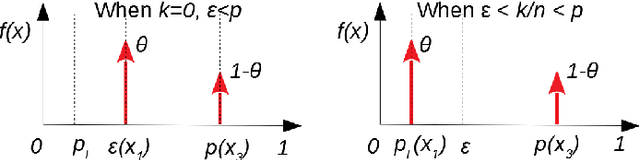

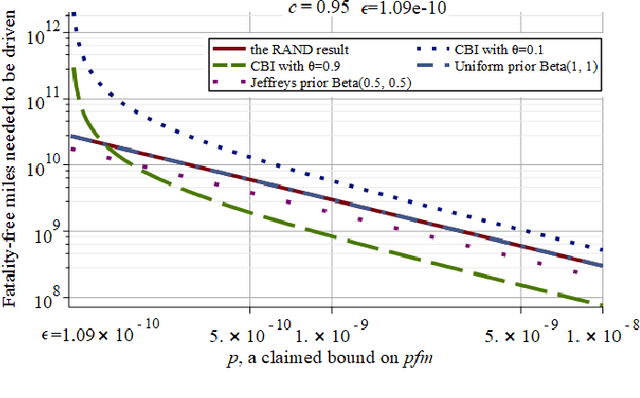
Context: Demonstrating high reliability and safety for safety-critical systems (SCSs) remains a hard problem. Diverse evidence needs to be combined in a rigorous way: in particular, results of operational testing with other evidence from design and verification. Growing use of machine learning in SCSs, by precluding most established methods for gaining assurance, makes operational testing even more important for supporting safety and reliability claims. Objective: We use Autonomous Vehicles (AVs) as a current example to revisit the problem of demonstrating high reliability. AVs are making their debut on public roads: methods for assessing whether an AV is safe enough are urgently needed. We demonstrate how to answer 5 questions that would arise in assessing an AV type, starting with those proposed by a highly-cited study. Method: We apply new theorems extending Conservative Bayesian Inference (CBI), which exploit the rigour of Bayesian methods while reducing the risk of involuntary misuse associated with now-common applications of Bayesian inference; we define additional conditions needed for applying these methods to AVs. Results: Prior knowledge can bring substantial advantages if the AV design allows strong expectations of safety before road testing. We also show how naive attempts at conservative assessment may lead to over-optimism instead; why extrapolating the trend of disengagements is not suitable for safety claims; use of knowledge that an AV has moved to a less stressful environment. Conclusion: While some reliability targets will remain too high to be practically verifiable, CBI removes a major source of doubt: it allows use of prior knowledge without inducing dangerously optimistic biases. For certain ranges of required reliability and prior beliefs, CBI thus supports feasible, sound arguments. Useful conservative claims can be derived from limited prior knowledge.
Assessing the Safety and Reliability of Autonomous Vehicles from Road Testing
Aug 19, 2019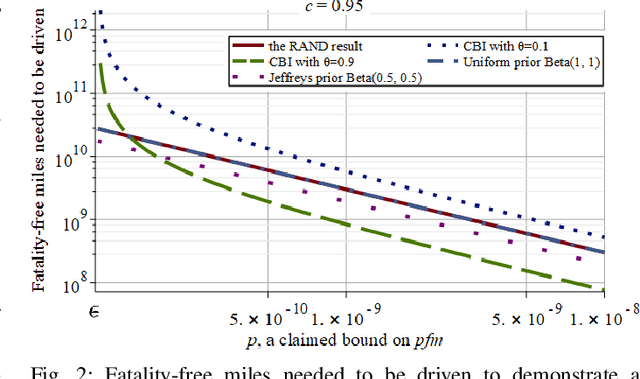
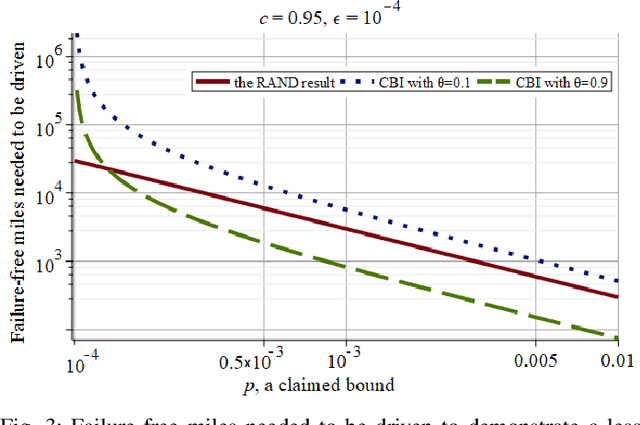
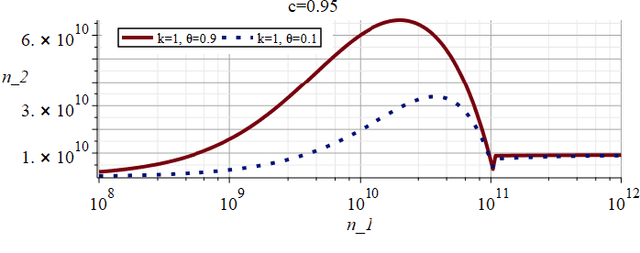
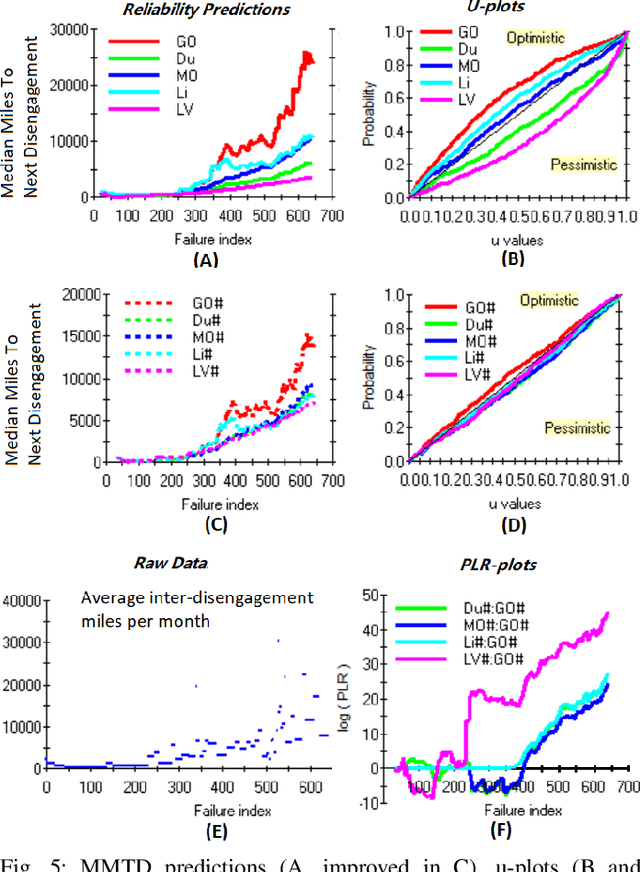
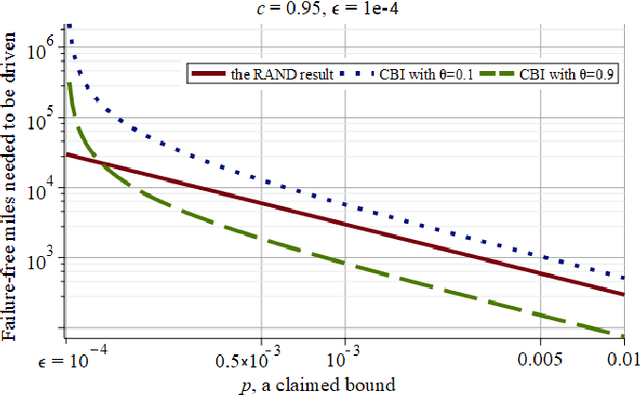
There is an urgent societal need to assess whether autonomous vehicles (AVs) are safe enough. From published quantitative safety and reliability assessments of AVs, we know that, given the goal of predicting very low rates of accidents, road testing alone requires infeasible numbers of miles to be driven. However, previous analyses do not consider any knowledge prior to road testing - knowledge which could bring substantial advantages if the AV design allows strong expectations of safety before road testing. We present the advantages of a new variant of Conservative Bayesian Inference (CBI), which uses prior knowledge while avoiding optimistic biases. We then study the trend of disengagements (take-overs by human drivers) by applying Software Reliability Growth Models (SRGMs) to data from Waymo's public road testing over 51 months, in view of the practice of software updates during this testing. Our approach is to not trust any specific SRGM, but to assess forecast accuracy and then improve forecasts. We show that, coupled with accuracy assessment and recalibration techniques, SRGMs could be a valuable test planning aid.