 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Feb 04, 2026Recently, rubrics have been used to guide LLM judges in capturing subjective, nuanced, multi-dimensional human preferences, and have been extended from evaluation to reward signals for reinforcement fine-tuning (RFT). However, rubric generation remains hard to control: rubrics often lack coverage, conflate dimensions, misalign preference direction, and contain redundant or highly correlated criteria, degrading judge accuracy and producing suboptimal rewards during RFT. We propose RRD, a principled framework for rubric refinement built on a recursive decompose-filter cycle. RRD decomposes coarse rubrics into fine-grained, discriminative criteria, expanding coverage while sharpening separation between responses. A complementary filtering mechanism removes misaligned and redundant rubrics, and a correlation-aware weighting scheme prevents over-representing highly correlated criteria, yielding rubric sets that are informative, comprehensive, and non-redundant. Empirically, RRD delivers large, consistent gains across both evaluation and training: it improves preference-judgment accuracy on JudgeBench and PPE for both GPT-4o and Llama3.1-405B judges, achieving top performance in all settings with up to +17.7 points on JudgeBench. When used as the reward source for RFT on WildChat, it yields substantially stronger and more stable learning signals, boosting reward by up to 160% (Qwen3-4B) and 60% (Llama3.1-8B) versus 10-20% for prior rubric baselines, with gains that transfer to HealthBench-Hard and BiGGen Bench. Overall, RRD establishes recursive rubric refinement as a scalable and interpretable foundation for LLM judging and reward modeling in open-ended domains.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
Calibrating LLM Judges: Linear Probes for Fast and Reliable Uncertainty Estimation
Dec 23, 2025As LLM-based judges become integral to industry applications, obtaining well-calibrated uncertainty estimates efficiently has become critical for production deployment. However, existing techniques, such as verbalized confidence and multi-generation methods, are often either poorly calibrated or computationally expensive. We introduce linear probes trained with a Brier score-based loss to provide calibrated uncertainty estimates from reasoning judges' hidden states, requiring no additional model training. We evaluate our approach on both objective tasks (reasoning, mathematics, factuality, coding) and subjective human preference judgments. Our results demonstrate that probes achieve superior calibration compared to existing methods with $\approx10$x computational savings, generalize robustly to unseen evaluation domains, and deliver higher accuracy on high-confidence predictions. However, probes produce conservative estimates that underperform on easier datasets but may benefit safety-critical deployments prioritizing low false-positive rates. Overall, our work demonstrates that interpretability-based uncertainty estimation provides a practical and scalable plug-and-play solution for LLM judges in production.
MENLO: From Preferences to Proficiency -- Evaluating and Modeling Native-like Quality Across 47 Languages
Sep 30, 2025



Ensuring native-like quality of large language model (LLM) responses across many languages is challenging. To address this, we introduce MENLO, a framework that operationalizes the evaluation of native-like response quality based on audience design-inspired mechanisms. Using MENLO, we create a dataset of 6,423 human-annotated prompt-response preference pairs covering four quality dimensions with high inter-annotator agreement in 47 language varieties. Our evaluation reveals that zero-shot LLM judges benefit significantly from pairwise evaluation and our structured annotation rubrics, yet they still underperform human annotators on our dataset. We demonstrate substantial improvements through fine-tuning with reinforcement learning, reward shaping, and multi-task learning approaches. Additionally, we show that RL-trained judges can serve as generative reward models to enhance LLMs' multilingual proficiency, though discrepancies with human judgment remain. Our findings suggest promising directions for scalable multilingual evaluation and preference alignment. We release our dataset and evaluation framework to support further research in multilingual LLM evaluation.
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
May 15, 2025The progress of AI is bottlenecked by the quality of evaluation, and powerful LLM-as-a-Judge models have proved to be a core solution. Improved judgment ability is enabled by stronger chain-of-thought reasoning, motivating the need to find the best recipes for training such models to think. In this work we introduce J1, a reinforcement learning approach to training such models. Our method converts both verifiable and non-verifiable prompts to judgment tasks with verifiable rewards that incentivize thinking and mitigate judgment bias. In particular, our approach outperforms all other existing 8B or 70B models when trained at those sizes, including models distilled from DeepSeek-R1. J1 also outperforms o1-mini, and even R1 on some benchmarks, despite training a smaller model. We provide analysis and ablations comparing Pairwise-J1 vs Pointwise-J1 models, offline vs online training recipes, reward strategies, seed prompts, and variations in thought length and content. We find that our models make better judgments by learning to outline evaluation criteria, comparing against self-generated reference answers, and re-evaluating the correctness of model responses.
What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
Feb 12, 2025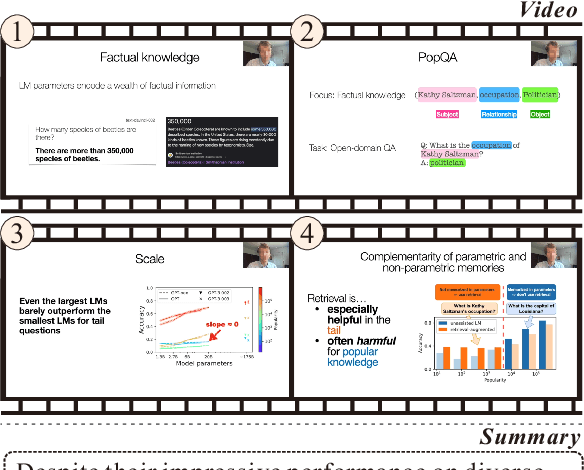
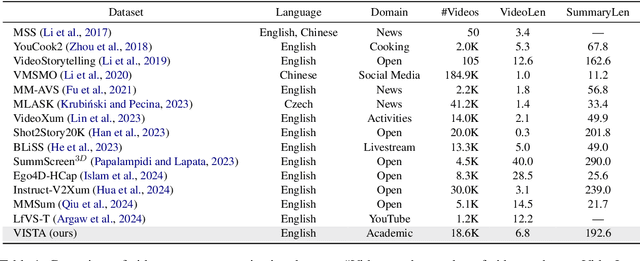

Transforming recorded videos into concise and accurate textual summaries is a growing challenge in multimodal learning. This paper introduces VISTA, a dataset specifically designed for video-to-text summarization in scientific domains. VISTA contains 18,599 recorded AI conference presentations paired with their corresponding paper abstracts. We benchmark the performance of state-of-the-art large models and apply a plan-based framework to better capture the structured nature of abstracts. Both human and automated evaluations confirm that explicit planning enhances summary quality and factual consistency. However, a considerable gap remains between models and human performance, highlighting the challenges of scientific video summarization.
Segment-Level Diffusion: A Framework for Controllable Long-Form Generation with Diffusion Language Models
Dec 15, 2024



Diffusion models have shown promise in text generation but often struggle with generating long, coherent, and contextually accurate text. Token-level diffusion overlooks word-order dependencies and enforces short output windows, while passage-level diffusion struggles with learning robust representation for long-form text. To address these challenges, we propose Segment-Level Diffusion (SLD), a framework that enhances diffusion-based text generation through text segmentation, robust representation training with adversarial and contrastive learning, and improved latent-space guidance. By segmenting long-form outputs into separate latent representations and decoding them with an autoregressive decoder, SLD simplifies diffusion predictions and improves scalability. Experiments on XSum, ROCStories, DialogSum, and DeliData demonstrate that SLD achieves competitive or superior performance in fluency, coherence, and contextual compatibility across automatic and human evaluation metrics comparing with other diffusion and autoregressive baselines. Ablation studies further validate the effectiveness of our segmentation and representation learning strategies.
The Automated Verification of Textual Claims (AVeriTeC) Shared Task
Oct 31, 2024



The Automated Verification of Textual Claims (AVeriTeC) shared task asks participants to retrieve evidence and predict veracity for real-world claims checked by fact-checkers. Evidence can be found either via a search engine, or via a knowledge store provided by the organisers. Submissions are evaluated using AVeriTeC score, which considers a claim to be accurately verified if and only if both the verdict is correct and retrieved evidence is considered to meet a certain quality threshold. The shared task received 21 submissions, 18 of which surpassed our baseline. The winning team was TUDA_MAI with an AVeriTeC score of 63%. In this paper we describe the shared task, present the full results, and highlight key takeaways from the shared task.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024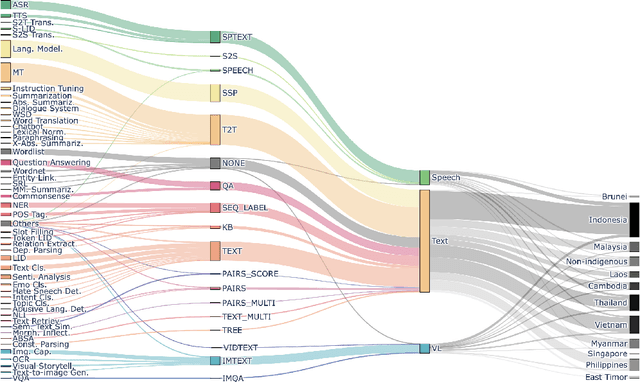
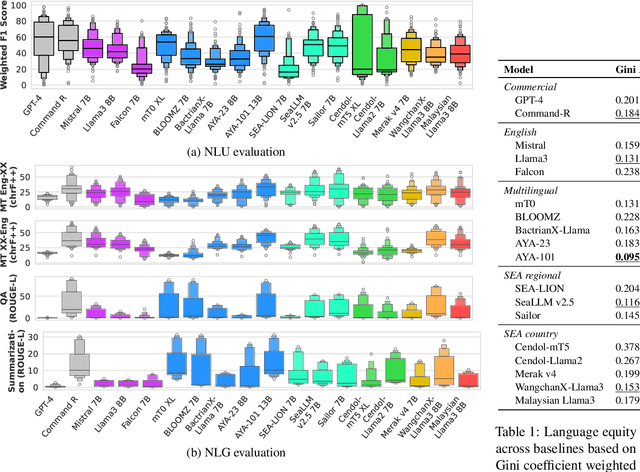
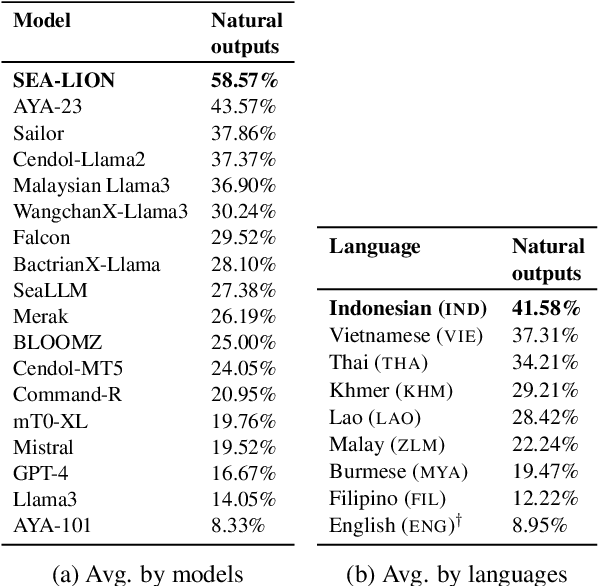
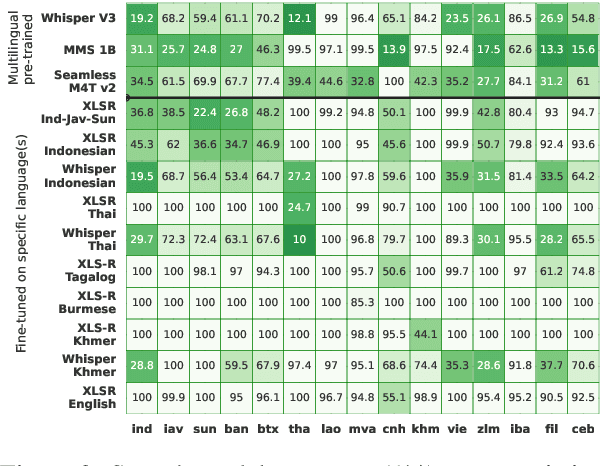
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.