 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Fast Should a Model Commit to Supervision? Training Reasoning Models on the Tsallis Loss Continuum
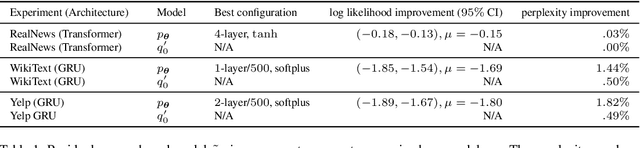
Apr 28, 2026Adapting reasoning models to new tasks during post-training with only output-level supervision stalls under reinforcement learning from verifiable rewards (RLVR) when the initial success probability $p_0$ is small. Using the Tsallis $q$-logarithm, we define a loss family $J_Q$ that interpolates between RLVR (at $q{=}0$, the exploitation pole) and the log-marginal-likelihood over latent trajectories (at $q{=}1$, the density-estimation pole). All members share the same per-example gradient direction, differing only by a scalar amplification $P_{θ^{-q}}$ that reweights each instance independently of the learning rate. This amplification is the mechanism that addresses cold-start stalling: under gradient flow, the exploitation pole requires $Ω(\frac{1}{p_0})$ time to escape cold start, while the density-estimation pole escapes in $Θ\big(\log(\frac{1}{p_0})\big)$; intermediate $q$ trades escape speed against noise memorization. Because $P_θ$ is intractable, we derive two Monte Carlo estimators from the two factorizations of the gradient: Gradient-Amplified RL (GARL) samples from the prior and amplifies the RL gradient, and Posterior-Attenuated Fine-Tuning (PAFT) importance-resamples from the posterior and runs standard SFT. Both have bias $O\big(\frac{q}{M P_θ^{q+1}}\big)$; GARL has lower variance, PAFT has semantically coherent gradients. On FinQA, HotPotQA, and MuSiQue, GARL at $q{=}0.75$ substantially mitigates cold-start stalling, escaping cold start where GRPO fails entirely. In warm start, GARL at low $q$ dominates FinQA where training is stable; on HotPotQA and MuSiQue, GARL destabilizes during training, and PAFT at $q{=}0.75$ provides stable gradients (best overall on HotPotQA at 47.9 maj@16, $+14.4$ over GRPO).
Type-Compliant Adaptation Cascades: Adapting Programmatic LM Workflows to Data
Aug 25, 2025Reliably composing Large Language Models (LLMs) for complex, multi-step workflows remains a significant challenge. The dominant paradigm-optimizing discrete prompts in a pipeline-is notoriously brittle and struggles to enforce the formal compliance required for structured tasks. We introduce Type-Compliant Adaptation Cascades (TACs), a framework that recasts workflow adaptation as learning typed probabilistic programs. TACs treats the entire workflow, which is composed of parameter-efficiently adapted LLMs and deterministic logic, as an unnormalized joint distribution. This enables principled, gradient-based training even with latent intermediate structures. We provide theoretical justification for our tractable optimization objective, proving that the optimization bias vanishes as the model learns type compliance. Empirically, TACs significantly outperforms state-of-the-art prompt-optimization baselines. Gains are particularly pronounced on structured tasks, improving MGSM-SymPy from $57.1\%$ to $75.9\%$ for a 27B model, MGSM from $1.6\%$ to $27.3\%$ for a 7B model. TACs offers a robust and theoretically grounded paradigm for developing reliable, task-compliant LLM systems.
Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection
May 25, 2024



Large language models (LLMs) augmented with retrieval exhibit robust performance and extensive versatility by incorporating external contexts. However, the input length grows linearly in the number of retrieved documents, causing a dramatic increase in latency. In this paper, we propose a novel paradigm named Sparse RAG, which seeks to cut computation costs through sparsity. Specifically, Sparse RAG encodes retrieved documents in parallel, which eliminates latency introduced by long-range attention of retrieved documents. Then, LLMs selectively decode the output by only attending to highly relevant caches auto-regressively, which are chosen via prompting LLMs with special control tokens. It is notable that Sparse RAG combines the assessment of each individual document and the generation of the response into a single process. The designed sparse mechanism in a RAG system can facilitate the reduction of the number of documents loaded during decoding for accelerating the inference of the RAG system. Additionally, filtering out undesirable contexts enhances the model's focus on relevant context, inherently improving its generation quality. Evaluation results of two datasets show that Sparse RAG can strike an optimal balance between generation quality and computational efficiency, demonstrating its generalizability across both short- and long-form generation tasks.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Multitask Multilingual Model Adaptation with Featurized Low-Rank Mixtures
Feb 27, 2024Adapting pretrained large language models (LLMs) to various downstream tasks in tens or hundreds of human languages is computationally expensive. Parameter-efficient fine-tuning (PEFT) significantly reduces the adaptation cost, by tuning only a small amount of parameters. However, directly applying PEFT methods such as LoRA (Hu et al., 2022) on diverse dataset mixtures could lead to suboptimal performance due to limited parameter capacity and negative interference among different datasets. In this work, we propose Featurized Low-rank Mixtures (FLix), a novel PEFT method designed for effective multitask multilingual tuning. FLix associates each unique dataset feature, such as the dataset's language or task, with its own low-rank weight update parameters. By composing feature-specific parameters for each dataset, FLix can accommodate diverse dataset mixtures and generalize better to unseen datasets. Our experiments show that FLix leads to significant improvements over a variety of tasks for both supervised learning and zero-shot settings using different training data mixtures.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
SiRA: Sparse Mixture of Low Rank Adaptation
Nov 15, 2023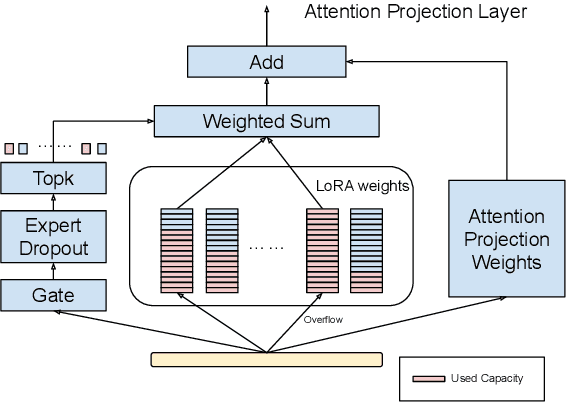



Parameter Efficient Tuning has been an prominent approach to adapt the Large Language Model to downstream tasks. Most previous works considers adding the dense trainable parameters, where all parameters are used to adapt certain task. We found this less effective empirically using the example of LoRA that introducing more trainable parameters does not help. Motivated by this we investigate the importance of leveraging "sparse" computation and propose SiRA: sparse mixture of low rank adaption. SiRA leverages the Sparse Mixture of Expert(SMoE) to boost the performance of LoRA. Specifically it enforces the top $k$ experts routing with a capacity limit restricting the maximum number of tokens each expert can process. We propose a novel and simple expert dropout on top of gating network to reduce the over-fitting issue. Through extensive experiments, we verify SiRA performs better than LoRA and other mixture of expert approaches across different single tasks and multitask settings.
Parameter-Efficient Multilingual Summarisation: An Empirical Study
Nov 14, 2023
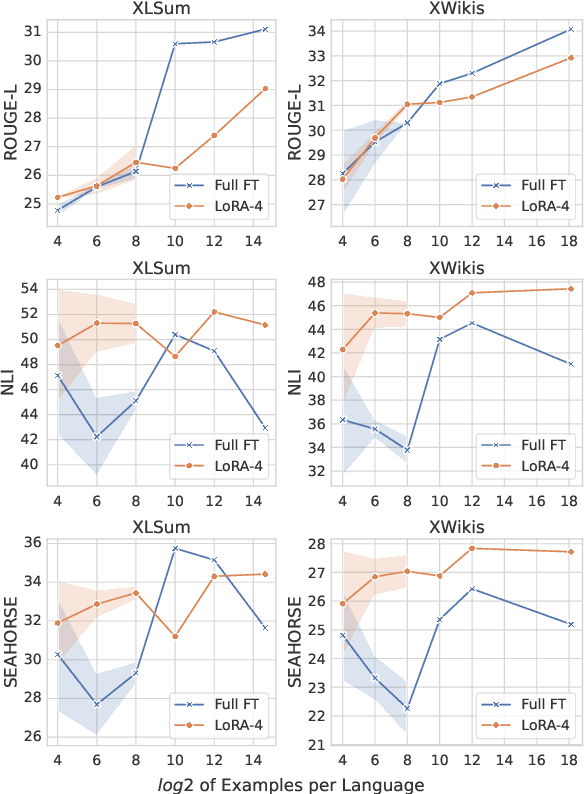
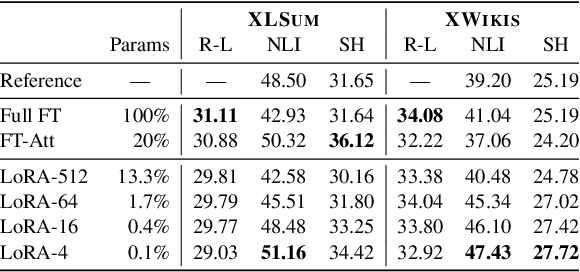

With the increasing prevalence of Large Language Models, traditional full fine-tuning approaches face growing challenges, especially in memory-intensive tasks. This paper investigates the potential of Parameter-Efficient Fine-Tuning, focusing on Low-Rank Adaptation (LoRA), for complex and under-explored multilingual summarisation tasks. We conduct an extensive study across different data availability scenarios, including full-data, low-data, and cross-lingual transfer, leveraging models of different sizes. Our findings reveal that LoRA lags behind full fine-tuning when trained with full data, however, it excels in low-data scenarios and cross-lingual transfer. Interestingly, as models scale up, the performance gap between LoRA and full fine-tuning diminishes. Additionally, we investigate effective strategies for few-shot cross-lingual transfer, finding that continued LoRA tuning achieves the best performance compared to both full fine-tuning and dynamic composition of language-specific LoRA modules.
UT5: Pretraining Non autoregressive T5 with unrolled denoising
Nov 14, 2023Recent advances in Transformer-based Large Language Models have made great strides in natural language generation. However, to decode K tokens, an autoregressive model needs K sequential forward passes, which may be a performance bottleneck for large language models. Many non-autoregressive (NAR) research are aiming to address this sequentiality bottleneck, albeit many have focused on a dedicated architecture in supervised benchmarks. In this work, we studied unsupervised pretraining for non auto-regressive T5 models via unrolled denoising and shown its SoTA results in downstream generation tasks such as SQuAD question generation and XSum.
Autoregressive Modeling is Misspecified for Some Sequence Distributions
Oct 22, 2020
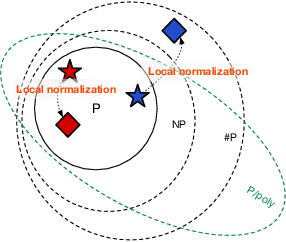
Should sequences be modeled autoregressively---one symbol at a time? How much computation is needed to predict the next symbol? While local normalization is cheap, this also limits its power. We point out that some probability distributions over discrete sequences cannot be well-approximated by any autoregressive model whose runtime and parameter size grow polynomially in the sequence length---even though their unnormalized sequence probabilities are efficient to compute exactly. Intuitively, the probability of the next symbol can be expensive to compute or approximate (even via randomized algorithms) when it marginalizes over exponentially many possible futures, which is in general $\mathrm{NP}$-hard. Our result is conditional on the widely believed hypothesis that $\mathrm{NP} \nsubseteq \mathrm{P/poly}$ (without which the polynomial hierarchy would collapse at the second level). This theoretical observation serves as a caution to the viewpoint that pumping up parameter size is a straightforward way to improve autoregressive models (e.g., in language modeling). It also suggests that globally normalized (energy-based) models may sometimes outperform locally normalized (autoregressive) models, as we demonstrate experimentally for language modeling.