 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't lie to your friends: Learning what you know from collaborative self-play
Mar 18, 2025To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outputs, and when to abstain or hedge. Such capabilities are hard to teach through supervised fine-tuning because they require constructing examples that reflect the agent's specific capabilities. We therefore propose a radically new approach to teaching agents what they know: \emph{collaborative self-play}. We construct multi-agent collaborations in which the group is rewarded for collectively arriving at correct answers. The desired meta-knowledge emerges from the incentives built into the structure of the interaction. We focus on small societies of agents that have access to heterogeneous tools (corpus-specific retrieval), and therefore must collaborate to maximize their success while minimizing their effort. Experiments show that group-level rewards for multi-agent communities can induce policies that \emph{transfer} to improve tool use and selective prediction in settings where individual agents are deployed in isolation.
Evaluating LLMs for Targeted Concept Simplification forDomain-Specific Texts
Oct 28, 2024


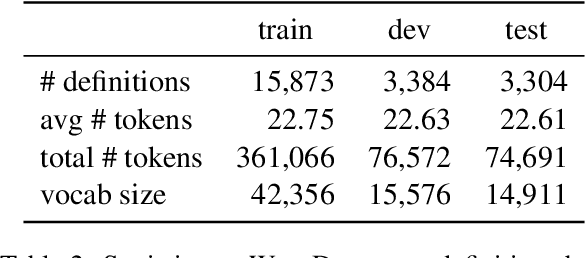
One useful application of NLP models is to support people in reading complex text from unfamiliar domains (e.g., scientific articles). Simplifying the entire text makes it understandable but sometimes removes important details. On the contrary, helping adult readers understand difficult concepts in context can enhance their vocabulary and knowledge. In a preliminary human study, we first identify that lack of context and unfamiliarity with difficult concepts is a major reason for adult readers' difficulty with domain-specific text. We then introduce "targeted concept simplification," a simplification task for rewriting text to help readers comprehend text containing unfamiliar concepts. We also introduce WikiDomains, a new dataset of 22k definitions from 13 academic domains paired with a difficult concept within each definition. We benchmark the performance of open-source and commercial LLMs and a simple dictionary baseline on this task across human judgments of ease of understanding and meaning preservation. Interestingly, our human judges preferred explanations about the difficult concept more than simplification of the concept phrase. Further, no single model achieved superior performance across all quality dimensions, and automated metrics also show low correlations with human evaluations of concept simplification ($\sim0.2$), opening up rich avenues for research on personalized human reading comprehension support.
Agents' Room: Narrative Generation through Multi-step Collaboration
Oct 03, 2024Writing compelling fiction is a multifaceted process combining elements such as crafting a plot, developing interesting characters, and using evocative language. While large language models (LLMs) show promise for story writing, they currently rely heavily on intricate prompting, which limits their use. We propose Agents' Room, a generation framework inspired by narrative theory, that decomposes narrative writing into subtasks tackled by specialized agents. To illustrate our method, we introduce Tell Me A Story, a high-quality dataset of complex writing prompts and human-written stories, and a novel evaluation framework designed specifically for assessing long narratives. We show that Agents' Room generates stories that are preferred by expert evaluators over those produced by baseline systems by leveraging collaboration and specialization to decompose the complex story writing task into tractable components. We provide extensive analysis with automated and human-based metrics of the generated output.
DOLOMITES: Domain-Specific Long-Form Methodical Tasks
May 09, 2024Experts in various fields routinely perform methodical writing tasks to plan, organize, and report their work. From a clinician writing a differential diagnosis for a patient, to a teacher writing a lesson plan for students, these tasks are pervasive, requiring to methodically generate structured long-form output for a given input. We develop a typology of methodical tasks structured in the form of a task objective, procedure, input, and output, and introduce DoLoMiTes, a novel benchmark with specifications for 519 such tasks elicited from hundreds of experts from across 25 fields. Our benchmark further contains specific instantiations of methodical tasks with concrete input and output examples (1,857 in total) which we obtain by collecting expert revisions of up to 10 model-generated examples of each task. We use these examples to evaluate contemporary language models highlighting that automating methodical tasks is a challenging long-form generation problem, as it requires performing complex inferences, while drawing upon the given context as well as domain knowledge.
Learning to Plan and Generate Text with Citations
Apr 04, 2024The increasing demand for the deployment of LLMs in information-seeking scenarios has spurred efforts in creating verifiable systems, which generate responses to queries along with supporting evidence. In this paper, we explore the attribution capabilities of plan-based models which have been recently shown to improve the faithfulness, grounding, and controllability of generated text. We conceptualize plans as a sequence of questions which serve as blueprints of the generated content and its organization. We propose two attribution models that utilize different variants of blueprints, an abstractive model where questions are generated from scratch, and an extractive model where questions are copied from the input. Experiments on long-form question-answering show that planning consistently improves attribution quality. Moreover, the citations generated by blueprint models are more accurate compared to those obtained from LLM-based pipelines lacking a planning component.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Parameter-Efficient Multilingual Summarisation: An Empirical Study
Nov 14, 2023
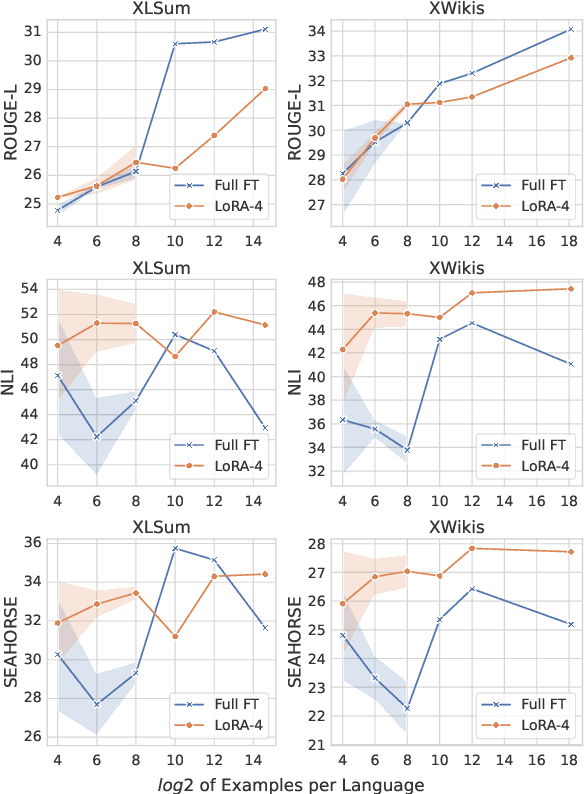
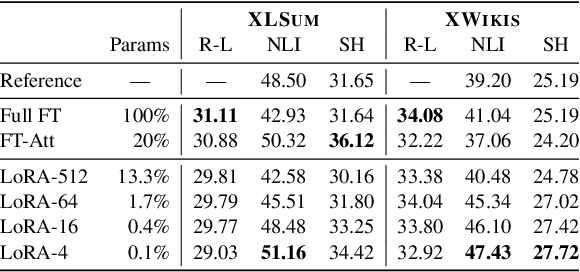

With the increasing prevalence of Large Language Models, traditional full fine-tuning approaches face growing challenges, especially in memory-intensive tasks. This paper investigates the potential of Parameter-Efficient Fine-Tuning, focusing on Low-Rank Adaptation (LoRA), for complex and under-explored multilingual summarisation tasks. We conduct an extensive study across different data availability scenarios, including full-data, low-data, and cross-lingual transfer, leveraging models of different sizes. Our findings reveal that LoRA lags behind full fine-tuning when trained with full data, however, it excels in low-data scenarios and cross-lingual transfer. Interestingly, as models scale up, the performance gap between LoRA and full fine-tuning diminishes. Additionally, we investigate effective strategies for few-shot cross-lingual transfer, finding that continued LoRA tuning achieves the best performance compared to both full fine-tuning and dynamic composition of language-specific LoRA modules.
How (not) to ensemble LVLMs for VQA
Oct 10, 2023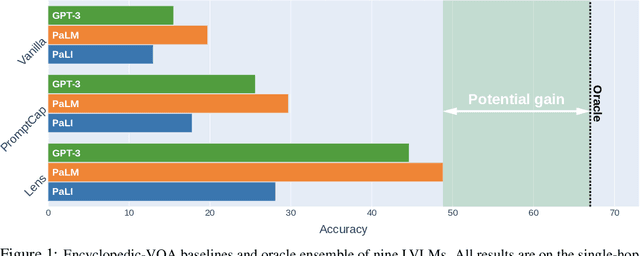


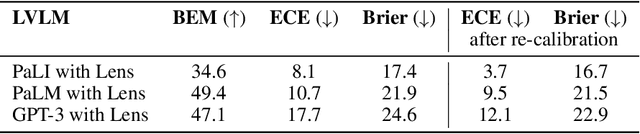
This paper studies ensembling in the era of Large Vision-Language Models (LVLMs). Ensembling is a classical method to combine different models to get increased performance. In the recent work on Encyclopedic-VQA the authors examine a wide variety of models to solve their task: from vanilla LVLMs, to models including the caption as extra context, to models augmented with Lens-based retrieval of Wikipedia pages. Intuitively these models are highly complementary, which should make them ideal for ensembling. Indeed, an oracle experiment shows potential gains from 48.8% accuracy (the best single model) all the way up to 67% (best possible ensemble). So it is a trivial exercise to create an ensemble with substantial real gains. Or is it?
$μ$PLAN: Summarizing using a Content Plan as Cross-Lingual Bridge
May 23, 2023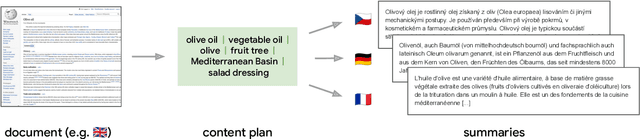
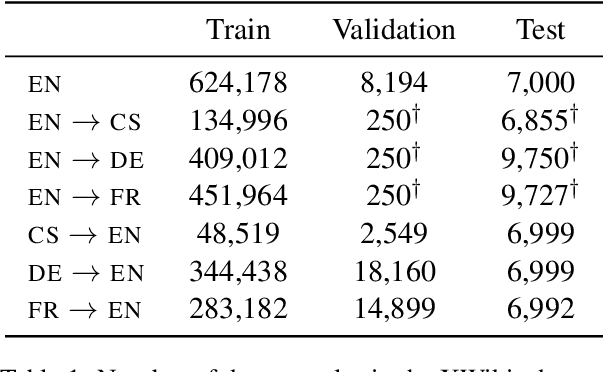


Cross-lingual summarization consists of generating a summary in one language given an input document in a different language, allowing for the dissemination of relevant content across speakers of other languages. However, this task remains challenging, mainly because of the need for cross-lingual datasets and the compounded difficulty of summarizing and translating. This work presents $\mu$PLAN, an approach to cross-lingual summarization that uses an intermediate planning step as a cross-lingual bridge. We formulate the plan as a sequence of entities that captures the conceptualization of the summary, i.e. identifying the salient content and expressing in which order to present the information, separate from the surface form. Using a multilingual knowledge base, we align the entities to their canonical designation across languages. $\mu$PLAN models first learn to generate the plan and then continue generating the summary conditioned on the plan and the input. We evaluate our methodology on the XWikis dataset on cross-lingual pairs across four languages and demonstrate that this planning objective achieves state-of-the-art performance in terms of ROUGE and faithfulness scores. Moreover, this planning approach improves the zero-shot transfer to new cross-lingual language pairs compared to non-planning baselines.