 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't lie to your friends: Learning what you know from collaborative self-play
Mar 18, 2025To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outputs, and when to abstain or hedge. Such capabilities are hard to teach through supervised fine-tuning because they require constructing examples that reflect the agent's specific capabilities. We therefore propose a radically new approach to teaching agents what they know: \emph{collaborative self-play}. We construct multi-agent collaborations in which the group is rewarded for collectively arriving at correct answers. The desired meta-knowledge emerges from the incentives built into the structure of the interaction. We focus on small societies of agents that have access to heterogeneous tools (corpus-specific retrieval), and therefore must collaborate to maximize their success while minimizing their effort. Experiments show that group-level rewards for multi-agent communities can induce policies that \emph{transfer} to improve tool use and selective prediction in settings where individual agents are deployed in isolation.
Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities
May 29, 2024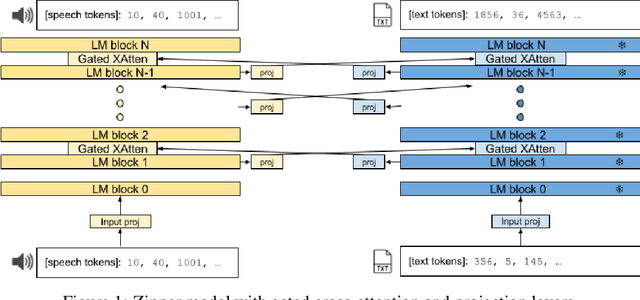


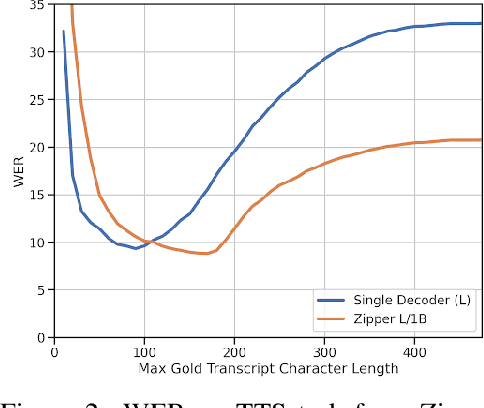
Integrating multiple generative foundation models, especially those trained on different modalities, into something greater than the sum of its parts poses significant challenges. Two key hurdles are the availability of aligned data (concepts that contain similar meaning but is expressed differently in different modalities), and effectively leveraging unimodal representations in cross-domain generative tasks, without compromising their original unimodal capabilities. We propose Zipper, a multi-tower decoder architecture that addresses these concerns by using cross-attention to flexibly compose multimodal generative models from independently pre-trained unimodal decoders. In our experiments fusing speech and text modalities, we show the proposed architecture performs very competitively in scenarios with limited aligned text-speech data. We also showcase the flexibility of our model to selectively maintain unimodal (e.g., text-to-text generation) generation performance by freezing the corresponding modal tower (e.g. text). In cross-modal tasks such as automatic speech recognition (ASR) where the output modality is text, we show that freezing the text backbone results in negligible performance degradation. In cross-modal tasks such as text-to-speech generation (TTS) where the output modality is speech, we show that using a pre-trained speech backbone results in superior performance to the baseline.
Robust Preference Optimization through Reward Model Distillation
May 29, 2024Language model (LM) post-training (or alignment) involves maximizing a reward function that is derived from preference annotations. Direct Preference Optimization (DPO) is a popular offline alignment method that trains a policy directly on preference data without the need to train a reward model or apply reinforcement learning. However, typical preference datasets have only a single, or at most a few, annotation per preference pair, which causes DPO to overconfidently assign rewards that trend towards infinite magnitude. This frequently leads to degenerate policies, sometimes causing even the probabilities of the preferred generations to go to zero. In this work, we analyze this phenomenon and propose distillation to get a better proxy for the true preference distribution over generation pairs: we train the LM to produce probabilities that match the distribution induced by a reward model trained on the preference data. Moreover, to account for uncertainty in the reward model we are distilling from, we optimize against a family of reward models that, as a whole, is likely to include at least one reasonable proxy for the preference distribution. Our results show that distilling from such a family of reward models leads to improved robustness to distribution shift in preference annotations, while preserving the simple supervised nature of DPO.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023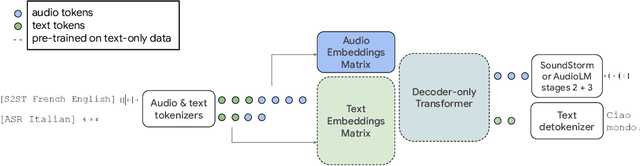



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
MultiTurnCleanup: A Benchmark for Multi-Turn Spoken Conversational Transcript Cleanup
May 19, 2023Current disfluency detection models focus on individual utterances each from a single speaker. However, numerous discontinuity phenomena in spoken conversational transcripts occur across multiple turns, hampering human readability and the performance of downstream NLP tasks. This study addresses these phenomena by proposing an innovative Multi-Turn Cleanup task for spoken conversational transcripts and collecting a new dataset, MultiTurnCleanup1. We design a data labeling schema to collect the high-quality dataset and provide extensive data analysis. Furthermore, we leverage two modeling approaches for experimental evaluation as benchmarks for future research.
Teaching BERT to Wait: Balancing Accuracy and Latency for Streaming Disfluency Detection
May 02, 2022
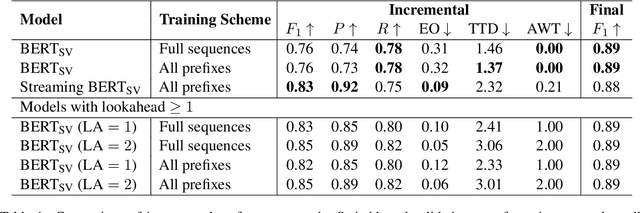
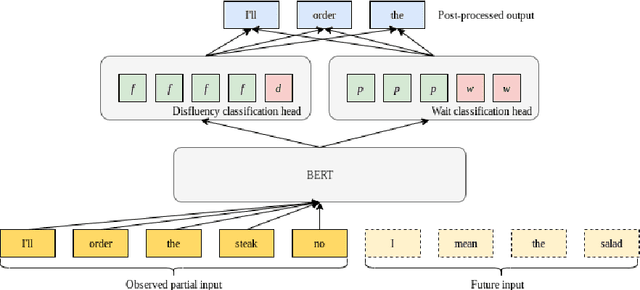
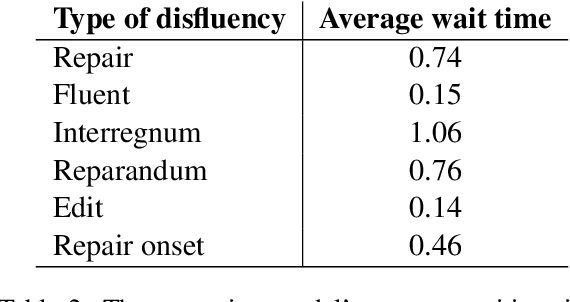
In modern interactive speech-based systems, speech is consumed and transcribed incrementally prior to having disfluencies removed. This post-processing step is crucial for producing clean transcripts and high performance on downstream tasks (e.g. machine translation). However, most current state-of-the-art NLP models such as the Transformer operate non-incrementally, potentially causing unacceptable delays. We propose a streaming BERT-based sequence tagging model that, combined with a novel training objective, is capable of detecting disfluencies in real-time while balancing accuracy and latency. This is accomplished by training the model to decide whether to immediately output a prediction for the current input or to wait for further context. Essentially, the model learns to dynamically size its lookahead window. Our results demonstrate that our model produces comparably accurate predictions and does so sooner than our baselines, with lower flicker. Furthermore, the model attains state-of-the-art latency and stability scores when compared with recent work on incremental disfluency detection.
Residual Adapters for Parameter-Efficient ASR Adaptation to Atypical and Accented Speech
Sep 14, 2021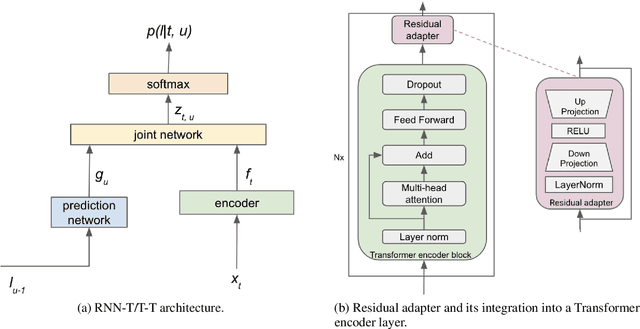
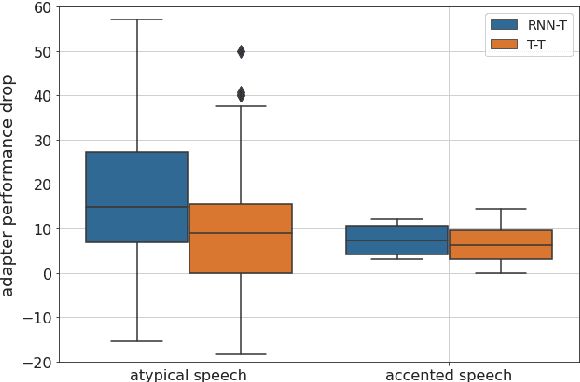
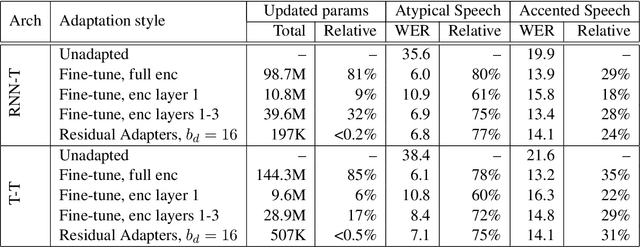
Automatic Speech Recognition (ASR) systems are often optimized to work best for speakers with canonical speech patterns. Unfortunately, these systems perform poorly when tested on atypical speech and heavily accented speech. It has previously been shown that personalization through model fine-tuning substantially improves performance. However, maintaining such large models per speaker is costly and difficult to scale. We show that by adding a relatively small number of extra parameters to the encoder layers via so-called residual adapter, we can achieve similar adaptation gains compared to model fine-tuning, while only updating a tiny fraction (less than 0.5%) of the model parameters. We demonstrate this on two speech adaptation tasks (atypical and accented speech) and for two state-of-the-art ASR architectures.
Disfluency Detection with Unlabeled Data and Small BERT Models
Apr 21, 2021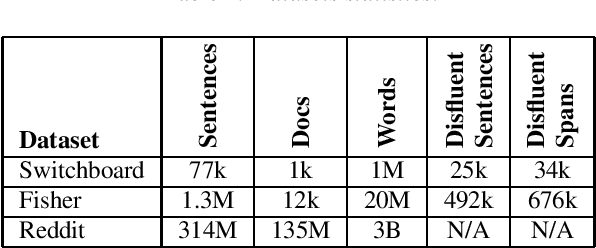
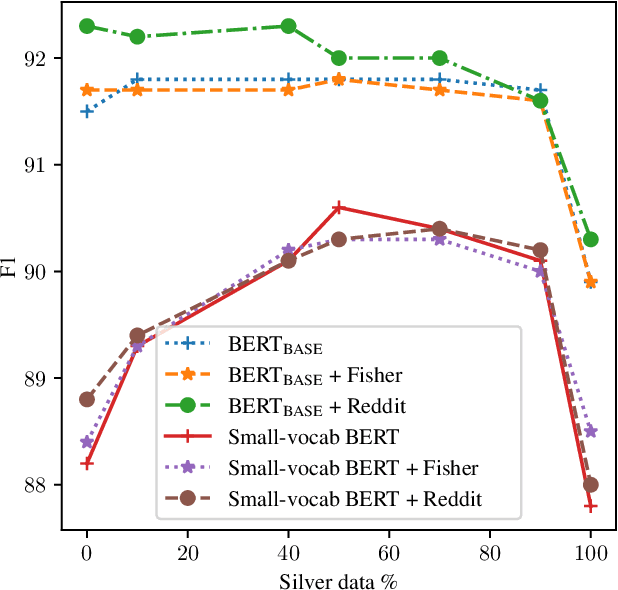
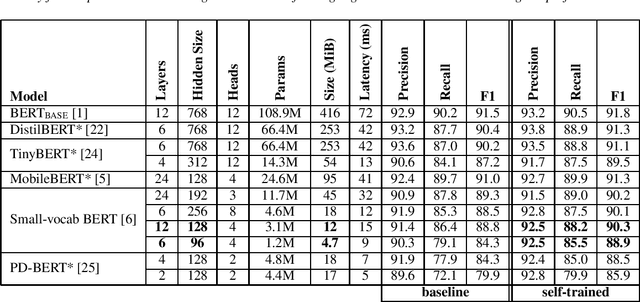
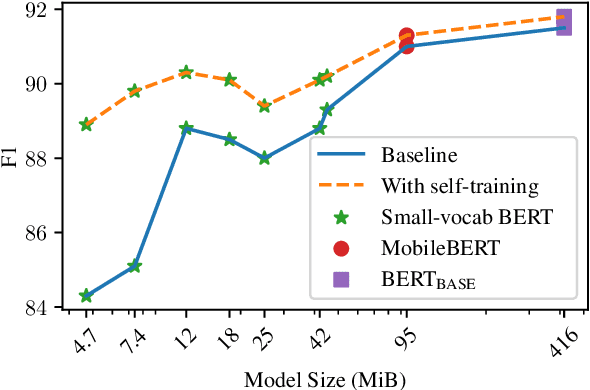
Disfluency detection models now approach high accuracy on English text. However, little exploration has been done in improving the size and inference time of the model. At the same time, automatic speech recognition (ASR) models are moving from server-side inference to local, on-device inference. Supporting models in the transcription pipeline (like disfluency detection) must follow suit. In this work we concentrate on the disfluency detection task, focusing on small, fast, on-device models based on the BERT architecture. We demonstrate it is possible to train disfluency detection models as small as 1.3 MiB, while retaining high performance. We build on previous work that showed the benefit of data augmentation approaches such as self-training. Then, we evaluate the effect of domain mismatch between conversational and written text on model performance. We find that domain adaptation and data augmentation strategies have a more pronounced effect on these smaller models, as compared to conventional BERT models.
Representations for Question Answering from Documents with Tables and Text
Jan 26, 2021
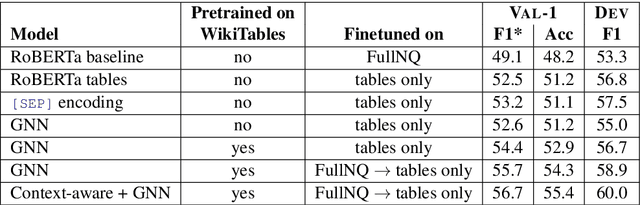
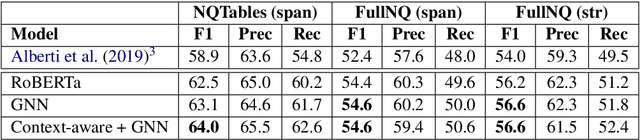
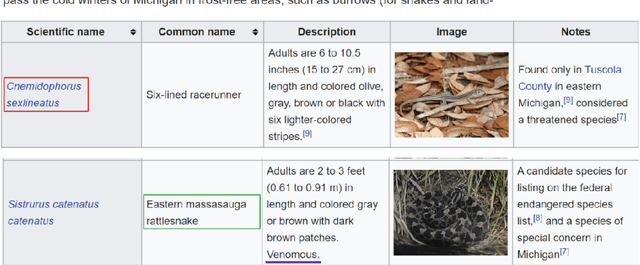
Tables in Web documents are pervasive and can be directly used to answer many of the queries searched on the Web, motivating their integration in question answering. Very often information presented in tables is succinct and hard to interpret with standard language representations. On the other hand, tables often appear within textual context, such as an article describing the table. Using the information from an article as additional context can potentially enrich table representations. In this work we aim to improve question answering from tables by refining table representations based on information from surrounding text. We also present an effective method to combine text and table-based predictions for question answering from full documents, obtaining significant improvements on the Natural Questions dataset.
Disfluencies and Human Speech Transcription Errors
Apr 08, 2019
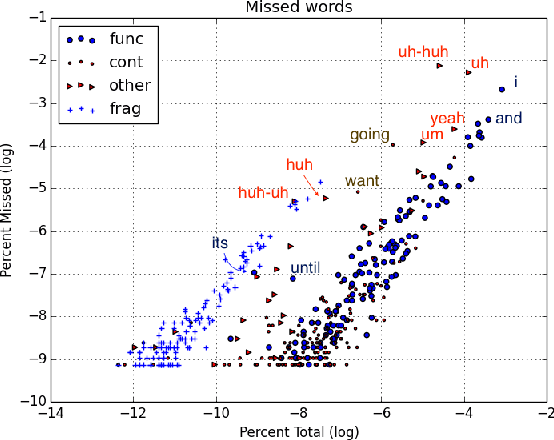
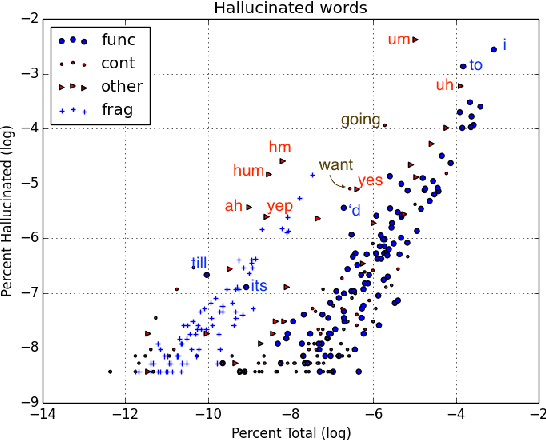
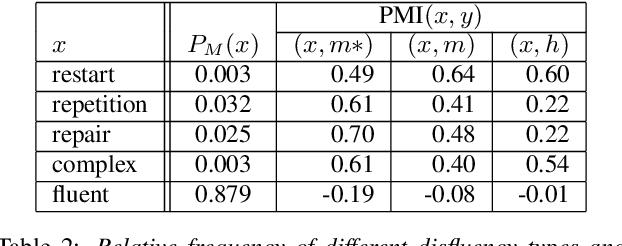
This paper explores contexts associated with errors in transcrip-tion of spontaneous speech, shedding light on human perceptionof disfluencies and other conversational speech phenomena. Anew version of the Switchboard corpus is provided with disfluency annotations for careful speech transcripts, together with results showing the impact of transcription errors on evaluation of automatic disfluency detection.