 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023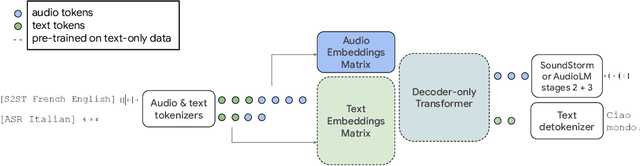



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
Learning Translation Quality Evaluation on Low Resource Languages from Large Language Models
Feb 07, 2023



Learned metrics such as BLEURT have in recent years become widely employed to evaluate the quality of machine translation systems. Training such metrics requires data which can be expensive and difficult to acquire, particularly for lower-resource languages. We show how knowledge can be distilled from Large Language Models (LLMs) to improve upon such learned metrics without requiring human annotators, by creating synthetic datasets which can be mixed into existing datasets, requiring only a corpus of text in the target language. We show that the performance of a BLEURT-like model on lower resource languages can be improved in this way.
Spatial Consistency Loss for Training Multi-Label Classifiers from Single-Label Annotations
Mar 11, 2022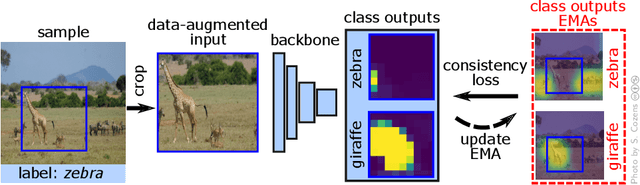
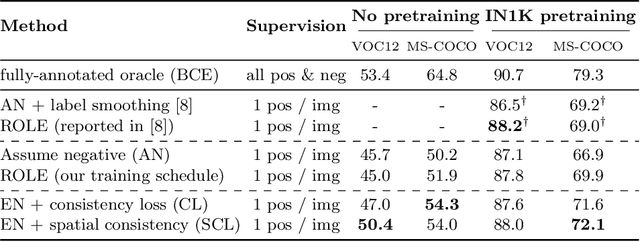

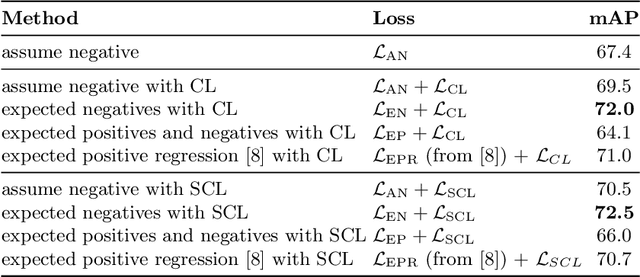
As natural images usually contain multiple objects, multi-label image classification is more applicable "in the wild" than single-label classification. However, exhaustively annotating images with every object of interest is costly and time-consuming. We aim to train multi-label classifiers from single-label annotations only. We show that adding a consistency loss, ensuring that the predictions of the network are consistent over consecutive training epochs, is a simple yet effective method to train multi-label classifiers in a weakly supervised setting. We further extend this approach spatially, by ensuring consistency of the spatial feature maps produced over consecutive training epochs, maintaining per-class running-average heatmaps for each training image. We show that this spatial consistency loss further improves the multi-label mAP of the classifiers. In addition, we show that this method overcomes shortcomings of the "crop" data-augmentation by recovering correct supervision signal even when most of the single ground truth object is cropped out of the input image by the data augmentation. We demonstrate gains of the consistency and spatial consistency losses over the binary cross-entropy baseline, and over competing methods, on MS-COCO and Pascal VOC. We also demonstrate improved multi-label classification mAP on ImageNet-1K using the ReaL multi-label validation set.
On Mutual Information Maximization for Representation Learning
Jul 31, 2019


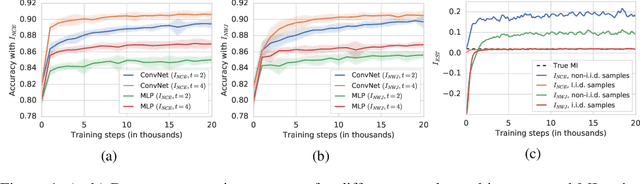
Many recent methods for unsupervised or self-supervised representation learning train feature extractors by maximizing an estimate of the mutual information (MI) between different views of the data. This comes with several immediate problems: For example, MI is notoriously hard to estimate, and using it as an objective for representation learning may lead to highly entangled representations due to its invariance under arbitrary invertible transformations. Nevertheless, these methods have been repeatedly shown to excel in practice. In this paper we argue, and provide empirical evidence, that the success of these methods might be only loosely attributed to the properties of MI, and that they strongly depend on the inductive bias in both the choice of feature extractor architectures and the parametrization of the employed MI estimators. Finally, we establish a connection to deep metric learning and argue that this interpretation may be a plausible explanation for the success of the recently introduced methods.
Practical and Consistent Estimation of f-Divergences
May 27, 2019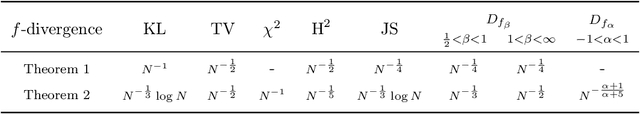

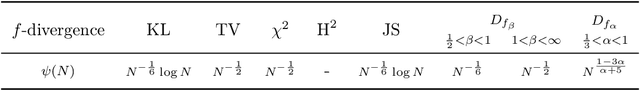

The estimation of an f-divergence between two probability distributions based on samples is a fundamental problem in statistics and machine learning. Most works study this problem under very weak assumptions, in which case it is provably hard. We consider the case of stronger structural assumptions that are commonly satisfied in modern machine learning, including representation learning and generative modelling with autoencoder architectures. Under these assumptions we propose and study an estimator that can be easily implemented, works well in high dimensions, and enjoys faster rates of convergence. We verify the behavior of our estimator empirically in both synthetic and real-data experiments, and discuss its direct implications for total correlation, entropy, and mutual information estimation.
The Incomplete Rosetta Stone Problem: Identifiability Results for Multi-View Nonlinear ICA
May 16, 2019
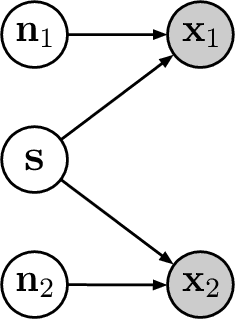


We consider the problem of recovering a common latent source with independent components from multiple views. This applies to settings in which a variable is measured with multiple experimental modalities, and where the goal is to synthesize the disparate measurements into a single unified representation. We consider the case that the observed views are a nonlinear mixing of component-wise corruptions of the sources. When the views are considered separately, this reduces to nonlinear Independent Component Analysis (ICA) for which it is provably impossible to undo the mixing. We present novel identifiability proofs that this is possible when the multiple views are considered jointly, showing that the mixing can theoretically be undone using function approximators such as deep neural networks. In contrast to known identifiability results for nonlinear ICA, we prove that independent latent sources with arbitrary mixing can be recovered as long as multiple, sufficiently different noisy views are available.
An Empirical Study of Generative Models with Encoders
Dec 19, 2018

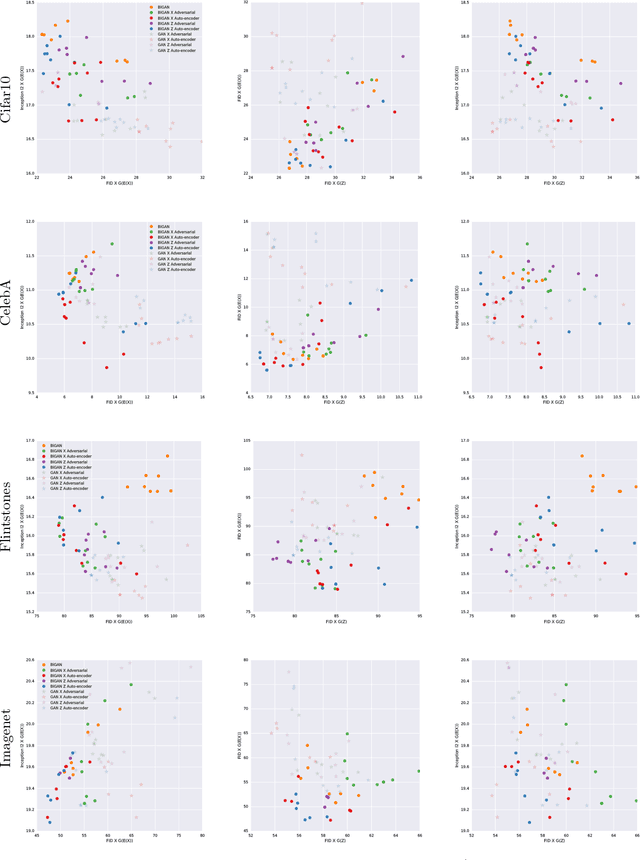
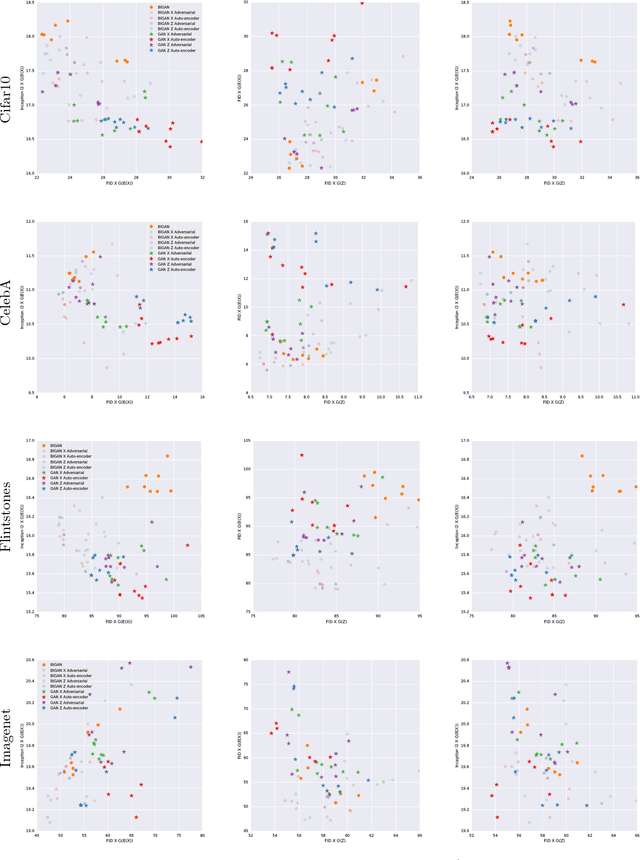
Generative adversarial networks (GANs) are capable of producing high quality image samples. However, unlike variational autoencoders (VAEs), GANs lack encoders that provide the inverse mapping for the generators, i.e., encode images back to the latent space. In this work, we consider adversarially learned generative models that also have encoders. We evaluate models based on their ability to produce high quality samples and reconstructions of real images. Our main contributions are twofold: First, we find that the baseline Bidirectional GAN (BiGAN) can be improved upon with the addition of an autoencoder loss, at the expense of an extra hyper-parameter to tune. Second, we show that comparable performance to BiGAN can be obtained by simply training an encoder to invert the generator of a normal GAN.
From Deterministic ODEs to Dynamic Structural Causal Models
Jul 09, 2018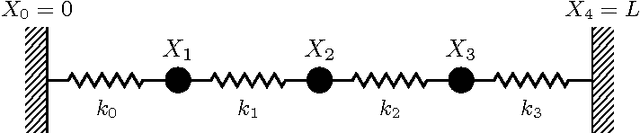
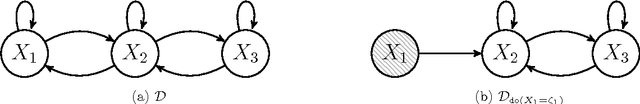


Structural Causal Models are widely used in causal modelling, but how they relate to other modelling tools is poorly understood. In this paper we provide a novel perspective on the relationship between Ordinary Differential Equations and Structural Causal Models. We show how, under certain conditions, the asymptotic behaviour of an Ordinary Differential Equation under non-constant interventions can be modelled using Dynamic Structural Causal Models. In contrast to earlier work, we study not only the effect of interventions on equilibrium states; rather, we model asymptotic behaviour that is dynamic under interventions that vary in time, and include as a special case the study of static equilibria.
On the Latent Space of Wasserstein Auto-Encoders
Feb 11, 2018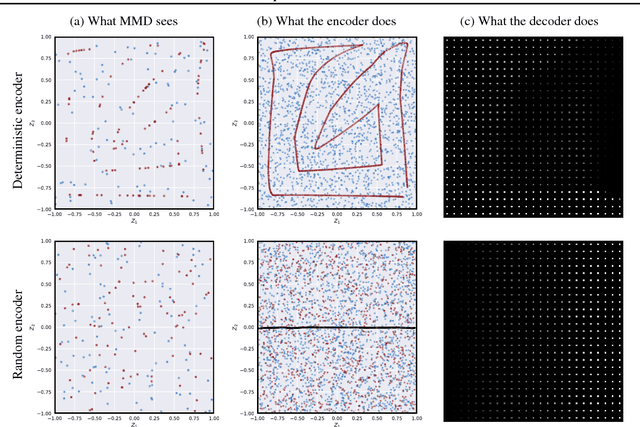



We study the role of latent space dimensionality in Wasserstein auto-encoders (WAEs). Through experimentation on synthetic and real datasets, we argue that random encoders should be preferred over deterministic encoders. We highlight the potential of WAEs for representation learning with promising results on a benchmark disentanglement task.
Causal Consistency of Structural Equation Models
Jul 04, 2017
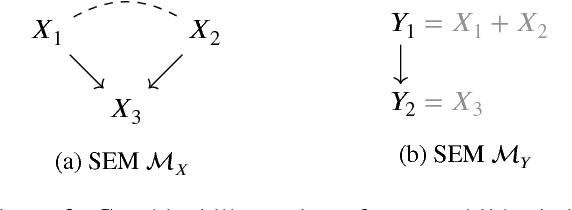
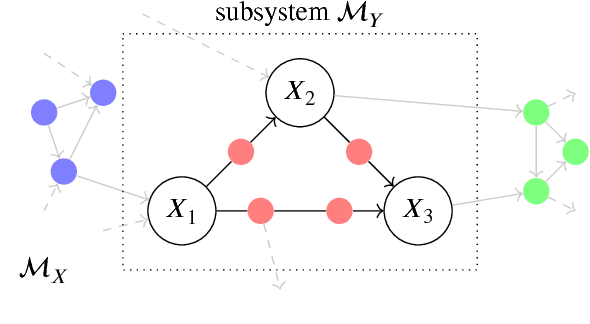
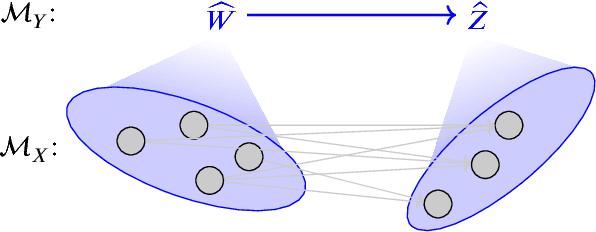
Complex systems can be modelled at various levels of detail. Ideally, causal models of the same system should be consistent with one another in the sense that they agree in their predictions of the effects of interventions. We formalise this notion of consistency in the case of Structural Equation Models (SEMs) by introducing exact transformations between SEMs. This provides a general language to consider, for instance, the different levels of description in the following three scenarios: (a) models with large numbers of variables versus models in which the `irrelevant' or unobservable variables have been marginalised out; (b) micro-level models versus macro-level models in which the macro-variables are aggregate features of the micro-variables; (c) dynamical time series models versus models of their stationary behaviour. Our analysis stresses the importance of well specified interventions in the causal modelling process and sheds light on the interpretation of cyclic SEMs.
* equal contribution between Rubenstein and Weichwald; accepted manuscript