 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Spatial: Exploring 3D Spatial Understanding in Multimodal LLMs
Mar 17, 2025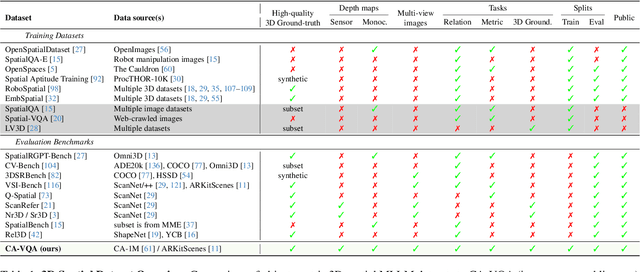

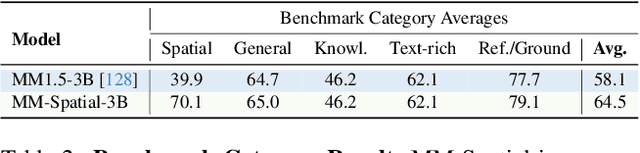

Multimodal large language models (MLLMs) excel at 2D visual understanding but remain limited in their ability to reason about 3D space. In this work, we leverage large-scale high-quality 3D scene data with open-set annotations to introduce 1) a novel supervised fine-tuning dataset and 2) a new evaluation benchmark, focused on indoor scenes. Our Cubify Anything VQA (CA-VQA) data covers diverse spatial tasks including spatial relationship prediction, metric size and distance estimation, and 3D grounding. We show that CA-VQA enables us to train MM-Spatial, a strong generalist MLLM that also achieves state-of-the-art performance on 3D spatial understanding benchmarks, including our own. We show how incorporating metric depth and multi-view inputs (provided in CA-VQA) can further improve 3D understanding, and demonstrate that data alone allows our model to achieve depth perception capabilities comparable to dedicated monocular depth estimation models. We will publish our SFT dataset and benchmark.
Multimodal Autoregressive Pre-training of Large Vision Encoders
Nov 21, 2024



We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
Contrastive Localized Language-Image Pre-Training
Oct 03, 2024



Contrastive Language-Image Pre-training (CLIP) has been a celebrated method for training vision encoders to generate image/text representations facilitating various applications. Recently, CLIP has been widely adopted as the vision backbone of multimodal large language models (MLLMs) to connect image inputs for language interactions. The success of CLIP as a vision-language foundation model relies on aligning web-crawled noisy text annotations at image levels. Nevertheless, such criteria may become insufficient for downstream tasks in need of fine-grained vision representations, especially when region-level understanding is demanding for MLLMs. In this paper, we improve the localization capability of CLIP with several advances. We propose a pre-training method called Contrastive Localized Language-Image Pre-training (CLOC) by complementing CLIP with region-text contrastive loss and modules. We formulate a new concept, promptable embeddings, of which the encoder produces image embeddings easy to transform into region representations given spatial hints. To support large-scale pre-training, we design a visually-enriched and spatially-localized captioning framework to effectively generate region-text pseudo-labels at scale. By scaling up to billions of annotated images, CLOC enables high-quality regional embeddings for image region recognition and retrieval tasks, and can be a drop-in replacement of CLIP to enhance MLLMs, especially on referring and grounding tasks.
Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
Sep 08, 2023



Sparse Mixture-of-Experts models (MoEs) have recently gained popularity due to their ability to decouple model size from inference efficiency by only activating a small subset of the model parameters for any given input token. As such, sparse MoEs have enabled unprecedented scalability, resulting in tremendous successes across domains such as natural language processing and computer vision. In this work, we instead explore the use of sparse MoEs to scale-down Vision Transformers (ViTs) to make them more attractive for resource-constrained vision applications. To this end, we propose a simplified and mobile-friendly MoE design where entire images rather than individual patches are routed to the experts. We also propose a stable MoE training procedure that uses super-class information to guide the router. We empirically show that our sparse Mobile Vision MoEs (V-MoEs) can achieve a better trade-off between performance and efficiency than the corresponding dense ViTs. For example, for the ViT-Tiny model, our Mobile V-MoE outperforms its dense counterpart by 3.39% on ImageNet-1k. For an even smaller ViT variant with only 54M FLOPs inference cost, our MoE achieves an improvement of 4.66%.
Spatial Consistency Loss for Training Multi-Label Classifiers from Single-Label Annotations
Mar 11, 2022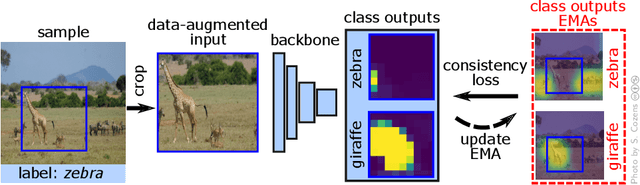
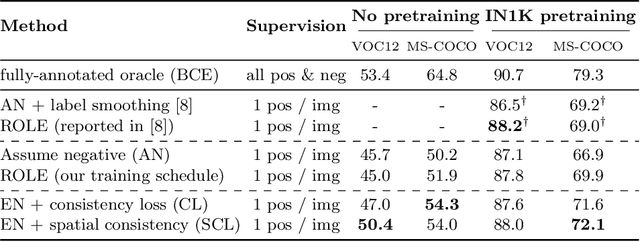

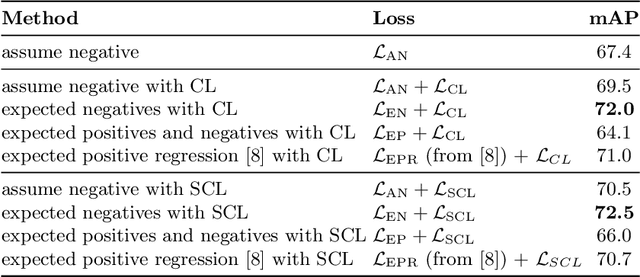
As natural images usually contain multiple objects, multi-label image classification is more applicable "in the wild" than single-label classification. However, exhaustively annotating images with every object of interest is costly and time-consuming. We aim to train multi-label classifiers from single-label annotations only. We show that adding a consistency loss, ensuring that the predictions of the network are consistent over consecutive training epochs, is a simple yet effective method to train multi-label classifiers in a weakly supervised setting. We further extend this approach spatially, by ensuring consistency of the spatial feature maps produced over consecutive training epochs, maintaining per-class running-average heatmaps for each training image. We show that this spatial consistency loss further improves the multi-label mAP of the classifiers. In addition, we show that this method overcomes shortcomings of the "crop" data-augmentation by recovering correct supervision signal even when most of the single ground truth object is cropped out of the input image by the data augmentation. We demonstrate gains of the consistency and spatial consistency losses over the binary cross-entropy baseline, and over competing methods, on MS-COCO and Pascal VOC. We also demonstrate improved multi-label classification mAP on ImageNet-1K using the ReaL multi-label validation set.