 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Consistency Loss for Training Multi-Label Classifiers from Single-Label Annotations
Mar 11, 2022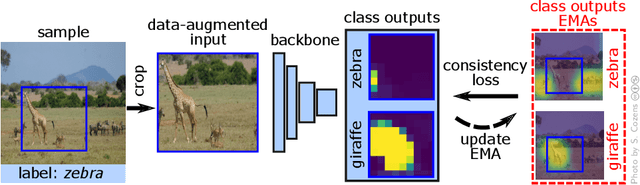
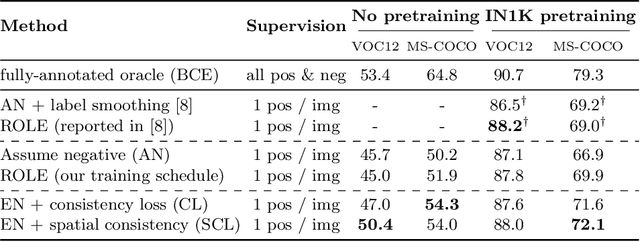

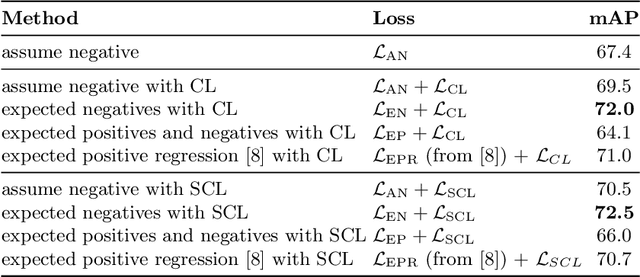
As natural images usually contain multiple objects, multi-label image classification is more applicable "in the wild" than single-label classification. However, exhaustively annotating images with every object of interest is costly and time-consuming. We aim to train multi-label classifiers from single-label annotations only. We show that adding a consistency loss, ensuring that the predictions of the network are consistent over consecutive training epochs, is a simple yet effective method to train multi-label classifiers in a weakly supervised setting. We further extend this approach spatially, by ensuring consistency of the spatial feature maps produced over consecutive training epochs, maintaining per-class running-average heatmaps for each training image. We show that this spatial consistency loss further improves the multi-label mAP of the classifiers. In addition, we show that this method overcomes shortcomings of the "crop" data-augmentation by recovering correct supervision signal even when most of the single ground truth object is cropped out of the input image by the data augmentation. We demonstrate gains of the consistency and spatial consistency losses over the binary cross-entropy baseline, and over competing methods, on MS-COCO and Pascal VOC. We also demonstrate improved multi-label classification mAP on ImageNet-1K using the ReaL multi-label validation set.
BlockCopy: High-Resolution Video Processing with Block-Sparse Feature Propagation and Online Policies
Aug 20, 2021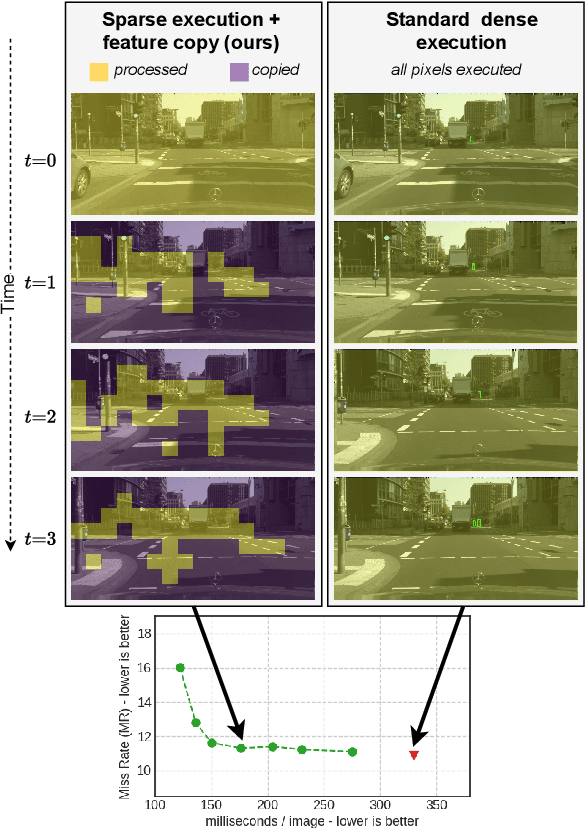
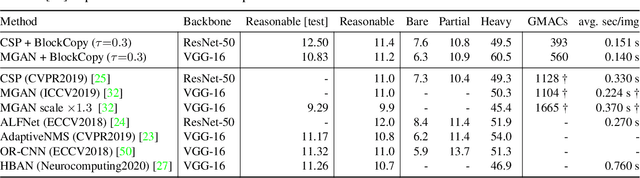
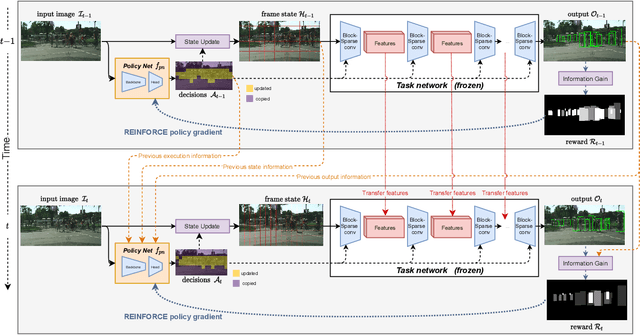
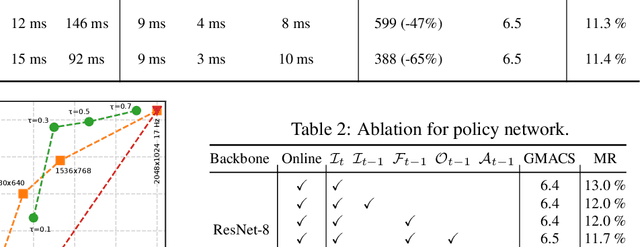
In this paper we propose BlockCopy, a scheme that accelerates pretrained frame-based CNNs to process video more efficiently, compared to standard frame-by-frame processing. To this end, a lightweight policy network determines important regions in an image, and operations are applied on selected regions only, using custom block-sparse convolutions. Features of non-selected regions are simply copied from the preceding frame, reducing the number of computations and latency. The execution policy is trained using reinforcement learning in an online fashion without requiring ground truth annotations. Our universal framework is demonstrated on dense prediction tasks such as pedestrian detection, instance segmentation and semantic segmentation, using both state of the art (Center and Scale Predictor, MGAN, SwiftNet) and standard baseline networks (Mask-RCNN, DeepLabV3+). BlockCopy achieves significant FLOPS savings and inference speedup with minimal impact on accuracy.
SegBlocks: Block-Based Dynamic Resolution Networks for Real-Time Segmentation
Nov 24, 2020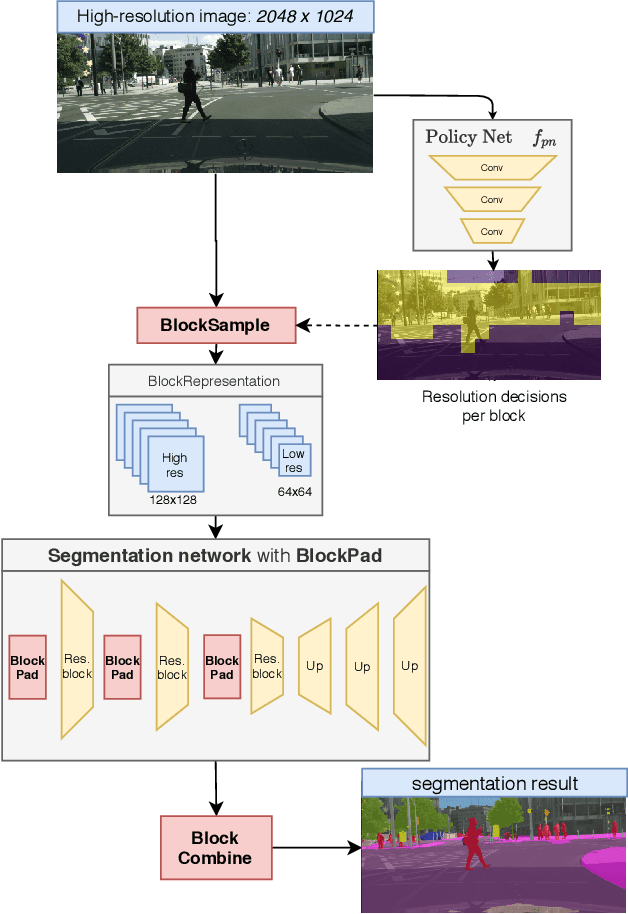
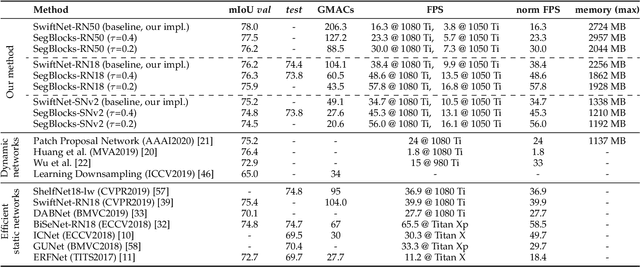
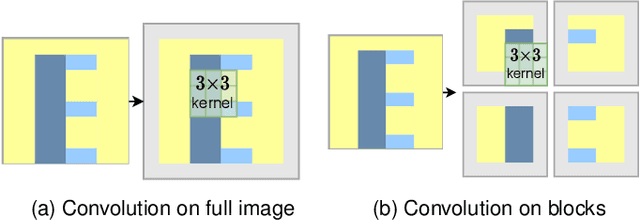

SegBlocks reduces the computational cost of existing neural networks, by dynamically adjusting the processing resolution of image regions based on their complexity. Our method splits an image into blocks and downsamples blocks of low complexity, reducing the number of operations and memory consumption. A lightweight policy network, selecting the complex regions, is trained using reinforcement learning. In addition, we introduce several modules implemented in CUDA to process images in blocks. Most important, our novel BlockPad module prevents the feature discontinuities at block borders of which existing methods suffer, while keeping memory consumption under control. Our experiments on Cityscapes and Mapillary Vistas semantic segmentation show that dynamically processing images offers a better accuracy versus complexity trade-off compared to static baselines of similar complexity. For instance, our method reduces the number of floating-point operations of SwiftNet-RN18 by 60% and increases the inference speed by 50%, with only 0.3% decrease in mIoU accuracy on Cityscapes.
Dynamic Convolutions: Exploiting Spatial Sparsity for Faster Inference
Dec 06, 2019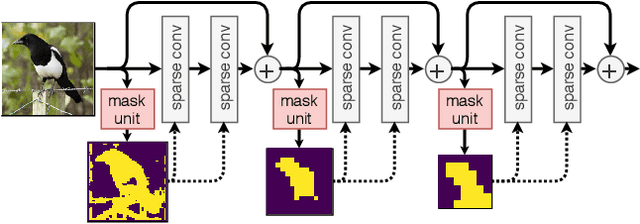
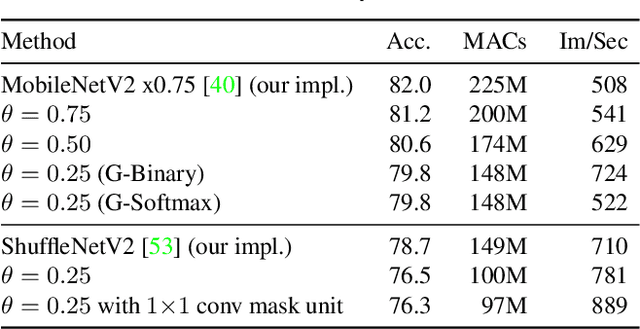
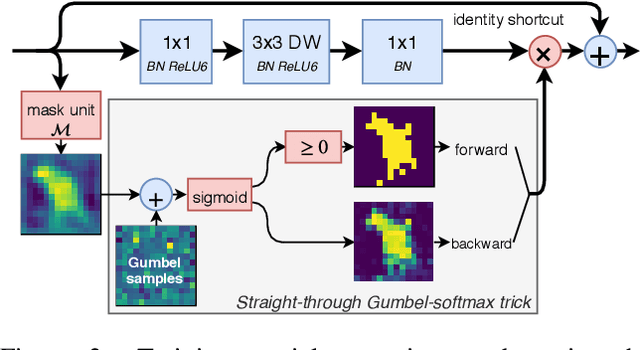

Modern convolutional neural networks apply the same operations on every pixel in an image. However, not all image regions are equally important. To address this inefficiency, we propose a method to dynamically apply convolutions conditioned on the input image. We introduce a residual block where a small gating branch learns which spatial positions should be evaluated. These discrete gating decisions are trained end-to-end using the Gumbel-Softmax trick, in combination with a sparsity criterion. Our experiments on Food-101, CIFAR and ImageNet show that our method has better focus on the region of interest and better accuracy than existing methods, at a lower computational complexity. Moreover, we provide an efficient CUDA implementation of our dynamic convolutions using a gather-scatter approach, achieving a significant improvement in inference speed on MobileNetV2 and ShuffleNetV2. On human pose estimation, a task that is inherently spatially sparse, the processing speed is increased by 45% with less than 0.1% loss in accuracy.
Generating superpixels using deep image representations
Mar 11, 2019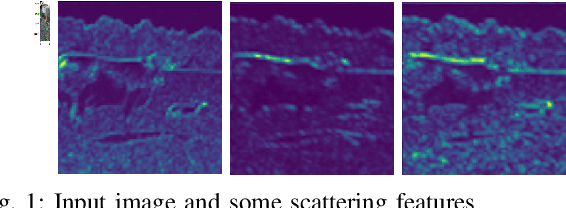
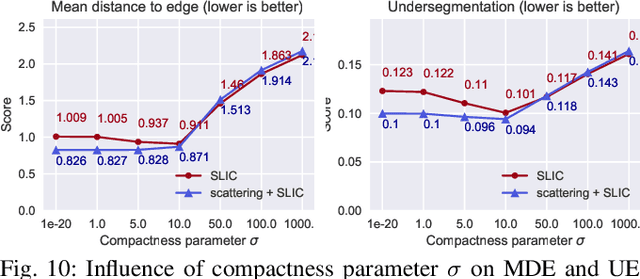
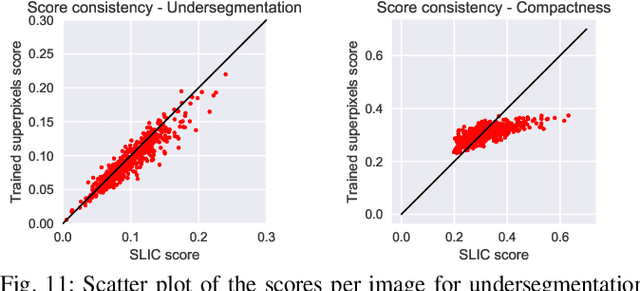

Superpixel algorithms are a common pre-processing step for computer vision algorithms such as segmentation, object tracking and localization. Many superpixel methods only rely on colors features for segmentation, limiting performance in low-contrast regions and applicability to infrared or medical images where object boundaries have wide appearance variability. We study the inclusion of deep image features in the SLIC superpixel algorithm to exploit higher-level image representations. In addition, we devise a trainable superpixel algorithm, yielding an intermediate domain-specific image representation that can be applied to different tasks. A clustering-based superpixel algorithm is transformed into a pixel-wise classification task and superpixel training data is derived from semantic segmentation datasets. Our results demonstrate that this approach is able to improve superpixel quality consistently.