 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFerret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025
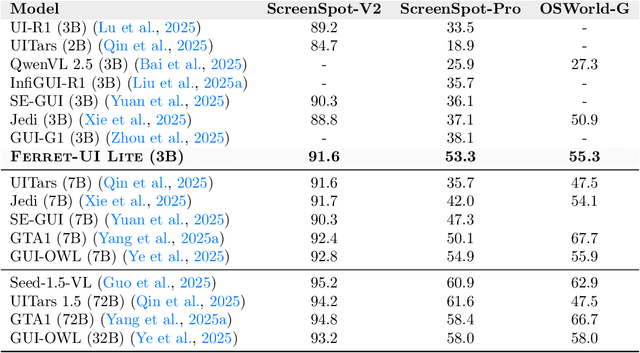
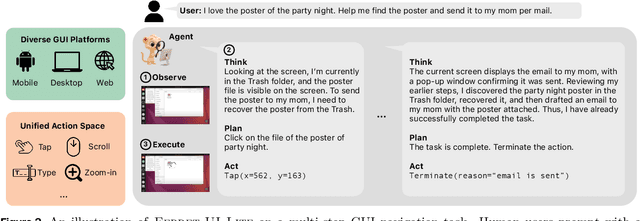
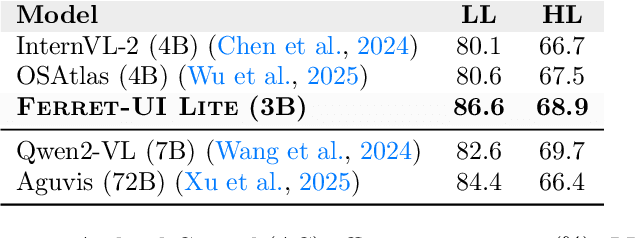
Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms
Oct 24, 2024Building a generalist model for user interface (UI) understanding is challenging due to various foundational issues, such as platform diversity, resolution variation, and data limitation. In this paper, we introduce Ferret-UI 2, a multimodal large language model (MLLM) designed for universal UI understanding across a wide range of platforms, including iPhone, Android, iPad, Webpage, and AppleTV. Building on the foundation of Ferret-UI, Ferret-UI 2 introduces three key innovations: support for multiple platform types, high-resolution perception through adaptive scaling, and advanced task training data generation powered by GPT-4o with set-of-mark visual prompting. These advancements enable Ferret-UI 2 to perform complex, user-centered interactions, making it highly versatile and adaptable for the expanding diversity of platform ecosystems. Extensive empirical experiments on referring, grounding, user-centric advanced tasks (comprising 9 subtasks $\times$ 5 platforms), GUIDE next-action prediction dataset, and GUI-World multi-platform benchmark demonstrate that Ferret-UI 2 significantly outperforms Ferret-UI, and also shows strong cross-platform transfer capabilities.
Contrastive Localized Language-Image Pre-Training
Oct 03, 2024



Contrastive Language-Image Pre-training (CLIP) has been a celebrated method for training vision encoders to generate image/text representations facilitating various applications. Recently, CLIP has been widely adopted as the vision backbone of multimodal large language models (MLLMs) to connect image inputs for language interactions. The success of CLIP as a vision-language foundation model relies on aligning web-crawled noisy text annotations at image levels. Nevertheless, such criteria may become insufficient for downstream tasks in need of fine-grained vision representations, especially when region-level understanding is demanding for MLLMs. In this paper, we improve the localization capability of CLIP with several advances. We propose a pre-training method called Contrastive Localized Language-Image Pre-training (CLOC) by complementing CLIP with region-text contrastive loss and modules. We formulate a new concept, promptable embeddings, of which the encoder produces image embeddings easy to transform into region representations given spatial hints. To support large-scale pre-training, we design a visually-enriched and spatially-localized captioning framework to effectively generate region-text pseudo-labels at scale. By scaling up to billions of annotated images, CLOC enables high-quality regional embeddings for image region recognition and retrieval tasks, and can be a drop-in replacement of CLIP to enhance MLLMs, especially on referring and grounding tasks.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Sep 30, 2024
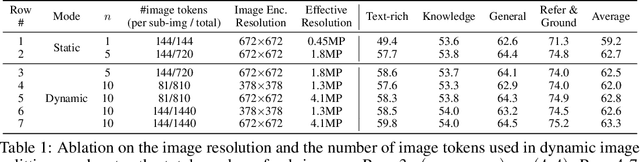

We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
Apr 08, 2024Recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate "any resolution" on top of Ferret to magnify details and leverage enhanced visual features. Specifically, each screen is divided into 2 sub-images based on the original aspect ratio (i.e., horizontal division for portrait screens and vertical division for landscape screens). Both sub-images are encoded separately before being sent to LLMs. We meticulously gather training samples from an extensive range of elementary UI tasks, such as icon recognition, find text, and widget listing. These samples are formatted for instruction-following with region annotations to facilitate precise referring and grounding. To augment the model's reasoning ability, we further compile a dataset for advanced tasks, including detailed description, perception/interaction conversations, and function inference. After training on the curated datasets, Ferret-UI exhibits outstanding comprehension of UI screens and the capability to execute open-ended instructions. For model evaluation, we establish a comprehensive benchmark encompassing all the aforementioned tasks. Ferret-UI excels not only beyond most open-source UI MLLMs, but also surpasses GPT-4V on all the elementary UI tasks.
MedGen: A Python Natural Language Processing Toolkit for Medical Text Processing
Nov 28, 2023
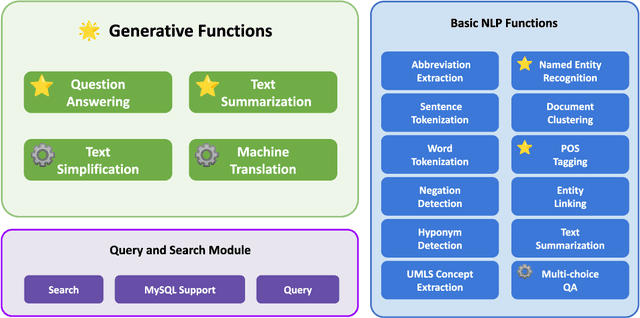
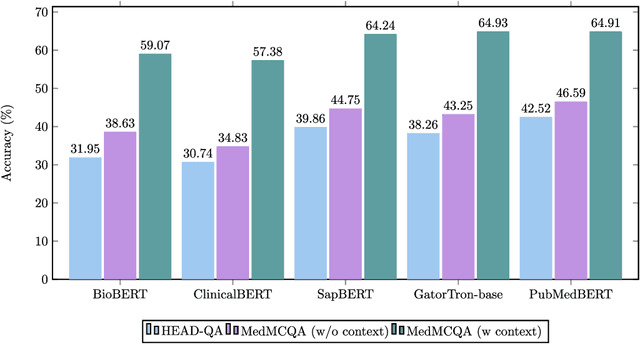
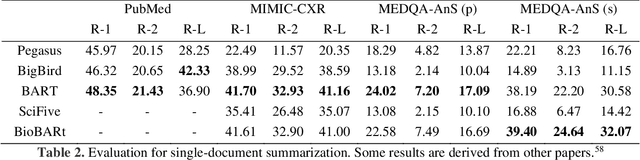
This study introduces MedGen, a comprehensive natural language processing (NLP) toolkit designed for medical text processing. MedGen is tailored for biomedical researchers and healthcare professionals with an easy-to-use, all-in-one solution that requires minimal programming expertise. It includes (1) Generative Functions: For the first time, MedGen includes four advanced generative functions: question answering, text summarization, text simplification, and machine translation; (2) Basic NLP Functions: MedGen integrates 12 essential NLP functions such as word tokenization and sentence segmentation; and (3) Query and Search Capabilities: MedGen provides user-friendly query and search functions on text corpora. We fine-tuned 32 domain-specific language models, evaluated them thoroughly on 24 established benchmarks and conducted manual reviews with clinicians. Additionally, we expanded our toolkit by introducing query and search functions, while also standardizing and integrating functions from third-party libraries. The toolkit, its models, and associated data are publicly available via https://github.com/Yale-LILY/MedGen.
EHRKit: A Python Natural Language Processing Toolkit for Electronic Health Record Texts
Apr 13, 2022


The Electronic Health Record (EHR) is an essential part of the modern medical system and impacts healthcare delivery, operations, and research. Unstructured text is attracting much attention despite structured information in the EHRs and has become an exciting research field. The success of the recent neural Natural Language Processing (NLP) method has led to a new direction for processing unstructured clinical notes. In this work, we create a python library for clinical texts, EHRKit. This library contains two main parts: MIMIC-III-specific functions and tasks specific functions. The first part introduces a list of interfaces for accessing MIMIC-III NOTEEVENTS data, including basic search, information retrieval, and information extraction. The second part integrates many third-party libraries for up to 12 off-shelf NLP tasks such as named entity recognition, summarization, machine translation, etc.
"where is this relationship going?": Understanding Relationship Trajectories in Narrative Text
Oct 29, 2020
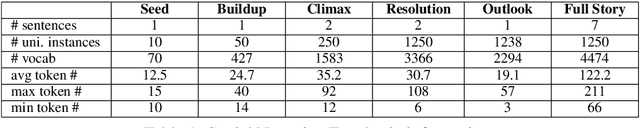
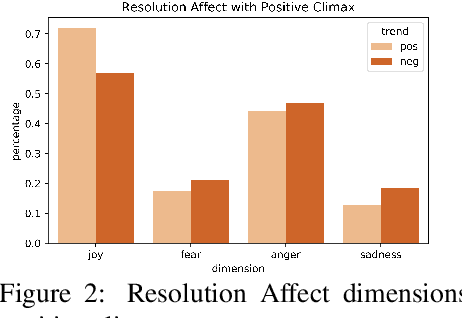

We examine a new commonsense reasoning task: given a narrative describing a social interaction that centers on two protagonists, systems make inferences about the underlying relationship trajectory. Specifically, we propose two evaluation tasks: Relationship Outlook Prediction MCQ and Resolution Prediction MCQ. In Relationship Outlook Prediction, a system maps an interaction to a relationship outlook that captures how the interaction is expected to change the relationship. In Resolution Prediction, a system attributes a given relationship outlook to a particular resolution that explains the outcome. These two tasks parallel two real-life questions that people frequently ponder upon as they navigate different social situations: "where is this relationship going?" and "how did we end up here?". To facilitate the investigation of human social relationships through these two tasks, we construct a new dataset, Social Narrative Tree, which consists of 1250 stories documenting a variety of daily social interactions. The narratives encode a multitude of social elements that interweave to give rise to rich commonsense knowledge of how relationships evolve with respect to social interactions. We establish baseline performances using language models and the accuracies are significantly lower than human performance. The results demonstrate that models need to look beyond syntactic and semantic signals to comprehend complex human relationships.