 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Code Fix Suggestions for Accessibility Issues in Mobile Apps
Aug 07, 2024Accessibility is crucial for inclusive app usability, yet developers often struggle to identify and fix app accessibility issues due to a lack of awareness, expertise, and inadequate tools. Current accessibility testing tools can identify accessibility issues but may not always provide guidance on how to address them. We introduce FixAlly, an automated tool designed to suggest source code fixes for accessibility issues detected by automated accessibility scanners. FixAlly employs a multi-agent LLM architecture to generate fix strategies, localize issues within the source code, and propose code modification suggestions to fix the accessibility issue. Our empirical study demonstrates FixAlly's capability in suggesting fixes that resolve issues found by accessibility scanners -- with an effectiveness of 77% in generating plausible fix suggestions -- and our survey of 12 iOS developers finds they would be willing to accept 69.4% of evaluated fix suggestions.
UIClip: A Data-driven Model for Assessing User Interface Design
Apr 18, 2024User interface (UI) design is a difficult yet important task for ensuring the usability, accessibility, and aesthetic qualities of applications. In our paper, we develop a machine-learned model, UIClip, for assessing the design quality and visual relevance of a UI given its screenshot and natural language description. To train UIClip, we used a combination of automated crawling, synthetic augmentation, and human ratings to construct a large-scale dataset of UIs, collated by description and ranked by design quality. Through training on the dataset, UIClip implicitly learns properties of good and bad designs by i) assigning a numerical score that represents a UI design's relevance and quality and ii) providing design suggestions. In an evaluation that compared the outputs of UIClip and other baselines to UIs rated by 12 human designers, we found that UIClip achieved the highest agreement with ground-truth rankings. Finally, we present three example applications that demonstrate how UIClip can facilitate downstream applications that rely on instantaneous assessment of UI design quality: i) UI code generation, ii) UI design tips generation, and iii) quality-aware UI example search.
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
Apr 08, 2024Recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate "any resolution" on top of Ferret to magnify details and leverage enhanced visual features. Specifically, each screen is divided into 2 sub-images based on the original aspect ratio (i.e., horizontal division for portrait screens and vertical division for landscape screens). Both sub-images are encoded separately before being sent to LLMs. We meticulously gather training samples from an extensive range of elementary UI tasks, such as icon recognition, find text, and widget listing. These samples are formatted for instruction-following with region annotations to facilitate precise referring and grounding. To augment the model's reasoning ability, we further compile a dataset for advanced tasks, including detailed description, perception/interaction conversations, and function inference. After training on the curated datasets, Ferret-UI exhibits outstanding comprehension of UI screens and the capability to execute open-ended instructions. For model evaluation, we establish a comprehensive benchmark encompassing all the aforementioned tasks. Ferret-UI excels not only beyond most open-source UI MLLMs, but also surpasses GPT-4V on all the elementary UI tasks.
AXNav: Replaying Accessibility Tests from Natural Language
Oct 13, 2023Developers and quality assurance testers often rely on manual testing to test accessibility features throughout the product lifecycle. Unfortunately, manual testing can be tedious, often has an overwhelming scope, and can be difficult to schedule amongst other development milestones. Recently, Large Language Models (LLMs) have been used for a variety of tasks including automation of UIs, however to our knowledge no one has yet explored their use in controlling assistive technologies for the purposes of supporting accessibility testing. In this paper, we explore the requirements of a natural language based accessibility testing workflow, starting with a formative study. From this we build a system that takes as input a manual accessibility test (e.g., ``Search for a show in VoiceOver'') and uses an LLM combined with pixel-based UI Understanding models to execute the test and produce a chaptered, navigable video. In each video, to help QA testers we apply heuristics to detect and flag accessibility issues (e.g., Text size not increasing with Large Text enabled, VoiceOver navigation loops). We evaluate this system through a 10 participant user study with accessibility QA professionals who indicated that the tool would be very useful in their current work and performed tests similarly to how they would manually test the features. The study also reveals insights for future work on using LLMs for accessibility testing.
ILuvUI: Instruction-tuned LangUage-Vision modeling of UIs from Machine Conversations
Oct 07, 2023Multimodal Vision-Language Models (VLMs) enable powerful applications from their fused understanding of images and language, but many perform poorly on UI tasks due to the lack of UI training data. In this paper, we adapt a recipe for generating paired text-image training data for VLMs to the UI domain by combining existing pixel-based methods with a Large Language Model (LLM). Unlike prior art, our method requires no human-provided annotations, and it can be applied to any dataset of UI screenshots. We generate a dataset of 335K conversational examples paired with UIs that cover Q&A, UI descriptions, and planning, and use it to fine-tune a conversational VLM for UI tasks. To assess the performance of our model, we benchmark it on UI element detection tasks, evaluate response quality, and showcase its applicability to multi-step UI navigation and planning.
Scout: Rapid Exploration of Interface Layout Alternatives through High-Level Design Constraints
Jan 15, 2020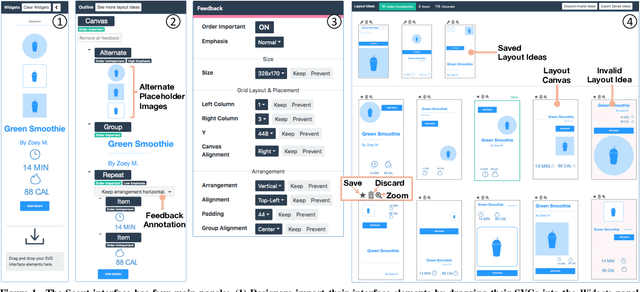
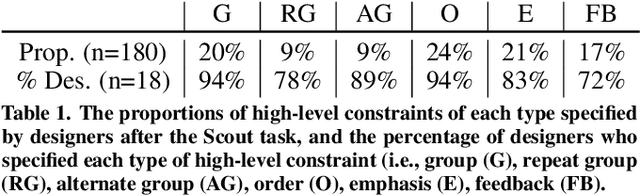

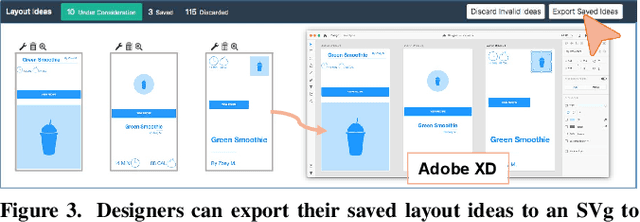
Although exploring alternatives is fundamental to creating better interface designs, current processes for creating alternatives are generally manual, limiting the alternatives a designer can explore. We present Scout, a system that helps designers rapidly explore alternatives through mixed-initiative interaction with high-level constraints and design feedback. Prior constraint-based layout systems use low-level spatial constraints and generally produce a single design. Tosupport designer exploration of alternatives, Scout introduces high-level constraints based on design concepts (e.g.,~semantic structure, emphasis, order) and formalizes them into low-level spatial constraints that a solver uses to generate potential layouts. In an evaluation with 18 interface designers, we found that Scout: (1) helps designers create more spatially diverse layouts with similar quality to those created with a baseline tool and (2) can help designers avoid a linear design process and quickly ideate layouts they do not believe they would have thought of on their own.
* 13 pages, 8 figures, ACM CHI Full Paper (2020)