 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUICoder: Finetuning Large Language Models to Generate User Interface Code through Automated Feedback
Jun 11, 2024Large language models (LLMs) struggle to consistently generate UI code that compiles and produces visually relevant designs. Existing approaches to improve generation rely on expensive human feedback or distilling a proprietary model. In this paper, we explore the use of automated feedback (compilers and multi-modal models) to guide LLMs to generate high-quality UI code. Our method starts with an existing LLM and iteratively produces improved models by self-generating a large synthetic dataset using an original model, applying automated tools to aggressively filter, score, and de-duplicate the data into a refined higher quality dataset. The original LLM is improved by finetuning on this refined dataset. We applied our approach to several open-source LLMs and compared the resulting performance to baseline models with both automated metrics and human preferences. Our evaluation shows the resulting models outperform all other downloadable baselines and approach the performance of larger proprietary models.
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
Apr 08, 2024Recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate "any resolution" on top of Ferret to magnify details and leverage enhanced visual features. Specifically, each screen is divided into 2 sub-images based on the original aspect ratio (i.e., horizontal division for portrait screens and vertical division for landscape screens). Both sub-images are encoded separately before being sent to LLMs. We meticulously gather training samples from an extensive range of elementary UI tasks, such as icon recognition, find text, and widget listing. These samples are formatted for instruction-following with region annotations to facilitate precise referring and grounding. To augment the model's reasoning ability, we further compile a dataset for advanced tasks, including detailed description, perception/interaction conversations, and function inference. After training on the curated datasets, Ferret-UI exhibits outstanding comprehension of UI screens and the capability to execute open-ended instructions. For model evaluation, we establish a comprehensive benchmark encompassing all the aforementioned tasks. Ferret-UI excels not only beyond most open-source UI MLLMs, but also surpasses GPT-4V on all the elementary UI tasks.
AXNav: Replaying Accessibility Tests from Natural Language
Oct 13, 2023Developers and quality assurance testers often rely on manual testing to test accessibility features throughout the product lifecycle. Unfortunately, manual testing can be tedious, often has an overwhelming scope, and can be difficult to schedule amongst other development milestones. Recently, Large Language Models (LLMs) have been used for a variety of tasks including automation of UIs, however to our knowledge no one has yet explored their use in controlling assistive technologies for the purposes of supporting accessibility testing. In this paper, we explore the requirements of a natural language based accessibility testing workflow, starting with a formative study. From this we build a system that takes as input a manual accessibility test (e.g., ``Search for a show in VoiceOver'') and uses an LLM combined with pixel-based UI Understanding models to execute the test and produce a chaptered, navigable video. In each video, to help QA testers we apply heuristics to detect and flag accessibility issues (e.g., Text size not increasing with Large Text enabled, VoiceOver navigation loops). We evaluate this system through a 10 participant user study with accessibility QA professionals who indicated that the tool would be very useful in their current work and performed tests similarly to how they would manually test the features. The study also reveals insights for future work on using LLMs for accessibility testing.
ILuvUI: Instruction-tuned LangUage-Vision modeling of UIs from Machine Conversations
Oct 07, 2023Multimodal Vision-Language Models (VLMs) enable powerful applications from their fused understanding of images and language, but many perform poorly on UI tasks due to the lack of UI training data. In this paper, we adapt a recipe for generating paired text-image training data for VLMs to the UI domain by combining existing pixel-based methods with a Large Language Model (LLM). Unlike prior art, our method requires no human-provided annotations, and it can be applied to any dataset of UI screenshots. We generate a dataset of 335K conversational examples paired with UIs that cover Q&A, UI descriptions, and planning, and use it to fine-tune a conversational VLM for UI tasks. To assess the performance of our model, we benchmark it on UI element detection tasks, evaluate response quality, and showcase its applicability to multi-step UI navigation and planning.
Predicting and Explaining Mobile UI Tappability with Vision Modeling and Saliency Analysis
Apr 05, 2022
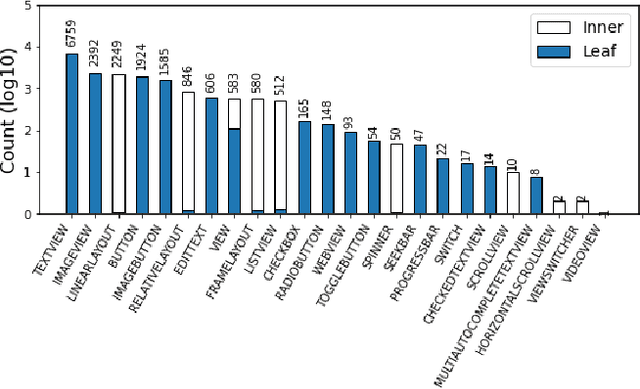
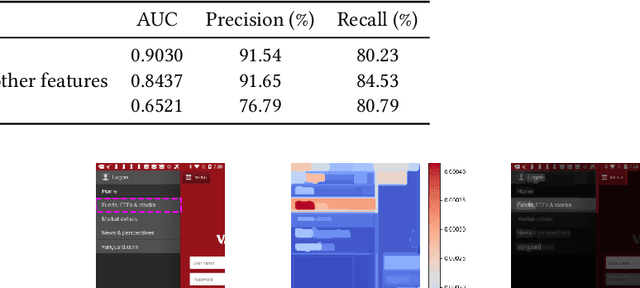
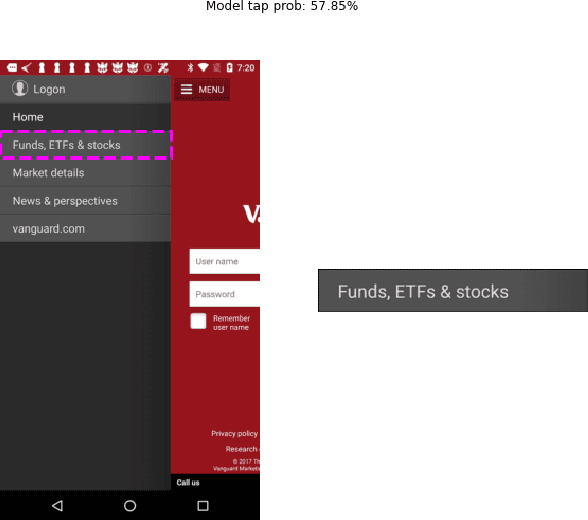
We use a deep learning based approach to predict whether a selected element in a mobile UI screenshot will be perceived by users as tappable, based on pixels only instead of view hierarchies required by previous work. To help designers better understand model predictions and to provide more actionable design feedback than predictions alone, we additionally use ML interpretability techniques to help explain the output of our model. We use XRAI to highlight areas in the input screenshot that most strongly influence the tappability prediction for the selected region, and use k-Nearest Neighbors to present the most similar mobile UIs from the dataset with opposing influences on tappability perception.
IMACS: Image Model Attribution Comparison Summaries
Jan 26, 2022



Developing a suitable Deep Neural Network (DNN) often requires significant iteration, where different model versions are evaluated and compared. While metrics such as accuracy are a powerful means to succinctly describe a model's performance across a dataset or to directly compare model versions, practitioners often wish to gain a deeper understanding of the factors that influence a model's predictions. Interpretability techniques such as gradient-based methods and local approximations can be used to examine small sets of inputs in fine detail, but it can be hard to determine if results from small sets generalize across a dataset. We introduce IMACS, a method that combines gradient-based model attributions with aggregation and visualization techniques to summarize differences in attributions between two DNN image models. More specifically, IMACS extracts salient input features from an evaluation dataset, clusters them based on similarity, then visualizes differences in model attributions for similar input features. In this work, we introduce a framework for aggregating, summarizing, and comparing the attribution information for two models across a dataset; present visualizations that highlight differences between 2 image classification models; and show how our technique can uncover behavioral differences caused by domain shift between two models trained on satellite images.
Sketch-based Creativity Support Tools using Deep Learning
Nov 19, 2021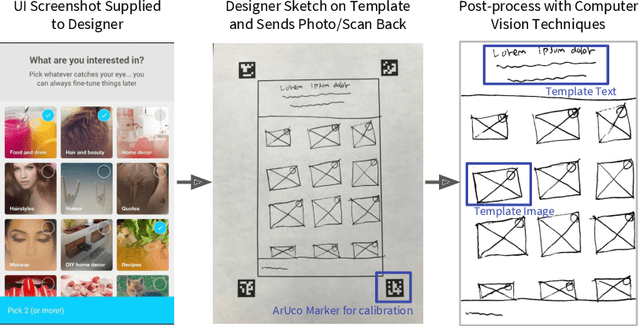

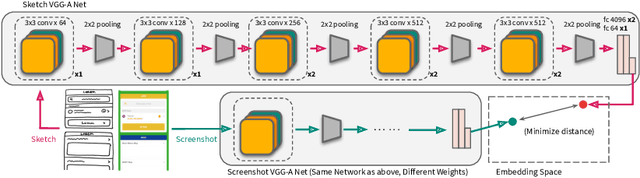
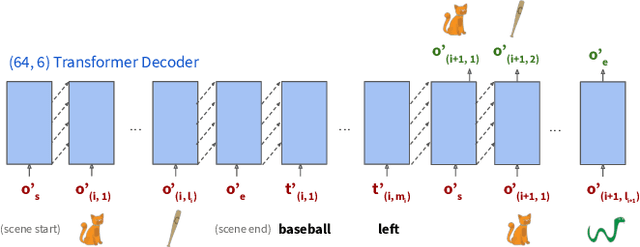
Sketching is a natural and effective visual communication medium commonly used in creative processes. Recent developments in deep-learning models drastically improved machines' ability in understanding and generating visual content. An exciting area of development explores deep-learning approaches used to model human sketches, opening opportunities for creative applications. This chapter describes three fundamental steps in developing deep-learning-driven creativity support tools that consumes and generates sketches: 1) a data collection effort that generated a new paired dataset between sketches and mobile user interfaces; 2) a sketch-based user interface retrieval system adapted from state-of-the-art computer vision techniques; and, 3) a conversational sketching system that supports the novel interaction of a natural-language-based sketch/critique authoring process. In this chapter, we survey relevant prior work in both the deep-learning and human-computer-interaction communities, document the data collection process and the systems' architectures in detail, present qualitative and quantitative results, and paint the landscape of several future research directions in this exciting area.
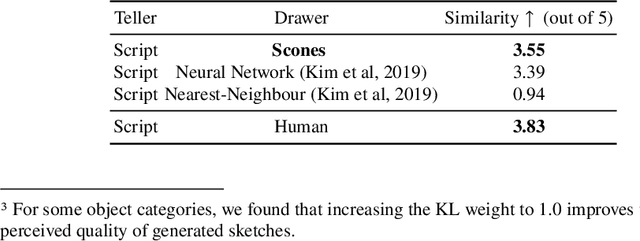
Scones: Towards Conversational Authoring of Sketches
May 12, 2020

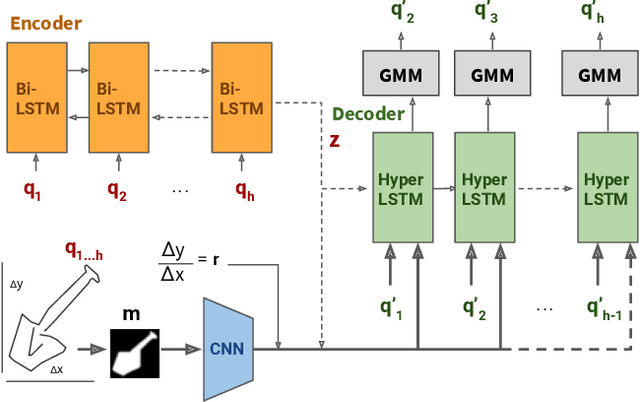
Iteratively refining and critiquing sketches are crucial steps to developing effective designs. We introduce Scones, a mixed-initiative, machine-learning-driven system that enables users to iteratively author sketches from text instructions. Scones is a novel deep-learning-based system that iteratively generates scenes of sketched objects composed with semantic specifications from natural language. Scones exceeds state-of-the-art performance on a text-based scene modification task, and introduces a mask-conditioned sketching model that can generate sketches with poses specified by high-level scene information. In an exploratory user evaluation of Scones, participants reported enjoying an iterative drawing task with Scones, and suggested additional features for further applications. We believe Scones is an early step towards automated, intelligent systems that support human-in-the-loop applications for communicating ideas through sketching in art and design.