 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBISCUIT: Scaffolding LLM-Generated Code with Ephemeral UIs in Computational Notebooks
Apr 12, 2024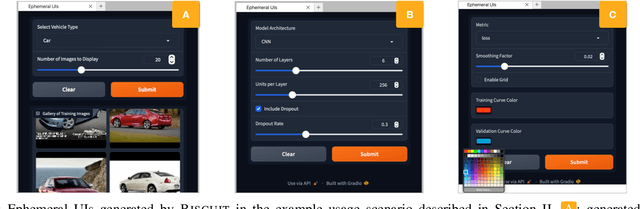
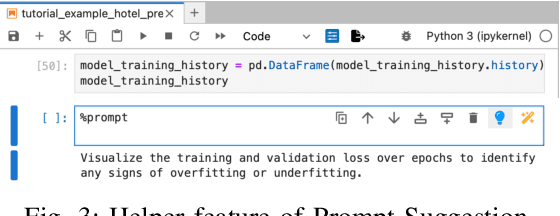
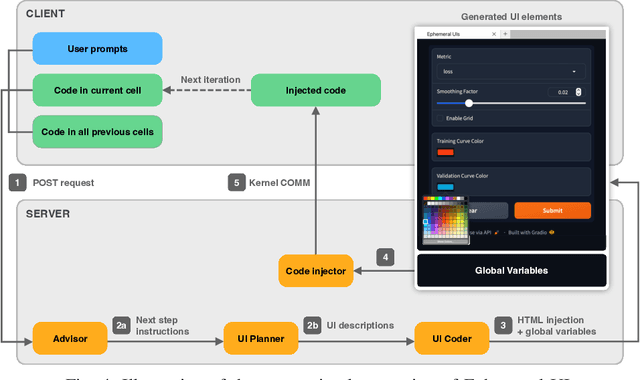
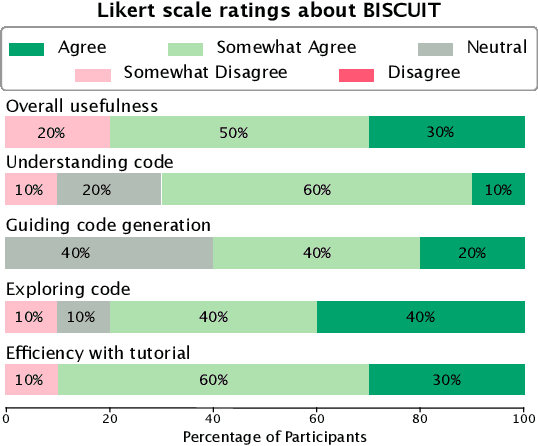
Novices frequently engage with machine learning tutorials in computational notebooks and have been adopting code generation technologies based on large language models (LLMs). However, they encounter difficulties in understanding and working with code produced by LLMs. To mitigate these challenges, we introduce a novel workflow into computational notebooks that augments LLM-based code generation with an additional ephemeral UI step, offering users UI-based scaffolds as an intermediate stage between user prompts and code generation. We present this workflow in BISCUIT, an extension for JupyterLab that provides users with ephemeral UIs generated by LLMs based on the context of their code and intentions, scaffolding users to understand, guide, and explore with LLM-generated code. Through a user study where 10 novices used BISCUIT for machine learning tutorials, we discover that BISCUIT offers user semantic representation of code to aid their understanding, reduces the complexity of prompt engineering, and creates a playground for users to explore different variables and iterate on their ideas. We discuss the implications of our findings for UI-centric interactive paradigm in code generation LLMs.
AXNav: Replaying Accessibility Tests from Natural Language
Oct 13, 2023Developers and quality assurance testers often rely on manual testing to test accessibility features throughout the product lifecycle. Unfortunately, manual testing can be tedious, often has an overwhelming scope, and can be difficult to schedule amongst other development milestones. Recently, Large Language Models (LLMs) have been used for a variety of tasks including automation of UIs, however to our knowledge no one has yet explored their use in controlling assistive technologies for the purposes of supporting accessibility testing. In this paper, we explore the requirements of a natural language based accessibility testing workflow, starting with a formative study. From this we build a system that takes as input a manual accessibility test (e.g., ``Search for a show in VoiceOver'') and uses an LLM combined with pixel-based UI Understanding models to execute the test and produce a chaptered, navigable video. In each video, to help QA testers we apply heuristics to detect and flag accessibility issues (e.g., Text size not increasing with Large Text enabled, VoiceOver navigation loops). We evaluate this system through a 10 participant user study with accessibility QA professionals who indicated that the tool would be very useful in their current work and performed tests similarly to how they would manually test the features. The study also reveals insights for future work on using LLMs for accessibility testing.
An Exploration of Post-Editing Effectiveness in Text Summarization
Jun 13, 2022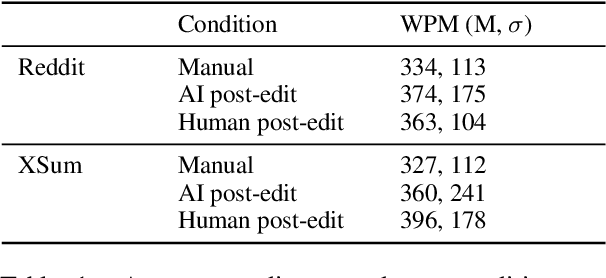
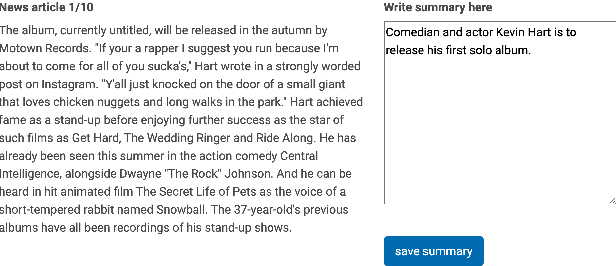
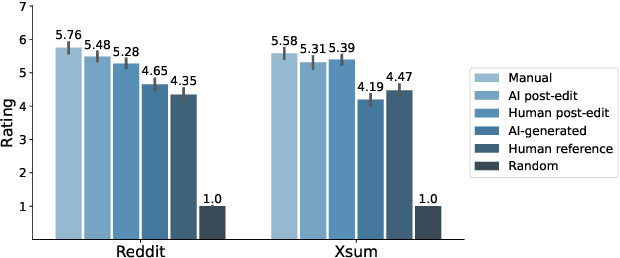

Automatic summarization methods are efficient but can suffer from low quality. In comparison, manual summarization is expensive but produces higher quality. Can humans and AI collaborate to improve summarization performance? In similar text generation tasks (e.g., machine translation), human-AI collaboration in the form of "post-editing" AI-generated text reduces human workload and improves the quality of AI output. Therefore, we explored whether post-editing offers advantages in text summarization. Specifically, we conducted an experiment with 72 participants, comparing post-editing provided summaries with manual summarization for summary quality, human efficiency, and user experience on formal (XSum news) and informal (Reddit posts) text. This study sheds valuable insights on when post-editing is useful for text summarization: it helped in some cases (e.g., when participants lacked domain knowledge) but not in others (e.g., when provided summaries include inaccurate information). Participants' different editing strategies and needs for assistance offer implications for future human-AI summarization systems.