 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Mamba's Selective Memory using Auto-Encoders
Dec 17, 2025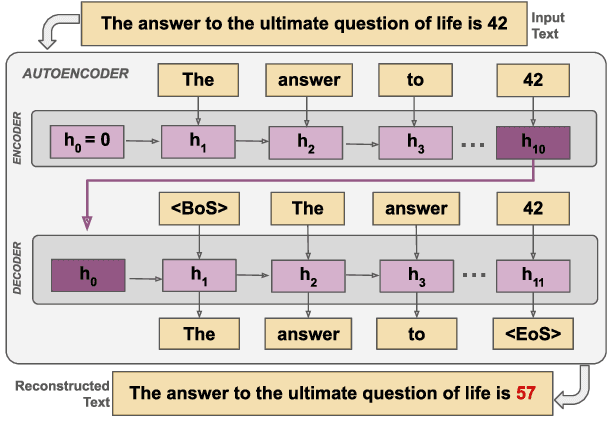
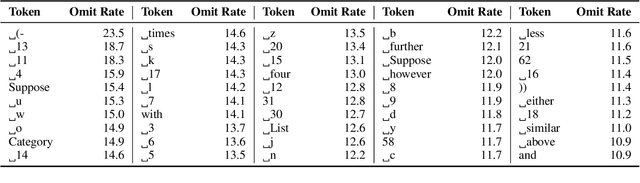
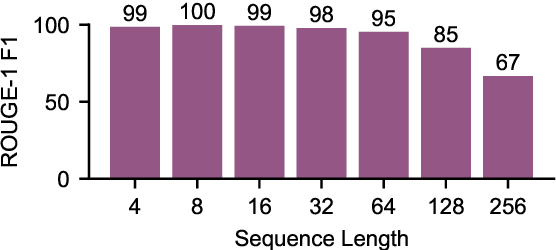
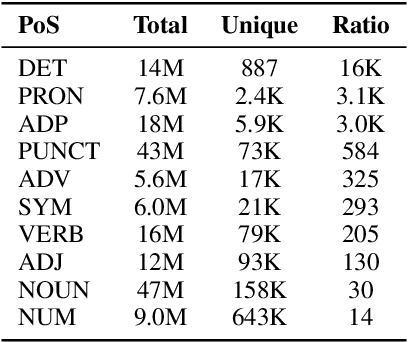
State space models (SSMs) are a promising alternative to transformers for language modeling because they use fixed memory during inference. However, this fixed memory usage requires some information loss in the hidden state when processing long sequences. While prior work has studied the sequence length at which this information loss occurs, it does not characterize the types of information SSM language models (LMs) tend to forget. In this paper, we address this knowledge gap by identifying the types of tokens (e.g., parts of speech, named entities) and sequences (e.g., code, math problems) that are more frequently forgotten by SSM LMs. We achieve this by training an auto-encoder to reconstruct sequences from the SSM's hidden state, and measure information loss by comparing inputs with their reconstructions. We perform experiments using the Mamba family of SSM LMs (130M--1.4B) on sequences ranging from 4--256 tokens. Our results show significantly higher rates of information loss on math-related tokens (e.g., numbers, variables), mentions of organization entities, and alternative dialects to Standard American English. We then examine the frequency that these tokens appear in Mamba's pretraining data and find that less prevalent tokens tend to be the ones Mamba is most likely to forget. By identifying these patterns, our work provides clear direction for future research to develop methods that better control Mamba's ability to retain important information.
Uchaguzi-2022: A Dataset of Citizen Reports on the 2022 Kenyan Election
Dec 17, 2024



Online reporting platforms have enabled citizens around the world to collectively share their opinions and report in real time on events impacting their local communities. Systematically organizing (e.g., categorizing by attributes) and geotagging large amounts of crowdsourced information is crucial to ensuring that accurate and meaningful insights can be drawn from this data and used by policy makers to bring about positive change. These tasks, however, typically require extensive manual annotation efforts. In this paper we present Uchaguzi-2022, a dataset of 14k categorized and geotagged citizen reports related to the 2022 Kenyan General Election containing mentions of election-related issues such as official misconduct, vote count irregularities, and acts of violence. We use this dataset to investigate whether language models can assist in scalably categorizing and geotagging reports, thus highlighting its potential application in the AI for Social Good space.
Little Giants: Exploring the Potential of Small LLMs as Evaluation Metrics in Summarization in the Eval4NLP 2023 Shared Task
Nov 01, 2023



This paper describes and analyzes our participation in the 2023 Eval4NLP shared task, which focuses on assessing the effectiveness of prompt-based techniques to empower Large Language Models to handle the task of quality estimation, particularly in the context of evaluating machine translations and summaries. We conducted systematic experiments with various prompting techniques, including standard prompting, prompts informed by annotator instructions, and innovative chain-of-thought prompting. In addition, we integrated these approaches with zero-shot and one-shot learning methods to maximize the efficacy of our evaluation procedures. Our work reveals that combining these approaches using a "small", open source model (orca_mini_v3_7B) yields competitive results.
Harnessing the Power of LLMs: Evaluating Human-AI Text Co-Creation through the Lens of News Headline Generation
Oct 18, 2023



To explore how humans can best leverage LLMs for writing and how interacting with these models affects feelings of ownership and trust in the writing process, we compared common human-AI interaction types (e.g., guiding system, selecting from system outputs, post-editing outputs) in the context of LLM-assisted news headline generation. While LLMs alone can generate satisfactory news headlines, on average, human control is needed to fix undesirable model outputs. Of the interaction methods, guiding and selecting model output added the most benefit with the lowest cost (in time and effort). Further, AI assistance did not harm participants' perception of control compared to freeform editing.
Event Extraction as Question Generation and Answering
Jul 10, 2023Recent work on Event Extraction has reframed the task as Question Answering (QA), with promising results. The advantage of this approach is that it addresses the error propagation issue found in traditional token-based classification approaches by directly predicting event arguments without extracting candidates first. However, the questions are typically based on fixed templates and they rarely leverage contextual information such as relevant arguments. In addition, prior QA-based approaches have difficulty handling cases where there are multiple arguments for the same role. In this paper, we propose QGA-EE, which enables a Question Generation (QG) model to generate questions that incorporate rich contextual information instead of using fixed templates. We also propose dynamic templates to assist the training of QG model. Experiments show that QGA-EE outperforms all prior single-task-based models on the ACE05 English dataset.
A New Task and Dataset on Detecting Attacks on Human Rights Defenders
Jun 30, 2023



The ability to conduct retrospective analyses of attacks on human rights defenders over time and by location is important for humanitarian organizations to better understand historical or ongoing human rights violations and thus better manage the global impact of such events. We hypothesize that NLP can support such efforts by quickly processing large collections of news articles to detect and summarize the characteristics of attacks on human rights defenders. To that end, we propose a new dataset for detecting Attacks on Human Rights Defenders (HRDsAttack) consisting of crowdsourced annotations on 500 online news articles. The annotations include fine-grained information about the type and location of the attacks, as well as information about the victim(s). We demonstrate the usefulness of the dataset by using it to train and evaluate baseline models on several sub-tasks to predict the annotated characteristics.
BUMP: A Benchmark of Unfaithful Minimal Pairs for Meta-Evaluation of Faithfulness Metrics
Dec 20, 2022
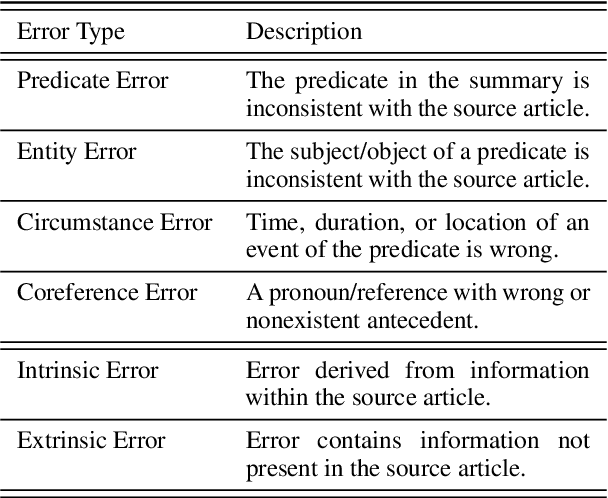
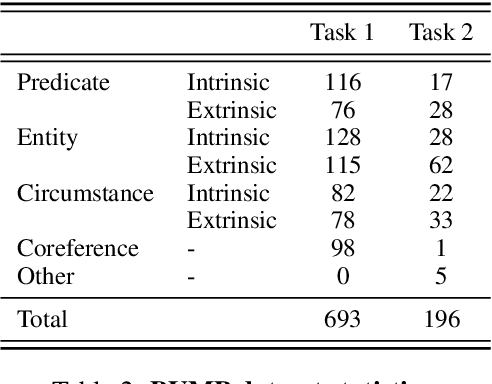

The proliferation of automatic faithfulness metrics for summarization has produced a need for benchmarks to evaluate them. While existing benchmarks measure the correlation with human judgements of faithfulness on model-generated summaries, they are insufficient for diagnosing whether metrics are: 1) consistent, i.e., decrease as errors are introduced into a summary, 2) effective on human-written texts, and 3) sensitive to different error types (as summaries can contain multiple errors). To address these needs, we present a benchmark of unfaithful minimal pairs (BUMP), a dataset of 889 human-written, minimally different summary pairs, where a single error (from an ontology of 7 types) is introduced to a summary from the CNN/DailyMail dataset to produce an unfaithful summary. We find BUMP complements existing benchmarks in a number of ways: 1) the summaries in BUMP are harder to discriminate and less probable under SOTA summarization models, 2) BUMP enables measuring the consistency of metrics, and reveals that the most discriminative metrics tend not to be the most consistent, 3) BUMP enables the measurement of metrics' performance on individual error types and highlights areas of weakness for future work.
CrisisLTLSum: A Benchmark for Local Crisis Event Timeline Extraction and Summarization
Oct 25, 2022



Social media has increasingly played a key role in emergency response: first responders can use public posts to better react to ongoing crisis events and deploy the necessary resources where they are most needed. Timeline extraction and abstractive summarization are critical technical tasks to leverage large numbers of social media posts about events. Unfortunately, there are few datasets for benchmarking technical approaches for those tasks. This paper presents CrisisLTLSum, the largest dataset of local crisis event timelines available to date. CrisisLTLSum contains 1,000 crisis event timelines across four domains: wildfires, local fires, traffic, and storms. We built CrisisLTLSum using a semi-automated cluster-then-refine approach to collect data from the public Twitter stream. Our initial experiments indicate a significant gap between the performance of strong baselines compared to the human performance on both tasks. Our dataset, code, and models are publicly available.
An Exploration of Post-Editing Effectiveness in Text Summarization
Jun 13, 2022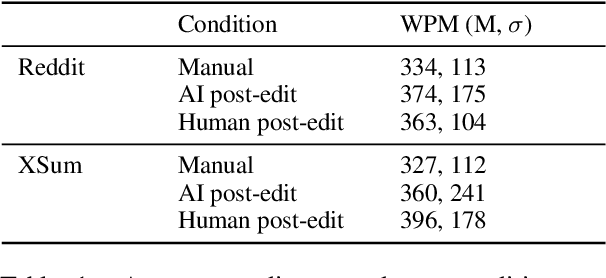
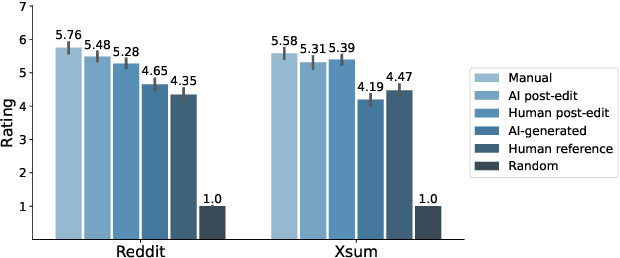

Automatic summarization methods are efficient but can suffer from low quality. In comparison, manual summarization is expensive but produces higher quality. Can humans and AI collaborate to improve summarization performance? In similar text generation tasks (e.g., machine translation), human-AI collaboration in the form of "post-editing" AI-generated text reduces human workload and improves the quality of AI output. Therefore, we explored whether post-editing offers advantages in text summarization. Specifically, we conducted an experiment with 72 participants, comparing post-editing provided summaries with manual summarization for summary quality, human efficiency, and user experience on formal (XSum news) and informal (Reddit posts) text. This study sheds valuable insights on when post-editing is useful for text summarization: it helped in some cases (e.g., when participants lacked domain knowledge) but not in others (e.g., when provided summaries include inaccurate information). Participants' different editing strategies and needs for assistance offer implications for future human-AI summarization systems.
GTN-ED: Event Detection Using Graph Transformer Networks
May 05, 2021

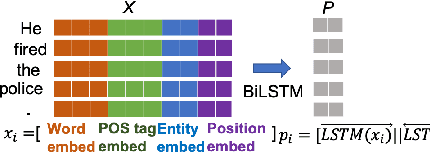

Recent works show that the graph structure of sentences, generated from dependency parsers, has potential for improving event detection. However, they often only leverage the edges (dependencies) between words, and discard the dependency labels (e.g., nominal-subject), treating the underlying graph edges as homogeneous. In this work, we propose a novel framework for incorporating both dependencies and their labels using a recently proposed technique called Graph Transformer Networks (GTN). We integrate GTNs to leverage dependency relations on two existing homogeneous-graph-based models, and demonstrate an improvement in the F1 score on the ACE dataset.