 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLTime: A Cross-Lingual Knowledge Transfer Framework for Temporal Expression Extraction
May 03, 2022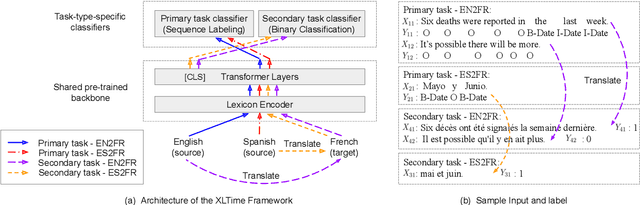
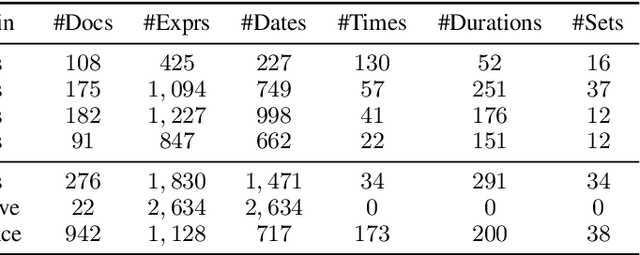
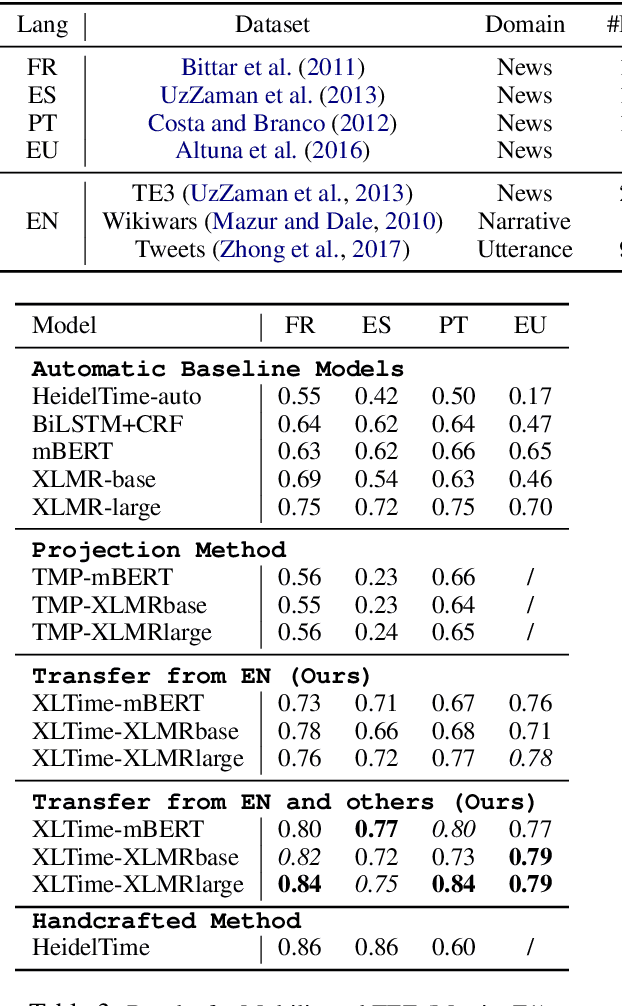
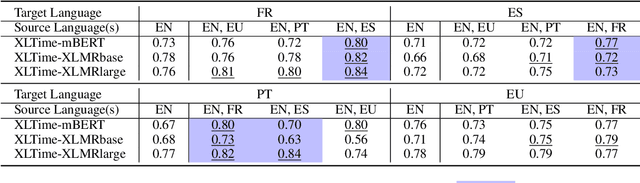
Temporal Expression Extraction (TEE) is essential for understanding time in natural language. It has applications in Natural Language Processing (NLP) tasks such as question answering, information retrieval, and causal inference. To date, work in this area has mostly focused on English as there is a scarcity of labeled data for other languages. We propose XLTime, a novel framework for multilingual TEE. XLTime works on top of pre-trained language models and leverages multi-task learning to prompt cross-language knowledge transfer both from English and within the non-English languages. XLTime alleviates problems caused by a shortage of data in the target language. We apply XLTime with different language models and show that it outperforms the previous automatic SOTA methods on French, Spanish, Portuguese, and Basque, by large margins. XLTime also closes the gap considerably on the handcrafted HeidelTime method.
GTN-ED: Event Detection Using Graph Transformer Networks
May 05, 2021

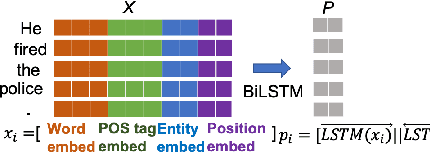

Recent works show that the graph structure of sentences, generated from dependency parsers, has potential for improving event detection. However, they often only leverage the edges (dependencies) between words, and discard the dependency labels (e.g., nominal-subject), treating the underlying graph edges as homogeneous. In this work, we propose a novel framework for incorporating both dependencies and their labels using a recently proposed technique called Graph Transformer Networks (GTN). We integrate GTNs to leverage dependency relations on two existing homogeneous-graph-based models, and demonstrate an improvement in the F1 score on the ACE dataset.
Clustering of Social Media Messages for Humanitarian Aid Response during Crisis
Jul 23, 2020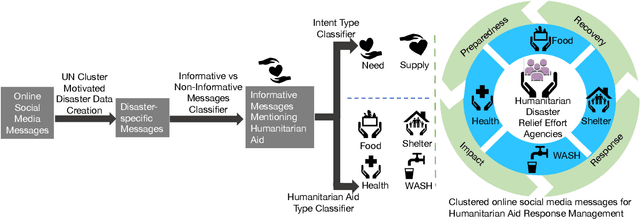
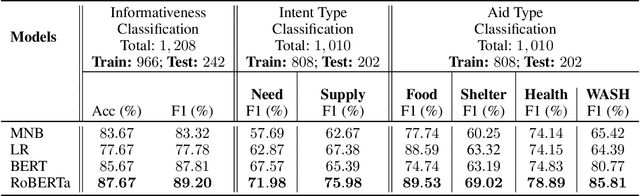


Social media has quickly grown into an essential tool for people to communicate and express their needs during crisis events. Prior work in analyzing social media data for crisis management has focused primarily on automatically identifying actionable (or, informative) crisis-related messages. In this work, we show that recent advances in Deep Learning and Natural Language Processing outperform prior approaches for the task of classifying informativeness and encourage the field to adopt them for their research or even deployment. We also extend these methods to two sub-tasks of informativeness and find that the Deep Learning methods are effective here as well.
Models for Capturing Temporal Smoothness in Evolving Networks for Learning Latent Representation of Nodes
Apr 16, 2018
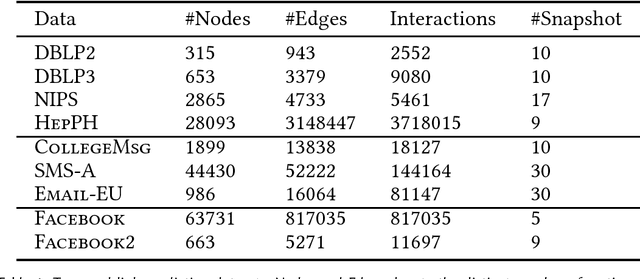
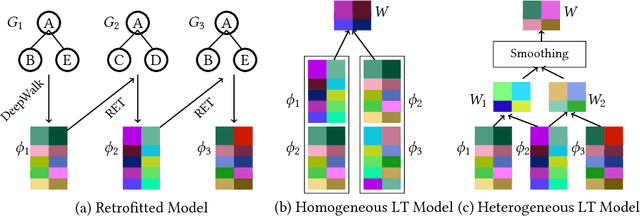

In a dynamic network, the neighborhood of the vertices evolve across different temporal snapshots of the network. Accurate modeling of this temporal evolution can help solve complex tasks involving real-life social and interaction networks. However, existing models for learning latent representation are inadequate for obtaining the representation vectors of the vertices for different time-stamps of a dynamic network in a meaningful way. In this paper, we propose latent representation learning models for dynamic networks which overcome the above limitation by considering two different kinds of temporal smoothness: (i) retrofitted, and (ii) linear transformation. The retrofitted model tracks the representation vector of a vertex over time, facilitating vertex-based temporal analysis of a network. On the other hand, linear transformation based model provides a smooth transition operator which maps the representation vectors of all vertices from one temporal snapshot to the next (unobserved) snapshot-this facilitates prediction of the state of a network in a future time-stamp. We validate the performance of our proposed models by employing them for solving the temporal link prediction task. Experiments on 9 real-life networks from various domains validate that the proposed models are significantly better than the existing models for predicting the dynamics of an evolving network.
A large scale study of SVM based methods for abstract screening in systematic reviews
Jan 16, 2018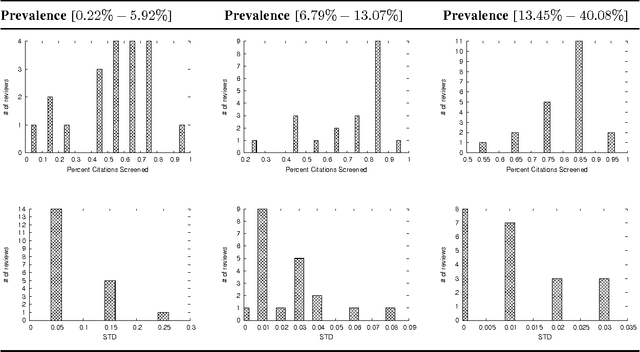
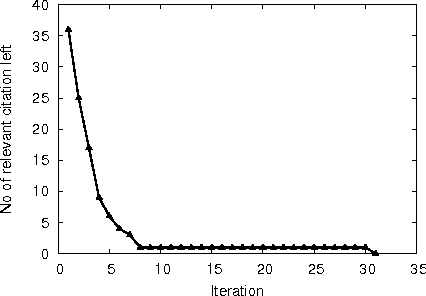


A major task in systematic reviews is abstract screening, i.e., excluding, often hundreds or thousand of, irrelevant citations returned from a database search based on titles and abstracts. Thus, a systematic review platform that can automate the abstract screening process is of huge importance. Several methods have been proposed for this task. However, it is very hard to clearly understand the applicability of these methods in a systematic review platform because of the following challenges: (1) the use of non-overlapping metrics for the evaluation of the proposed methods, (2) usage of features that are very hard to collect, (3) using a small set of reviews for the evaluation, and (4) no solid statistical testing or equivalence grouping of the methods. In this paper, we use feature representation that can be extracted per citation. We evaluate SVM-based methods (commonly used) on a large set of reviews ($61$) and metrics ($11$) to provide equivalence grouping of methods based on a solid statistical test. Our analysis also includes a strong variability of the metrics using $500$x$2$ cross validation. While some methods shine for different metrics and for different datasets, there is no single method that dominates the pack. Furthermore, we observe that in some cases relevant (included) citations can be found after screening only 15-20% of them via a certainty based sampling. A few included citations present outlying characteristics and can only be found after a very large number of screening steps. Finally, we present an ensemble algorithm for producing a $5$-star rating of citations based on their relevance. Such algorithm combines the best methods from our evaluation and through its $5$-star rating outputs a more easy-to-consume prediction.
Dis-S2V: Discourse Informed Sen2Vec
Oct 25, 2016



Vector representation of sentences is important for many text processing tasks that involve clustering, classifying, or ranking sentences. Recently, distributed representation of sentences learned by neural models from unlabeled data has been shown to outperform the traditional bag-of-words representation. However, most of these learning methods consider only the content of a sentence and disregard the relations among sentences in a discourse by and large. In this paper, we propose a series of novel models for learning latent representations of sentences (Sen2Vec) that consider the content of a sentence as well as inter-sentence relations. We first represent the inter-sentence relations with a language network and then use the network to induce contextual information into the content-based Sen2Vec models. Two different approaches are introduced to exploit the information in the network. Our first approach retrofits (already trained) Sen2Vec vectors with respect to the network in two different ways: (1) using the adjacency relations of a node, and (2) using a stochastic sampling method which is more flexible in sampling neighbors of a node. The second approach uses a regularizer to encode the information in the network into the existing Sen2Vec model. Experimental results show that our proposed models outperform existing methods in three fundamental information system tasks demonstrating the effectiveness of our approach. The models leverage the computational power of multi-core CPUs to achieve fine-grained computational efficiency. We make our code publicly available upon acceptance.