 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLTime: A Cross-Lingual Knowledge Transfer Framework for Temporal Expression Extraction
May 03, 2022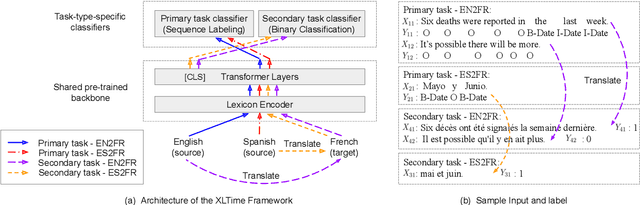
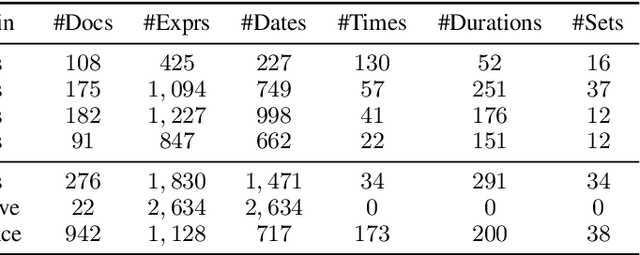
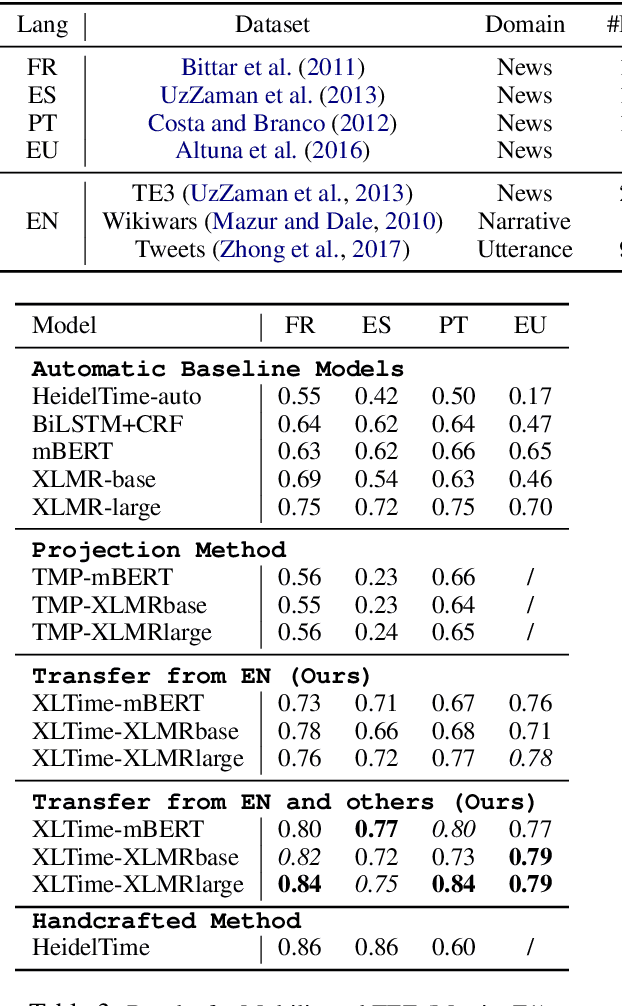
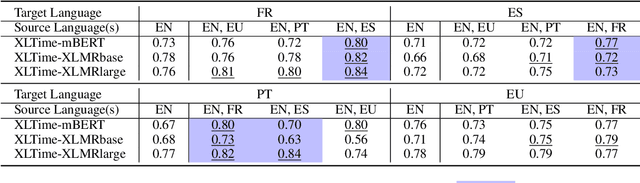
Temporal Expression Extraction (TEE) is essential for understanding time in natural language. It has applications in Natural Language Processing (NLP) tasks such as question answering, information retrieval, and causal inference. To date, work in this area has mostly focused on English as there is a scarcity of labeled data for other languages. We propose XLTime, a novel framework for multilingual TEE. XLTime works on top of pre-trained language models and leverages multi-task learning to prompt cross-language knowledge transfer both from English and within the non-English languages. XLTime alleviates problems caused by a shortage of data in the target language. We apply XLTime with different language models and show that it outperforms the previous automatic SOTA methods on French, Spanish, Portuguese, and Basque, by large margins. XLTime also closes the gap considerably on the handcrafted HeidelTime method.
Unsupervised Detection of Sub-events in Large Scale Disasters
Dec 13, 2019
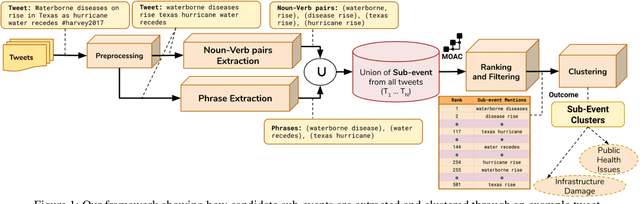
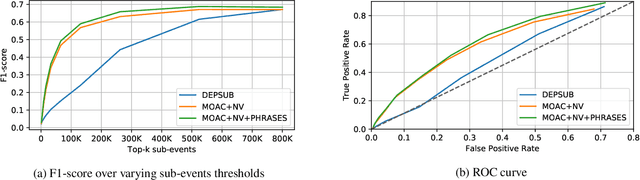

Social media plays a major role during and after major natural disasters (e.g., hurricanes, large-scale fires, etc.), as people ``on the ground'' post useful information on what is actually happening. Given the large amounts of posts, a major challenge is identifying the information that is useful and actionable. Emergency responders are largely interested in finding out what events are taking place so they can properly plan and deploy resources. In this paper we address the problem of automatically identifying important sub-events (within a large-scale emergency ``event'', such as a hurricane). In particular, we present a novel, unsupervised learning framework to detect sub-events in Tweets for retrospective crisis analysis. We first extract noun-verb pairs and phrases from raw tweets as sub-event candidates. Then, we learn a semantic embedding of extracted noun-verb pairs and phrases, and rank them against a crisis-specific ontology. We filter out noisy and irrelevant information then cluster the noun-verb pairs and phrases so that the top-ranked ones describe the most important sub-events. Through quantitative experiments on two large crisis data sets (Hurricane Harvey and the 2015 Nepal Earthquake), we demonstrate the effectiveness of our approach over the state-of-the-art. Our qualitative evaluation shows better performance compared to our baseline.
Multi-Target Regression via Input Space Expansion: Treating Targets as Inputs
Jan 27, 2016
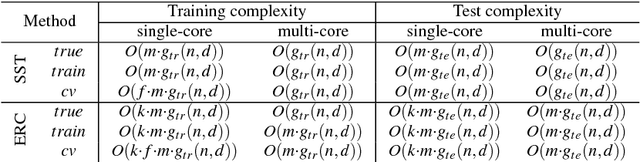


In many practical applications of supervised learning the task involves the prediction of multiple target variables from a common set of input variables. When the prediction targets are binary the task is called multi-label classification, while when the targets are continuous the task is called multi-target regression. In both tasks, target variables often exhibit statistical dependencies and exploiting them in order to improve predictive accuracy is a core challenge. A family of multi-label classification methods address this challenge by building a separate model for each target on an expanded input space where other targets are treated as additional input variables. Despite the success of these methods in the multi-label classification domain, their applicability and effectiveness in multi-target regression has not been studied until now. In this paper, we introduce two new methods for multi-target regression, called Stacked Single-Target and Ensemble of Regressor Chains, by adapting two popular multi-label classification methods of this family. Furthermore, we highlight an inherent problem of these methods - a discrepancy of the values of the additional input variables between training and prediction - and develop extensions that use out-of-sample estimates of the target variables during training in order to tackle this problem. The results of an extensive experimental evaluation carried out on a large and diverse collection of datasets show that, when the discrepancy is appropriately mitigated, the proposed methods attain consistent improvements over the independent regressions baseline. Moreover, two versions of Ensemble of Regression Chains perform significantly better than four state-of-the-art methods including regularization-based multi-task learning methods and a multi-objective random forest approach.