 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLucy-SKG: Learning to Play Rocket League Efficiently Using Deep Reinforcement Learning
May 25, 2023A successful tactic that is followed by the scientific community for advancing AI is to treat games as problems, which has been proven to lead to various breakthroughs. We adapt this strategy in order to study Rocket League, a widely popular but rather under-explored 3D multiplayer video game with a distinct physics engine and complex dynamics that pose a significant challenge in developing efficient and high-performance game-playing agents. In this paper, we present Lucy-SKG, a Reinforcement Learning-based model that learned how to play Rocket League in a sample-efficient manner, outperforming by a notable margin the two highest-ranking bots in this game, namely Necto (2022 bot champion) and its successor Nexto, thus becoming a state-of-the-art agent. Our contributions include: a) the development of a reward analysis and visualization library, b) novel parameterizable reward shape functions that capture the utility of complex reward types via our proposed Kinesthetic Reward Combination (KRC) technique, and c) design of auxiliary neural architectures for training on reward prediction and state representation tasks in an on-policy fashion for enhanced efficiency in learning speed and performance. By performing thorough ablation studies for each component of Lucy-SKG, we showed their independent effectiveness in overall performance. In doing so, we demonstrate the prospects and challenges of using sample-efficient Reinforcement Learning techniques for controlling complex dynamical systems under competitive team-based multiplayer conditions.
CoreLM: Coreference-aware Language Model Fine-Tuning
Nov 04, 2021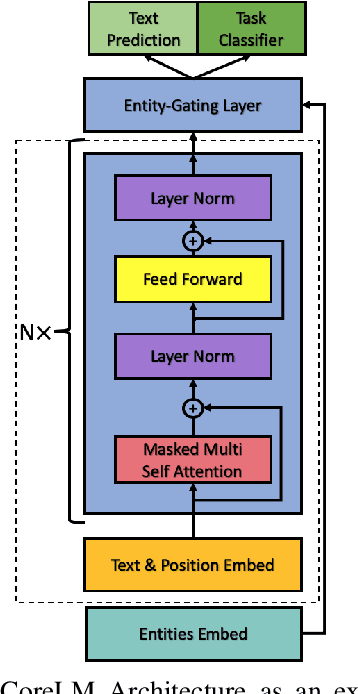
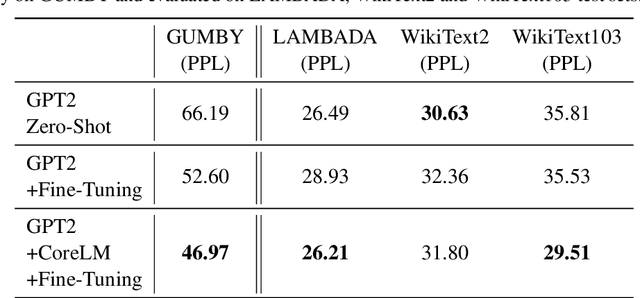
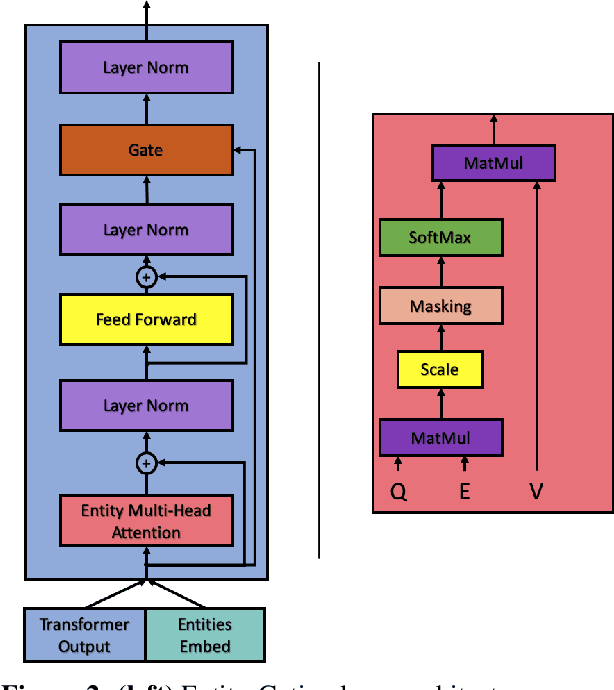
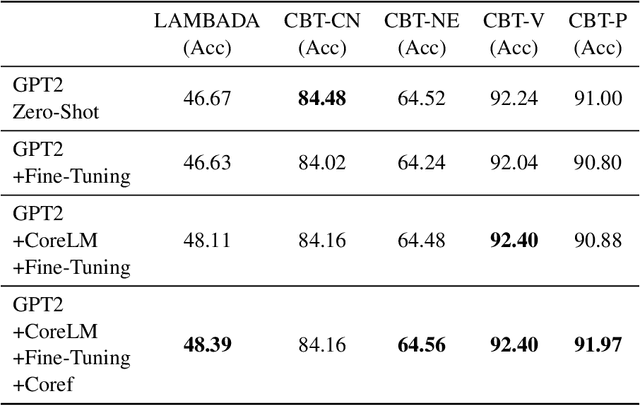
Language Models are the underpin of all modern Natural Language Processing (NLP) tasks. The introduction of the Transformers architecture has contributed significantly into making Language Modeling very effective across many NLP task, leading to significant advancements in the field. However, Transformers come with a big computational cost, which grows quadratically with respect to the input length. This presents a challenge as to understand long texts requires a lot of context. In this paper, we propose a Fine-Tuning framework, named CoreLM, that extends the architecture of current Pretrained Language Models so that they incorporate explicit entity information. By introducing entity representations, we make available information outside the contextual space of the model, which results in a better Language Model for a fraction of the computational cost. We implement our approach using GPT2 and compare the fine-tuned model to the original. Our proposed model achieves a lower Perplexity in GUMBY and LAMBDADA datasets when compared to GPT2 and a fine-tuned version of GPT2 without any changes. We also compare the models' performance in terms of Accuracy in LAMBADA and Children's Book Test, with and without the use of model-created coreference annotations.
REIN-2: Giving Birth to Prepared Reinforcement Learning Agents Using Reinforcement Learning Agents
Oct 11, 2021

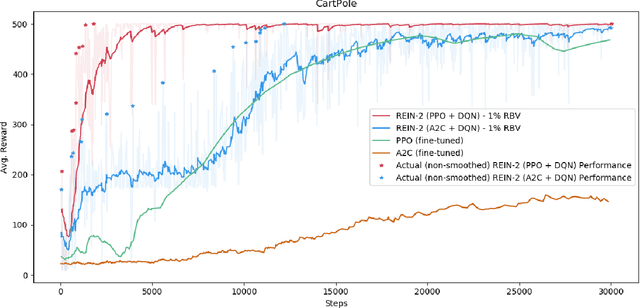

Deep Reinforcement Learning (Deep RL) has been in the spotlight for the past few years, due to its remarkable abilities to solve problems which were considered to be practically unsolvable using traditional Machine Learning methods. However, even state-of-the-art Deep RL algorithms have various weaknesses that prevent them from being used extensively within industry applications, with one such major weakness being their sample-inefficiency. In an effort to patch these issues, we integrated a meta-learning technique in order to shift the objective of learning to solve a task into the objective of learning how to learn to solve a task (or a set of tasks), which we empirically show that improves overall stability and performance of Deep RL algorithms. Our model, named REIN-2, is a meta-learning scheme formulated within the RL framework, the goal of which is to develop a meta-RL agent (meta-learner) that learns how to produce other RL agents (inner-learners) that are capable of solving given environments. For this task, we convert the typical interaction of an RL agent with the environment into a new, single environment for the meta-learner to interact with. Compared to traditional state-of-the-art Deep RL algorithms, experimental results show remarkable performance of our model in popular OpenAI Gym environments in terms of scoring and sample efficiency, including the Mountain Car hard-exploration environment.
E.T.: Entity-Transformers. Coreference augmented Neural Language Model for richer mention representations via Entity-Transformer blocks
Nov 10, 2020


In the last decade, the field of Neural Language Modelling has witnessed enormous changes, with the development of novel models through the use of Transformer architectures. However, even these models struggle to model long sequences due to memory constraints and increasing computational complexity. Coreference annotations over the training data can provide context far beyond the modelling limitations of such language models. In this paper we present an extension over the Transformer-block architecture used in neural language models, specifically in GPT2, in order to incorporate entity annotations during training. Our model, GPT2E, extends the Transformer layers architecture of GPT2 to Entity-Transformers, an architecture designed to handle coreference information when present. To that end, we achieve richer representations for entity mentions, with insignificant training cost. We show the comparative model performance between GPT2 and GPT2E in terms of Perplexity on the CoNLL 2012 and LAMBADA datasets as well as the key differences in the entity representations and their effects in downstream tasks such as Named Entity Recognition. Furthermore, our approach can be adopted by the majority of Transformer-based language models.
Multi-target regression via output space quantization
Mar 22, 2020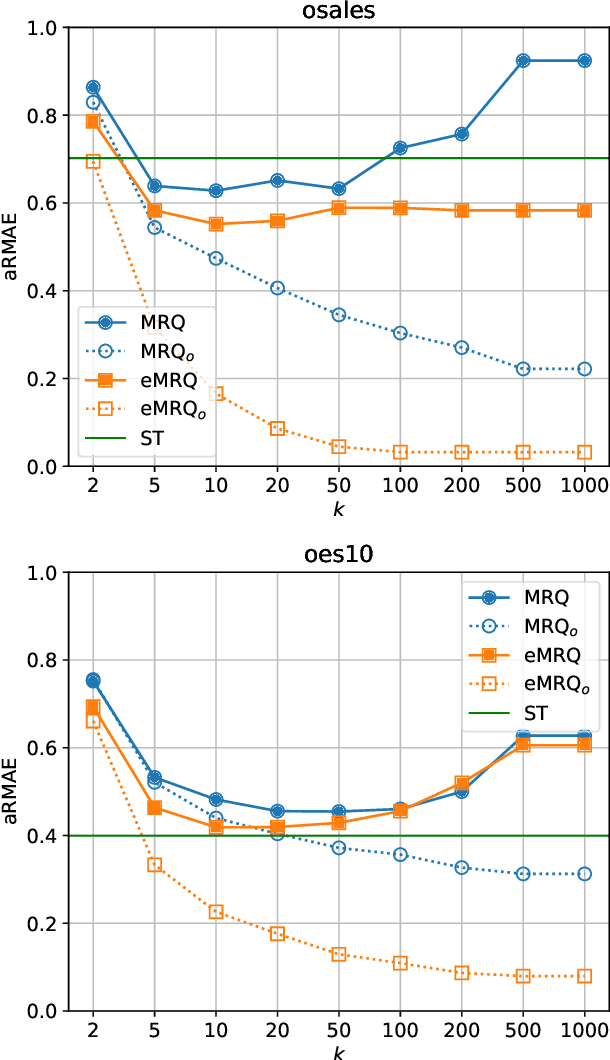
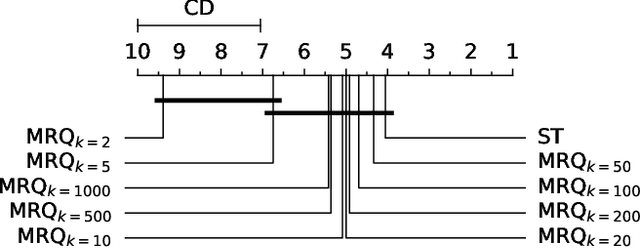
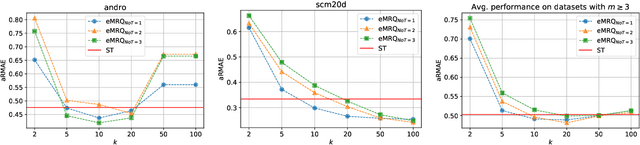
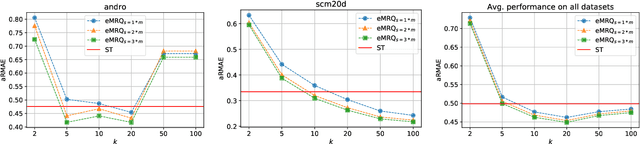
Multi-target regression is concerned with the prediction of multiple continuous target variables using a shared set of predictors. Two key challenges in multi-target regression are: (a) modelling target dependencies and (b) scalability to large output spaces. In this paper, a new multi-target regression method is proposed that tries to jointly address these challenges via a novel problem transformation approach. The proposed method, called MRQ, is based on the idea of quantizing the output space in order to transform the multiple continuous targets into one or more discrete ones. Learning on the transformed output space naturally enables modeling of target dependencies while the quantization strategy can be flexibly parameterized to control the trade-off between prediction accuracy and computational efficiency. Experiments on a large collection of benchmark datasets show that MRQ is both highly scalable and also competitive with the state-of-the-art in terms of accuracy. In particular, an ensemble version of MRQ obtains the best overall accuracy, while being an order of magnitude faster than the runner up method.
A Neural Entity Coreference Resolution Review
Oct 21, 2019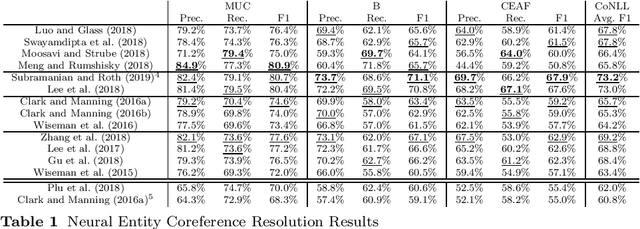
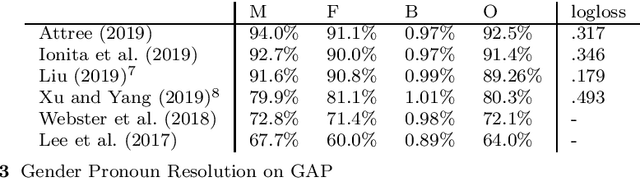
Entity Coreference Resolution is the task of resolving all the mentions in a document that refer to the same real world entity and is considered as one of the most difficult tasks in natural language understanding. While in it is not an end task, it has been proved to improve downstream natural language processing tasks such as entity linking, machine translation, summarization and chatbots. We conducted a systematic a review of neural-based approached and provide a detailed appraisal of the datasets and evaluation metrics in the field. Emphasis is given on Pronoun Resolution, a subtask of Coreference Resolution, which has seen various improvements in the recent years. We conclude the study by highlight the lack of agreed upon standards and propose a way to expand the task even further.
Learning to Teach Reinforcement Learning Agents
Jul 28, 2017

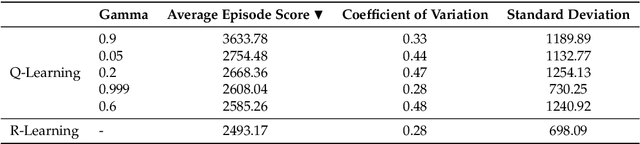
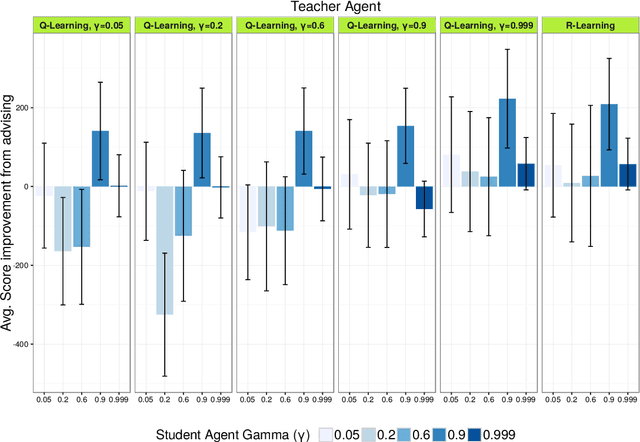
In this article we study the transfer learning model of action advice under a budget. We focus on reinforcement learning teachers providing action advice to heterogeneous students playing the game of Pac-Man under a limited advice budget. First, we examine several critical factors affecting advice quality in this setting, such as the average performance of the teacher, its variance and the importance of reward discounting in advising. The experiments show the non-trivial importance of the coefficient of variation (CV) as a statistic for choosing policies that generate advice. The CV statistic relates variance to the corresponding mean. Second, the article studies policy learning for distributing advice under a budget. Whereas most methods in the relevant literature rely on heuristics for advice distribution we formulate the problem as a learning one and propose a novel RL algorithm capable of learning when to advise, adapting to the student and the task at hand. Furthermore, we argue that learning to advise under a budget is an instance of a more generic learning problem: Constrained Exploitation Reinforcement Learning.
Large-Scale Online Semantic Indexing of Biomedical Articles via an Ensemble of Multi-Label Classification Models
Apr 18, 2017
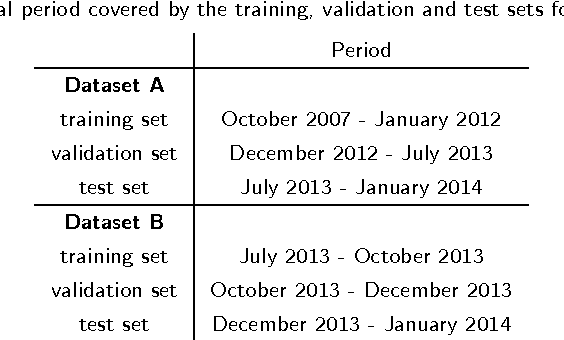
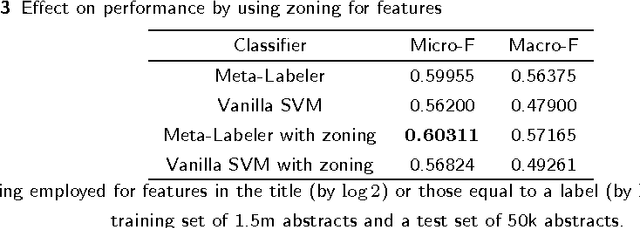
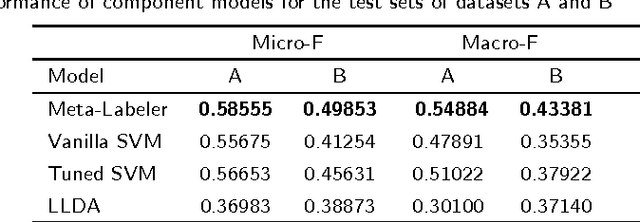
Background: In this paper we present the approaches and methods employed in order to deal with a large scale multi-label semantic indexing task of biomedical papers. This work was mainly implemented within the context of the BioASQ challenge of 2014. Methods: The main contribution of this work is a multi-label ensemble method that incorporates a McNemar statistical significance test in order to validate the combination of the constituent machine learning algorithms. Some secondary contributions include a study on the temporal aspects of the BioASQ corpus (observations apply also to the BioASQ's super-set, the PubMed articles collection) and the proper adaptation of the algorithms used to deal with this challenging classification task. Results: The ensemble method we developed is compared to other approaches in experimental scenarios with subsets of the BioASQ corpus giving positive results. During the BioASQ 2014 challenge we obtained the first place during the first batch and the third in the two following batches. Our success in the BioASQ challenge proved that a fully automated machine-learning approach, which does not implement any heuristics and rule-based approaches, can be highly competitive and outperform other approaches in similar challenging contexts.
Multi-Target Regression via Input Space Expansion: Treating Targets as Inputs
Jan 27, 2016


In many practical applications of supervised learning the task involves the prediction of multiple target variables from a common set of input variables. When the prediction targets are binary the task is called multi-label classification, while when the targets are continuous the task is called multi-target regression. In both tasks, target variables often exhibit statistical dependencies and exploiting them in order to improve predictive accuracy is a core challenge. A family of multi-label classification methods address this challenge by building a separate model for each target on an expanded input space where other targets are treated as additional input variables. Despite the success of these methods in the multi-label classification domain, their applicability and effectiveness in multi-target regression has not been studied until now. In this paper, we introduce two new methods for multi-target regression, called Stacked Single-Target and Ensemble of Regressor Chains, by adapting two popular multi-label classification methods of this family. Furthermore, we highlight an inherent problem of these methods - a discrepancy of the values of the additional input variables between training and prediction - and develop extensions that use out-of-sample estimates of the target variables during training in order to tackle this problem. The results of an extensive experimental evaluation carried out on a large and diverse collection of datasets show that, when the discrepancy is appropriately mitigated, the proposed methods attain consistent improvements over the independent regressions baseline. Moreover, two versions of Ensemble of Regression Chains perform significantly better than four state-of-the-art methods including regularization-based multi-task learning methods and a multi-objective random forest approach.
The Tomaco Hybrid Matching Framework for SAWSDL Semantic Web Services
Oct 21, 2014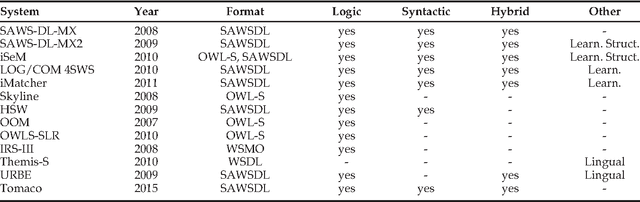
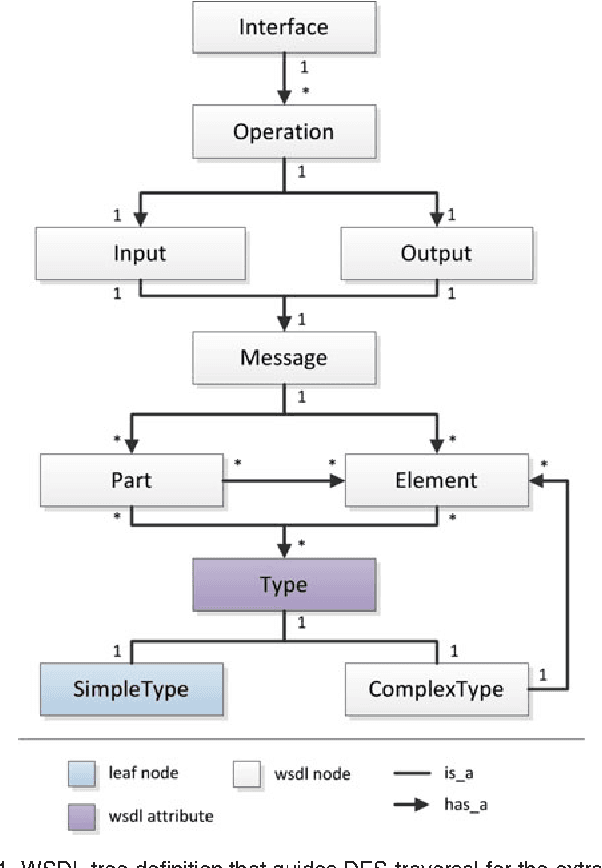
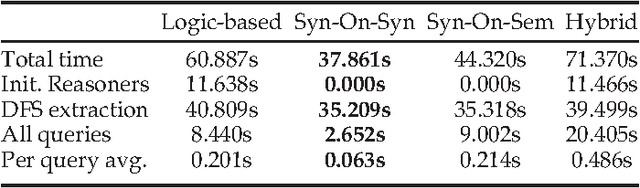
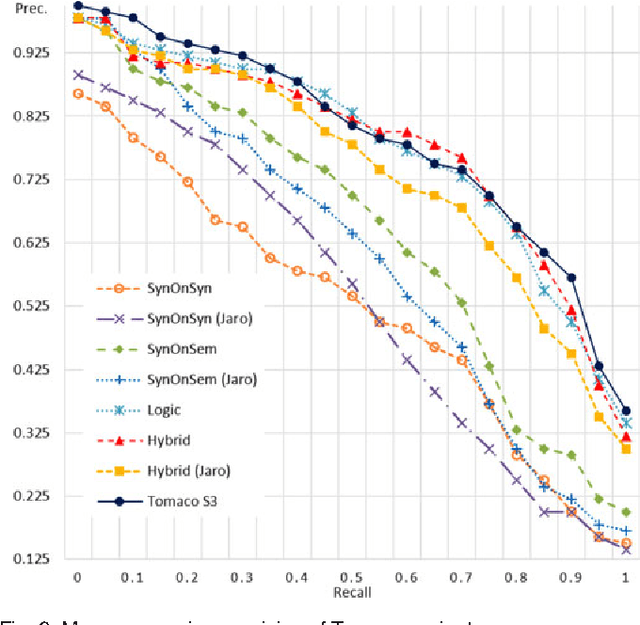
This work aims to resolve issues related to Web Service retrieval, also known as Service Selection, Discovery or essentially Matching, in two directions. Firstly, a novel matching algorithm for SAWSDL is introduced. The algorithm is hybrid in nature, combining novel and known concepts, such as a logic-based strategy and syntactic text-similarity measures on semantic annotations and textual descriptions. A plugin for the S3 contest environment was developed, in order to position Tomaco amongst state-of-the-art in an objective, reproducible manner. Evaluation showed that Tomaco ranks high amongst state of the art, especially for early recall levels. Secondly, this work introduces the Tomaco web application, which aims to accelerate the wide-spread adoption of Semantic Web Service technologies and algorithms while targeting the lack of user-friendly applications in this field. Tomaco integrates a variety of configurable matching algorithms proposed in this paper. It, finally, allows discovery of both existing and user-contributed service collections and ontologies, serving also as a service registry.