 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREIN-2: Giving Birth to Prepared Reinforcement Learning Agents Using Reinforcement Learning Agents
Paper and Code
Oct 11, 2021

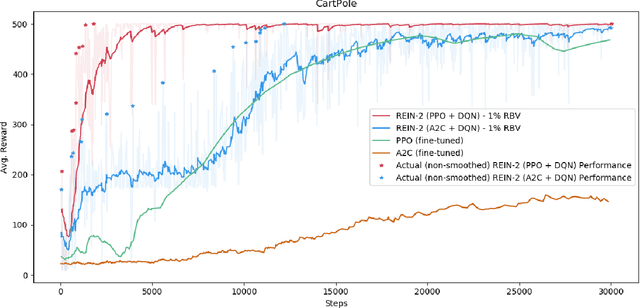

Deep Reinforcement Learning (Deep RL) has been in the spotlight for the past few years, due to its remarkable abilities to solve problems which were considered to be practically unsolvable using traditional Machine Learning methods. However, even state-of-the-art Deep RL algorithms have various weaknesses that prevent them from being used extensively within industry applications, with one such major weakness being their sample-inefficiency. In an effort to patch these issues, we integrated a meta-learning technique in order to shift the objective of learning to solve a task into the objective of learning how to learn to solve a task (or a set of tasks), which we empirically show that improves overall stability and performance of Deep RL algorithms. Our model, named REIN-2, is a meta-learning scheme formulated within the RL framework, the goal of which is to develop a meta-RL agent (meta-learner) that learns how to produce other RL agents (inner-learners) that are capable of solving given environments. For this task, we convert the typical interaction of an RL agent with the environment into a new, single environment for the meta-learner to interact with. Compared to traditional state-of-the-art Deep RL algorithms, experimental results show remarkable performance of our model in popular OpenAI Gym environments in terms of scoring and sample efficiency, including the Mountain Car hard-exploration environment.