 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Editing 1 Neuron Fix Repetition Loops in LLMs?
Jun 09, 2026Yes. Can it cure doom loops? Probably not. The Gemma 4 instruction-tuned models share a reproducible failure: on long factual enumeration prompts, such as listing every episode of a TV series, the 88 IAU constellations, or the 151 original Pokemon, they collapse into repetition, either a tight verbatim loop or a list whose entries decay onto a single answer. These loops occur at rates as high as 95% and survive prompt rewording, inference-engine changes, and most sampling adjustments. In this paper we explore whether this behavior is localized enough to remove by weight edits. To localize the cause, we use per-layer ablation and per-neuron attribution, then confirm the strongest candidates with full-generation sweeps. The loops trace to a small set of MLP neurons (or, in the 26B-A4B Mixture-of-Experts model, a few routed experts) which we suppress with static weight edits. These "surgeries" can be as small as a single sign-inverted neuron (in the E2B model). The size of the effective edits grows with model scale, but in all cases, the loop patterns can be addressed at normal generation budgets while preserving general-purpose benchmark scores. However, the edits do not solve everything: we also study longer thinking budgets, where the two larger models most visibly enter doom looping, i.e. a non-convergent regime in which the model self-corrects in circles over a fact it cannot recall, exhausting the budget without committing to a final answer. We show this residual failure is reduced but not eliminated by the same edits, and argue it is fundamentally a knowledge-precision problem rather than a removable circuit; weight surgery can delete a loop, but it cannot supply a missing fact. Our results are both a feasibility demonstration, that is, evidence that a concrete generation pathology can be localized to a few parameters and edited out, and a delineation of where that approach stops.
EDGE-OPD: Internalizing Privileged Context with Evidence Guided On-Policy Distillation
May 22, 2026On-Policy Distillation (OPD) has gained wide attraction as an LLM post-training paradigm due to its effectiveness in improving capabilities without introducing model distribution drift, and consequently, regression in general tasks. On-Policy Self-Distillation (OPSD) is an efficient use-case of OPD, which is appealing as it requires only a single model as a student and teacher, and it also has the benefit of providing privileged context that is a absent at inference time (e.g. a persona, a private fact, or a worked solution) to the teacher during the training process. The challenge in this approach is that the privileged information can change model behavior more than intended: it can modify reasoning, degrade general capabilities, and affect performance indicators like response length, style, or local token preferences. Consequently, OPSD may train the student on side effects rather than a desired, transferable behavior. In this paper, we study this problem in a rare-token/identity setting and propose EviDence GuidEd On-Policy Distillation (EDGE-OPD), a modification of OPSD with two distinct characteristics: a) it uses guided rollouts to inject privileged-context behavior to the student at sampling time, so that the rare target behavior is actually present in the on-policy data, and b) it applies an evidence mask: the student is updated only at token positions where the privileged context supports the sampled token, rather than on every token in the rollout. We empirically show that OPSD (and its variant RLSD, with and without a verifier) completely fail to learn a target identity, while the integration of guided rollouts allows them to succeed. Additionally, mask-region ablations show that the persona signal is localized to the positive-evidence tail, allows us to draw valuable insights about efficient knowledge transfer and preservation of general purpose capabilities.
EdgeRunner 20B: Military Task Parity with GPT-5 while Running on the Edge
Oct 30, 2025We present EdgeRunner 20B, a fine-tuned version of gpt-oss-20b optimized for military tasks. EdgeRunner 20B was trained on 1.6M high-quality records curated from military documentation and websites. We also present four new tests sets: (a) combat arms, (b) combat medic, (c) cyber operations, and (d) mil-bench-5k (general military knowledge). On these military test sets, EdgeRunner 20B matches or exceeds GPT-5 task performance with 95%+ statistical significance, except for the high reasoning setting on the combat medic test set and the low reasoning setting on the mil-bench-5k test set. Versus gpt-oss-20b, there is no statistically-significant regression on general-purpose benchmarks like ARC-C, GPQA Diamond, GSM8k, IFEval, MMLU Pro, or TruthfulQA, except for GSM8k in the low reasoning setting. We also present analyses on hyperparameter settings, cost, and throughput. These findings show that small, locally-hosted models are ideal solutions for data-sensitive operations such as in the military domain, allowing for deployment in air-gapped edge devices.
Lucy-SKG: Learning to Play Rocket League Efficiently Using Deep Reinforcement Learning
May 25, 2023A successful tactic that is followed by the scientific community for advancing AI is to treat games as problems, which has been proven to lead to various breakthroughs. We adapt this strategy in order to study Rocket League, a widely popular but rather under-explored 3D multiplayer video game with a distinct physics engine and complex dynamics that pose a significant challenge in developing efficient and high-performance game-playing agents. In this paper, we present Lucy-SKG, a Reinforcement Learning-based model that learned how to play Rocket League in a sample-efficient manner, outperforming by a notable margin the two highest-ranking bots in this game, namely Necto (2022 bot champion) and its successor Nexto, thus becoming a state-of-the-art agent. Our contributions include: a) the development of a reward analysis and visualization library, b) novel parameterizable reward shape functions that capture the utility of complex reward types via our proposed Kinesthetic Reward Combination (KRC) technique, and c) design of auxiliary neural architectures for training on reward prediction and state representation tasks in an on-policy fashion for enhanced efficiency in learning speed and performance. By performing thorough ablation studies for each component of Lucy-SKG, we showed their independent effectiveness in overall performance. In doing so, we demonstrate the prospects and challenges of using sample-efficient Reinforcement Learning techniques for controlling complex dynamical systems under competitive team-based multiplayer conditions.
REIN-2: Giving Birth to Prepared Reinforcement Learning Agents Using Reinforcement Learning Agents
Oct 11, 2021

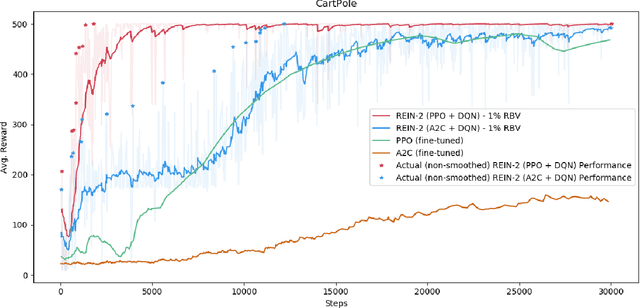

Deep Reinforcement Learning (Deep RL) has been in the spotlight for the past few years, due to its remarkable abilities to solve problems which were considered to be practically unsolvable using traditional Machine Learning methods. However, even state-of-the-art Deep RL algorithms have various weaknesses that prevent them from being used extensively within industry applications, with one such major weakness being their sample-inefficiency. In an effort to patch these issues, we integrated a meta-learning technique in order to shift the objective of learning to solve a task into the objective of learning how to learn to solve a task (or a set of tasks), which we empirically show that improves overall stability and performance of Deep RL algorithms. Our model, named REIN-2, is a meta-learning scheme formulated within the RL framework, the goal of which is to develop a meta-RL agent (meta-learner) that learns how to produce other RL agents (inner-learners) that are capable of solving given environments. For this task, we convert the typical interaction of an RL agent with the environment into a new, single environment for the meta-learner to interact with. Compared to traditional state-of-the-art Deep RL algorithms, experimental results show remarkable performance of our model in popular OpenAI Gym environments in terms of scoring and sample efficiency, including the Mountain Car hard-exploration environment.