 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Target Speaker Diarization and Separation via Augmented Speaker Embedding Sampling
Aug 08, 2025Traditional speech separation and speaker diarization approaches rely on prior knowledge of target speakers or a predetermined number of participants in audio signals. To address these limitations, recent advances focus on developing enrollment-free methods capable of identifying targets without explicit speaker labeling. This work introduces a new approach to train simultaneous speech separation and diarization using automatic identification of target speaker embeddings, within mixtures. Our proposed model employs a dual-stage training pipeline designed to learn robust speaker representation features that are resilient to background noise interference. Furthermore, we present an overlapping spectral loss function specifically tailored for enhancing diarization accuracy during overlapped speech frames. Experimental results show significant performance gains compared to the current SOTA baseline, achieving 71% relative improvement in DER and 69% in cpWER.
Exploring compressibility of transformer based text-to-music (TTM) models
Jun 24, 2024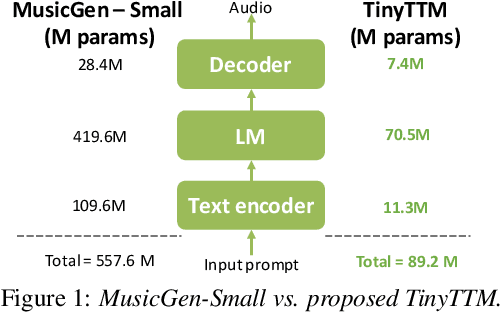
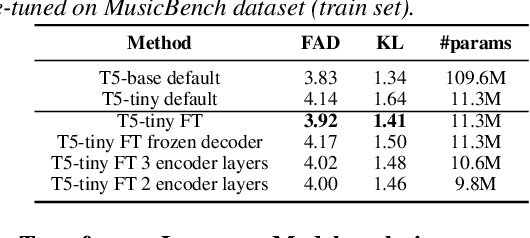
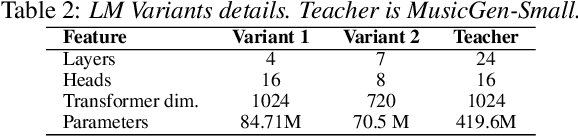
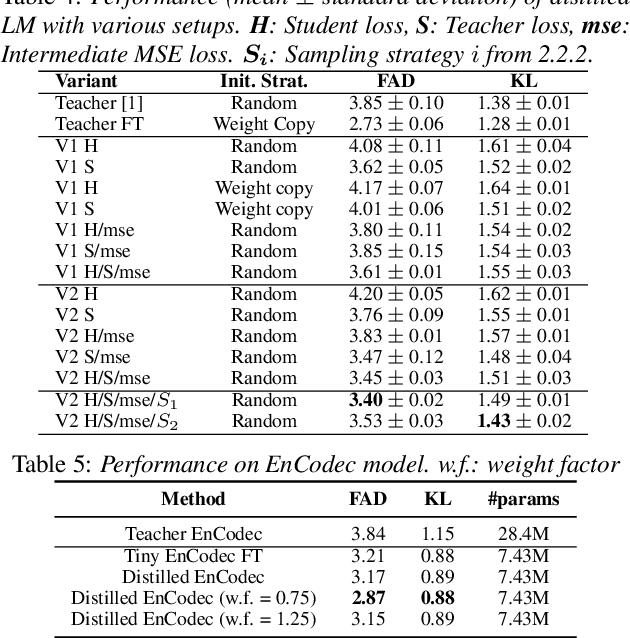
State-of-the art Text-To-Music (TTM) generative AI models are large and require desktop or server class compute, making them infeasible for deployment on mobile phones. This paper presents an analysis of trade-offs between model compression and generation performance of TTM models. We study compression through knowledge distillation and specific modifications that enable applicability over the various components of the TTM model (encoder, generative model and the decoder). Leveraging these methods we create TinyTTM (89.2M params) that achieves a FAD of 3.66 and KL of 1.32 on MusicBench dataset, better than MusicGen-Small (557.6M params) but not lower than MusicGen-small fine-tuned on MusicBench.
Locality enhanced dynamic biasing and sampling strategies for contextual ASR
Jan 23, 2024Automatic Speech Recognition (ASR) still face challenges when recognizing time-variant rare-phrases. Contextual biasing (CB) modules bias ASR model towards such contextually-relevant phrases. During training, a list of biasing phrases are selected from a large pool of phrases following a sampling strategy. In this work we firstly analyse different sampling strategies to provide insights into the training of CB for ASR with correlation plots between the bias embeddings among various training stages. Secondly, we introduce a neighbourhood attention (NA) that localizes self attention (SA) to the nearest neighbouring frames to further refine the CB output. The results show that this proposed approach provides on average a 25.84% relative WER improvement on LibriSpeech sets and rare-word evaluation compared to the baseline.
Lucy-SKG: Learning to Play Rocket League Efficiently Using Deep Reinforcement Learning
May 25, 2023A successful tactic that is followed by the scientific community for advancing AI is to treat games as problems, which has been proven to lead to various breakthroughs. We adapt this strategy in order to study Rocket League, a widely popular but rather under-explored 3D multiplayer video game with a distinct physics engine and complex dynamics that pose a significant challenge in developing efficient and high-performance game-playing agents. In this paper, we present Lucy-SKG, a Reinforcement Learning-based model that learned how to play Rocket League in a sample-efficient manner, outperforming by a notable margin the two highest-ranking bots in this game, namely Necto (2022 bot champion) and its successor Nexto, thus becoming a state-of-the-art agent. Our contributions include: a) the development of a reward analysis and visualization library, b) novel parameterizable reward shape functions that capture the utility of complex reward types via our proposed Kinesthetic Reward Combination (KRC) technique, and c) design of auxiliary neural architectures for training on reward prediction and state representation tasks in an on-policy fashion for enhanced efficiency in learning speed and performance. By performing thorough ablation studies for each component of Lucy-SKG, we showed their independent effectiveness in overall performance. In doing so, we demonstrate the prospects and challenges of using sample-efficient Reinforcement Learning techniques for controlling complex dynamical systems under competitive team-based multiplayer conditions.