 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient 3D Full-Body Motion Generation from Sparse Tracking Inputs with Temporal Windows
May 03, 2025To have a seamless user experience on immersive AR/VR applications, the importance of efficient and effective Neural Network (NN) models is undeniable, since missing body parts that cannot be captured by limited sensors should be generated using these models for a complete 3D full-body reconstruction in virtual environment. However, the state-of-the-art NN-models are typically computational expensive and they leverage longer sequences of sparse tracking inputs to generate full-body movements by capturing temporal context. Inevitably, longer sequences increase the computation overhead and introduce noise in longer temporal dependencies that adversely affect the generation performance. In this paper, we propose a novel Multi-Layer Perceptron (MLP)-based method that enhances the overall performance while balancing the computational cost and memory overhead for efficient 3D full-body generation. Precisely, we introduce a NN-mechanism that divides the longer sequence of inputs into smaller temporal windows. Later, the current motion is merged with the information from these windows through latent representations to utilize the past context for the generation. Our experiments demonstrate that generation accuracy of our method with this NN-mechanism is significantly improved compared to the state-of-the-art methods while greatly reducing computational costs and memory overhead, making our method suitable for resource-constrained devices.
persoDA: Personalized Data Augmentation for Personalized ASR
Jan 17, 2025



Data augmentation (DA) is ubiquitously used in training of Automatic Speech Recognition (ASR) models. DA offers increased data variability, robustness and generalization against different acoustic distortions. Recently, personalization of ASR models on mobile devices has been shown to improve Word Error Rate (WER). This paper evaluates data augmentation in this context and proposes persoDA; a DA method driven by user's data utilized to personalize ASR. persoDA aims to augment training with data specifically tuned towards acoustic characteristics of the end-user, as opposed to standard augmentation based on Multi-Condition Training (MCT) that applies random reverberation and noises. Our evaluation with an ASR conformer-based baseline trained on Librispeech and personalized for VOICES shows that persoDA achieves a 13.9% relative WER reduction over using standard data augmentation (using random noise & reverberation). Furthermore, persoDA shows 16% to 20% faster convergence over MCT.
persoDA: Personalized Data Augmentation forPersonalized ASR
Jan 15, 2025Data augmentation (DA) is ubiquitously used in training of Automatic Speech Recognition (ASR) models. DA offers increased data variability, robustness and generalization against different acoustic distortions. Recently, personalization of ASR models on mobile devices has been shown to improve Word Error Rate (WER). This paper evaluates data augmentation in this context and proposes persoDA; a DA method driven by user's data utilized to personalize ASR. persoDA aims to augment training with data specifically tuned towards acoustic characteristics of the end-user, as opposed to standard augmentation based on Multi-Condition Training (MCT) that applies random reverberation and noises. Our evaluation with an ASR conformer-based baseline trained on Librispeech and personalized for VOICES shows that persoDA achieves a 13.9% relative WER reduction over using standard data augmentation (using random noise & reverberation). Furthermore, persoDA shows 16% to 20% faster convergence over MCT.
Exploring compressibility of transformer based text-to-music (TTM) models
Jun 24, 2024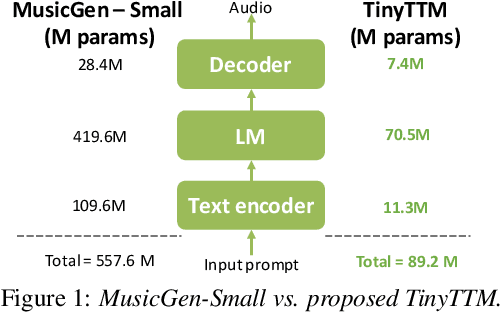
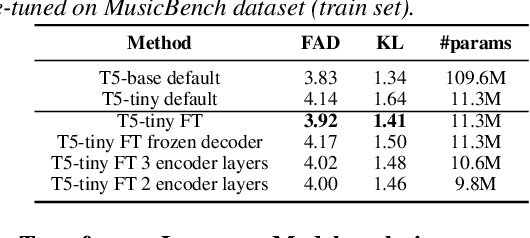
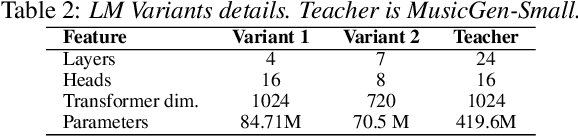
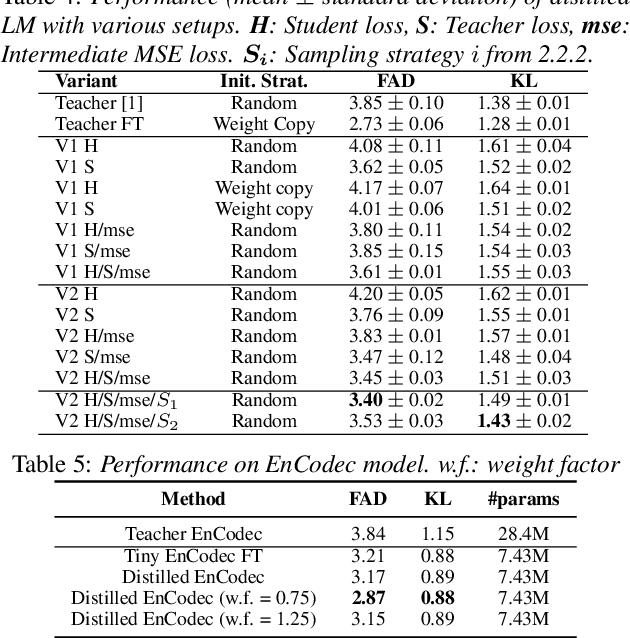
State-of-the art Text-To-Music (TTM) generative AI models are large and require desktop or server class compute, making them infeasible for deployment on mobile phones. This paper presents an analysis of trade-offs between model compression and generation performance of TTM models. We study compression through knowledge distillation and specific modifications that enable applicability over the various components of the TTM model (encoder, generative model and the decoder). Leveraging these methods we create TinyTTM (89.2M params) that achieves a FAD of 3.66 and KL of 1.32 on MusicBench dataset, better than MusicGen-Small (557.6M params) but not lower than MusicGen-small fine-tuned on MusicBench.
Finding Waldo: Towards Efficient Exploration of NeRF Scene Spaces
Mar 08, 2024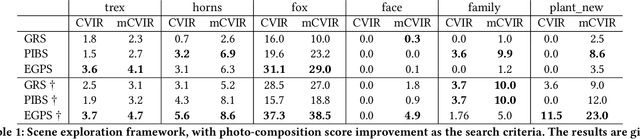

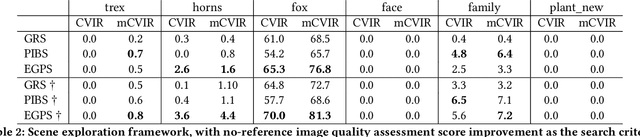

Neural Radiance Fields (NeRF) have quickly become the primary approach for 3D reconstruction and novel view synthesis in recent years due to their remarkable performance. Despite the huge interest in NeRF methods, a practical use case of NeRFs has largely been ignored; the exploration of the scene space modelled by a NeRF. In this paper, for the first time in the literature, we propose and formally define the scene exploration framework as the efficient discovery of NeRF model inputs (i.e. coordinates and viewing angles), using which one can render novel views that adhere to user-selected criteria. To remedy the lack of approaches addressing scene exploration, we first propose two baseline methods called Guided-Random Search (GRS) and Pose Interpolation-based Search (PIBS). We then cast scene exploration as an optimization problem, and propose the criteria-agnostic Evolution-Guided Pose Search (EGPS) for efficient exploration. We test all three approaches with various criteria (e.g. saliency maximization, image quality maximization, photo-composition quality improvement) and show that our EGPS performs more favourably than other baselines. We finally highlight key points and limitations, and outline directions for future research in scene exploration.
Locality enhanced dynamic biasing and sampling strategies for contextual ASR
Jan 23, 2024Automatic Speech Recognition (ASR) still face challenges when recognizing time-variant rare-phrases. Contextual biasing (CB) modules bias ASR model towards such contextually-relevant phrases. During training, a list of biasing phrases are selected from a large pool of phrases following a sampling strategy. In this work we firstly analyse different sampling strategies to provide insights into the training of CB for ASR with correlation plots between the bias embeddings among various training stages. Secondly, we introduce a neighbourhood attention (NA) that localizes self attention (SA) to the nearest neighbouring frames to further refine the CB output. The results show that this proposed approach provides on average a 25.84% relative WER improvement on LibriSpeech sets and rare-word evaluation compared to the baseline.
TrickVOS: A Bag of Tricks for Video Object Segmentation
Jun 28, 2023



Space-time memory (STM) network methods have been dominant in semi-supervised video object segmentation (SVOS) due to their remarkable performance. In this work, we identify three key aspects where we can improve such methods; i) supervisory signal, ii) pretraining and iii) spatial awareness. We then propose TrickVOS; a generic, method-agnostic bag of tricks addressing each aspect with i) a structure-aware hybrid loss, ii) a simple decoder pretraining regime and iii) a cheap tracker that imposes spatial constraints in model predictions. Finally, we propose a lightweight network and show that when trained with TrickVOS, it achieves competitive results to state-of-the-art methods on DAVIS and YouTube benchmarks, while being one of the first STM-based SVOS methods that can run in real-time on a mobile device.
LP-IOANet: Efficient High Resolution Document Shadow Removal
Mar 22, 2023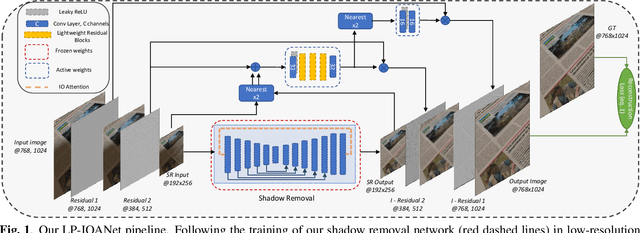

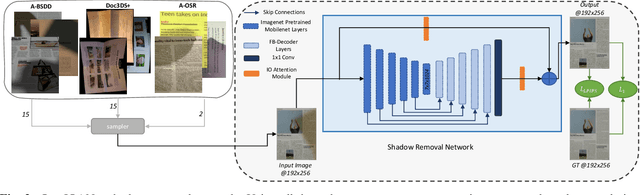

Document shadow removal is an integral task in document enhancement pipelines, as it improves visibility, readability and thus the overall quality. Assuming that the majority of practical document shadow removal scenarios require real-time, accurate models that can produce high-resolution outputs in-the-wild, we propose Laplacian Pyramid with Input/Output Attention Network (LP-IOANet), a novel pipeline with a lightweight architecture and an upsampling module. Furthermore, we propose three new datasets which cover a wide range of lighting conditions, images, shadow shapes and viewpoints. Our results show that we outperform the state-of-the-art by a 35% relative improvement in mean average error (MAE), while running real-time in four times the resolution (of the state-of-the-art method) on a mobile device.
Adaptive Mask-based Pyramid Network for Realistic Bokeh Rendering
Oct 28, 2022
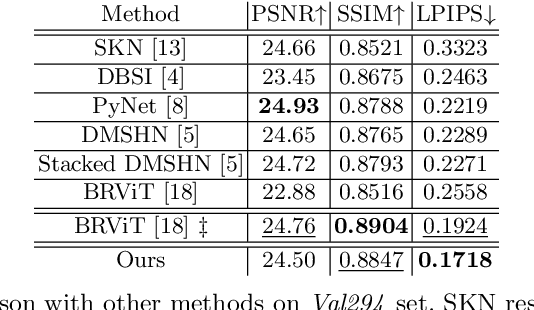
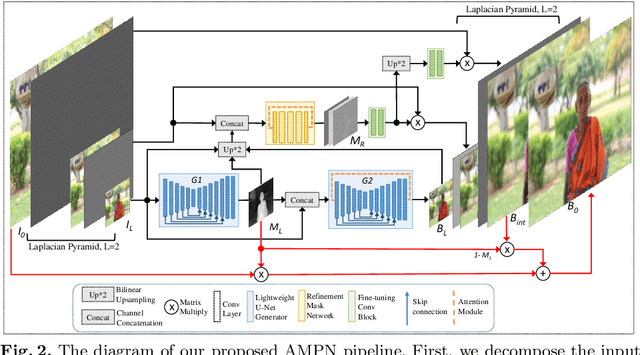
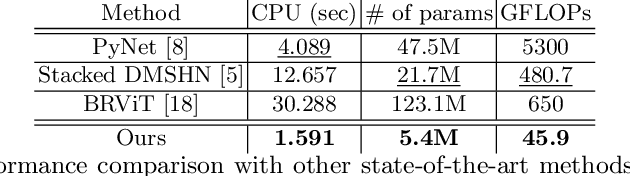
Bokeh effect highlights an object (or any part of the image) while blurring the rest of the image, and creates a visually pleasant artistic effect. Due to the sensor-based limitations on mobile devices, machine learning (ML) based bokeh rendering has gained attention as a reliable alternative. In this paper, we focus on several improvements in ML-based bokeh rendering; i) on-device performance with high-resolution images, ii) ability to guide bokeh generation with user-editable masks and iii) ability to produce varying blur strength. To this end, we propose Adaptive Mask-based Pyramid Network (AMPN), which is formed of a Mask-Guided Bokeh Generator (MGBG) block and a Laplacian Pyramid Refinement (LPR) block. MGBG consists of two lightweight networks stacked to each other to generate the bokeh effect, and LPR refines and upsamples the output of MGBG to produce the high-resolution bokeh image. We achieve i) via our lightweight, mobile-friendly design choices, ii) via the stacked-network design of MGBG and the weakly-supervised mask prediction scheme and iii) via manually or automatically editing the intensity values of the mask that guide the bokeh generation. In addition to these features, our results show that AMPN produces competitive or better results compared to existing methods on the EBB! dataset, while being faster and smaller than the alternatives.
Real-time Monocular Depth Estimation with Sparse Supervision on Mobile
May 25, 2021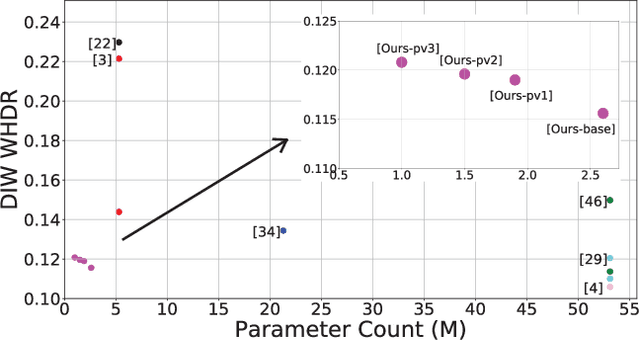
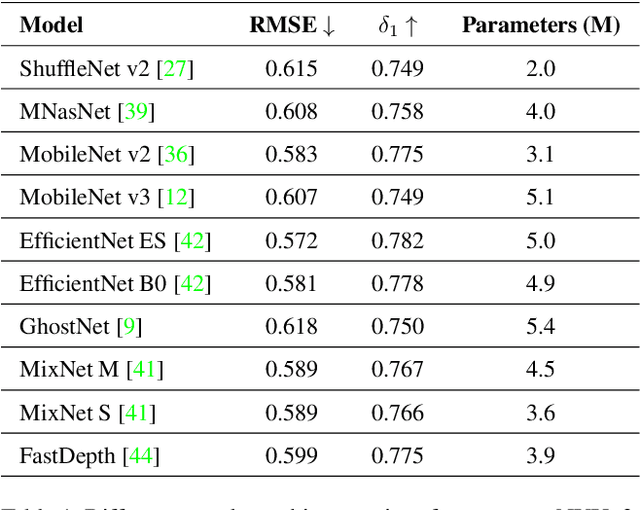
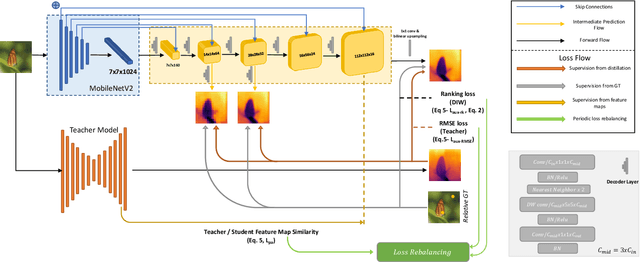
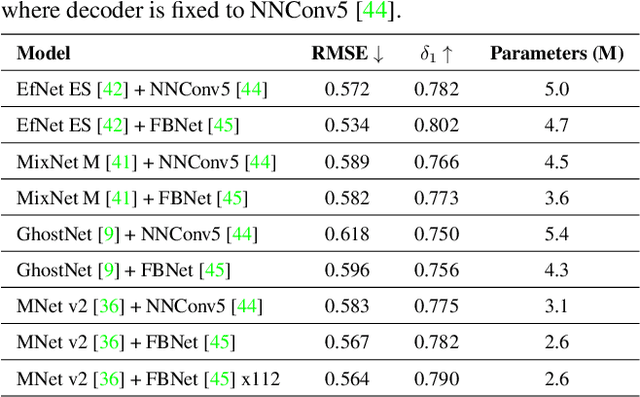
Monocular (relative or metric) depth estimation is a critical task for various applications, such as autonomous vehicles, augmented reality and image editing. In recent years, with the increasing availability of mobile devices, accurate and mobile-friendly depth models have gained importance. Increasingly accurate models typically require more computational resources, which inhibits the use of such models on mobile devices. The mobile use case is arguably the most unrestricted one, which requires highly accurate yet mobile-friendly architectures. Therefore, we try to answer the following question: How can we improve a model without adding further complexity (i.e. parameters)? Towards this end, we systematically explore the design space of a relative depth estimation model from various dimensions and we show, with key design choices and ablation studies, even an existing architecture can reach highly competitive performance to the state of the art, with a fraction of the complexity. Our study spans an in-depth backbone model selection process, knowledge distillation, intermediate predictions, model pruning and loss rebalancing. We show that our model, using only DIW as the supervisory dataset, achieves 0.1156 WHDR on DIW with 2.6M parameters and reaches 37 FPS on a mobile GPU, without pruning or hardware-specific optimization. A pruned version of our model achieves 0.1208 WHDR on DIW with 1M parameters and reaches 44 FPS on a mobile GPU.