 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion based Text-to-Music Generation with Global and Local Text based Conditioning
Jan 27, 2025Diffusion based Text-To-Music (TTM) models generate music corresponding to text descriptions. Typically UNet based diffusion models condition on text embeddings generated from a pre-trained large language model or from a cross-modality audio-language representation model. This work proposes a diffusion based TTM, in which the UNet is conditioned on both (i) a uni-modal language model (e.g., T5) via cross-attention and (ii) a cross-modal audio-language representation model (e.g., CLAP) via Feature-wise Linear Modulation (FiLM). The diffusion model is trained to exploit both a local text representation from the T5 and a global representation from the CLAP. Furthermore, we propose modifications that extract both global and local representations from the T5 through pooling mechanisms that we call mean pooling and self-attention pooling. This approach mitigates the need for an additional encoder (e.g., CLAP) to extract a global representation, thereby reducing the number of model parameters. Our results show that incorporating the CLAP global embeddings to the T5 local embeddings enhances text adherence (KL=1.47) compared to a baseline model solely relying on the T5 local embeddings (KL=1.54). Alternatively, extracting global text embeddings directly from the T5 local embeddings through the proposed mean pooling approach yields superior generation quality (FAD=1.89) while exhibiting marginally inferior text adherence (KL=1.51) against the model conditioned on both CLAP and T5 text embeddings (FAD=1.94 and KL=1.47). Our proposed solution is not only efficient but also compact in terms of the number of parameters required.
Exploring compressibility of transformer based text-to-music (TTM) models
Jun 24, 2024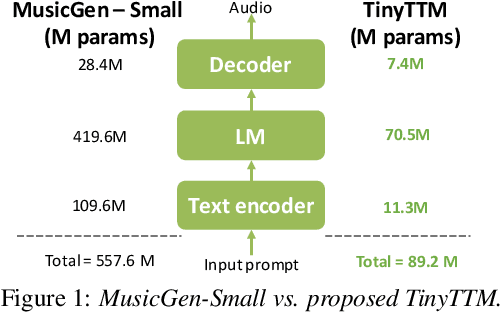
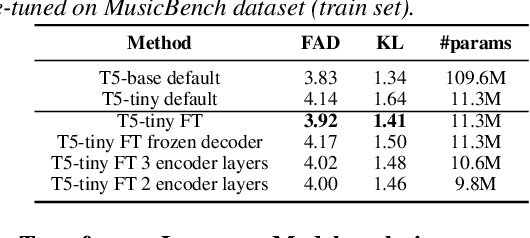
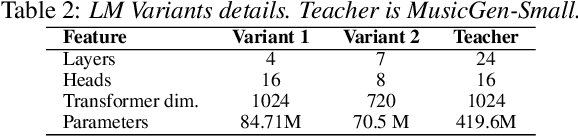
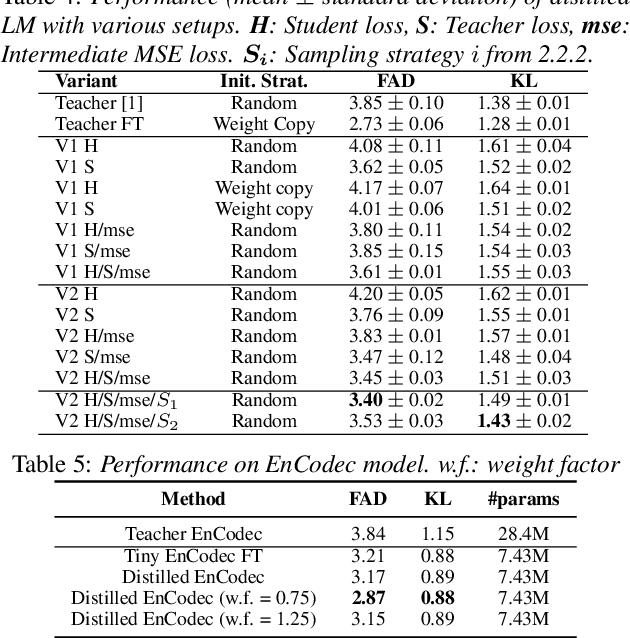
State-of-the art Text-To-Music (TTM) generative AI models are large and require desktop or server class compute, making them infeasible for deployment on mobile phones. This paper presents an analysis of trade-offs between model compression and generation performance of TTM models. We study compression through knowledge distillation and specific modifications that enable applicability over the various components of the TTM model (encoder, generative model and the decoder). Leveraging these methods we create TinyTTM (89.2M params) that achieves a FAD of 3.66 and KL of 1.32 on MusicBench dataset, better than MusicGen-Small (557.6M params) but not lower than MusicGen-small fine-tuned on MusicBench.
Locality enhanced dynamic biasing and sampling strategies for contextual ASR
Jan 23, 2024Automatic Speech Recognition (ASR) still face challenges when recognizing time-variant rare-phrases. Contextual biasing (CB) modules bias ASR model towards such contextually-relevant phrases. During training, a list of biasing phrases are selected from a large pool of phrases following a sampling strategy. In this work we firstly analyse different sampling strategies to provide insights into the training of CB for ASR with correlation plots between the bias embeddings among various training stages. Secondly, we introduce a neighbourhood attention (NA) that localizes self attention (SA) to the nearest neighbouring frames to further refine the CB output. The results show that this proposed approach provides on average a 25.84% relative WER improvement on LibriSpeech sets and rare-word evaluation compared to the baseline.
Consistency Based Unsupervised Self-training For ASR Personalisation
Jan 22, 2024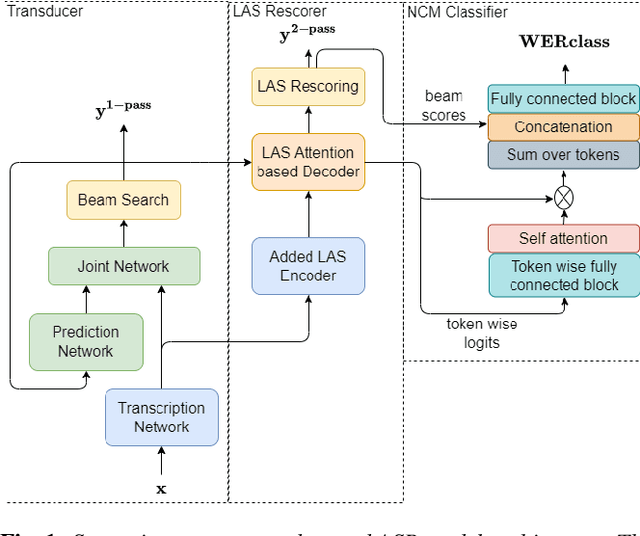

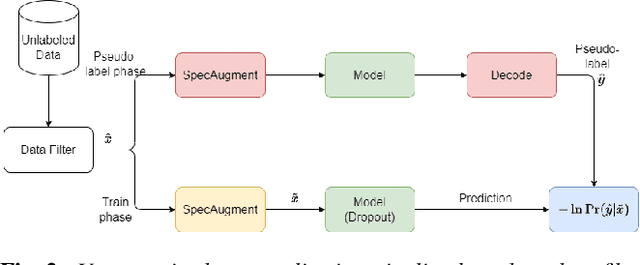
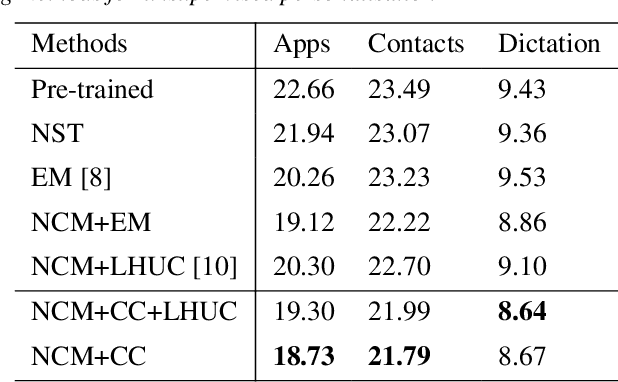
On-device Automatic Speech Recognition (ASR) models trained on speech data of a large population might underperform for individuals unseen during training. This is due to a domain shift between user data and the original training data, differed by user's speaking characteristics and environmental acoustic conditions. ASR personalisation is a solution that aims to exploit user data to improve model robustness. The majority of ASR personalisation methods assume labelled user data for supervision. Personalisation without any labelled data is challenging due to limited data size and poor quality of recorded audio samples. This work addresses unsupervised personalisation by developing a novel consistency based training method via pseudo-labelling. Our method achieves a relative Word Error Rate Reduction (WERR) of 17.3% on unlabelled training data and 8.1% on held-out data compared to a pre-trained model, and outperforms the current state-of-the art methods.
On-Device Speaker Anonymization of Acoustic Embeddings for ASR based onFlexible Location Gradient Reversal Layer
Jul 25, 2023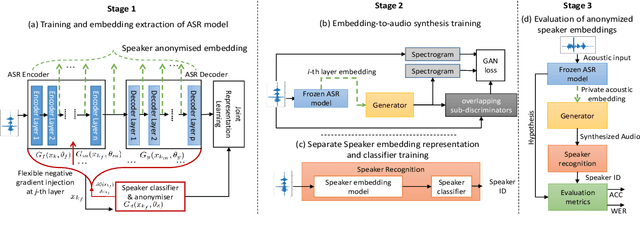
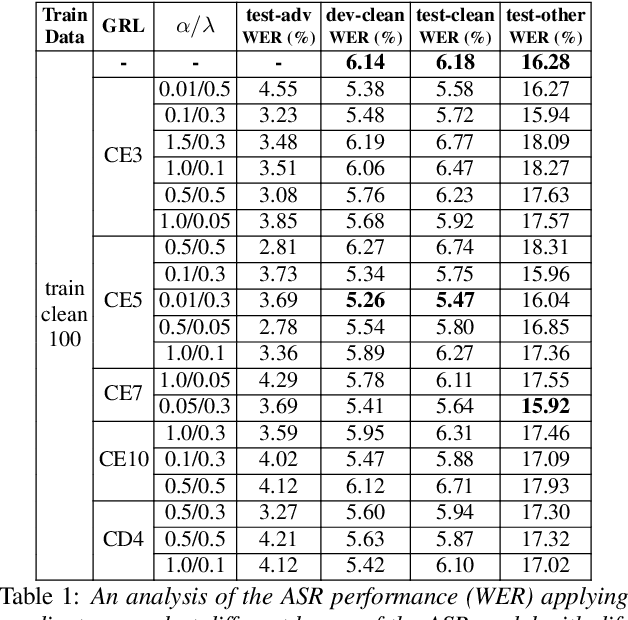

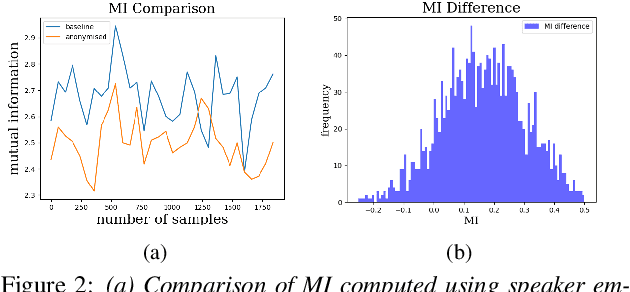
Smart devices serviced by large-scale AI models necessitates user data transfer to the cloud for inference. For speech applications, this means transferring private user information, e.g., speaker identity. Our paper proposes a privacy-enhancing framework that targets speaker identity anonymization while preserving speech recognition accuracy for our downstream task~-~Automatic Speech Recognition (ASR). The proposed framework attaches flexible gradient reversal based speaker adversarial layers to target layers within an ASR model, where speaker adversarial training anonymizes acoustic embeddings generated by the targeted layers to remove speaker identity. We propose on-device deployment by execution of initial layers of the ASR model, and transmitting anonymized embeddings to the cloud, where the rest of the model is executed while preserving privacy. Experimental results show that our method efficiently reduces speaker recognition relative accuracy by 33%, and improves ASR performance by achieving 6.2% relative Word Error Rate (WER) reduction.
On monoaural speech enhancement for automatic recognition of real noisy speech using mixture invariant training
May 03, 2022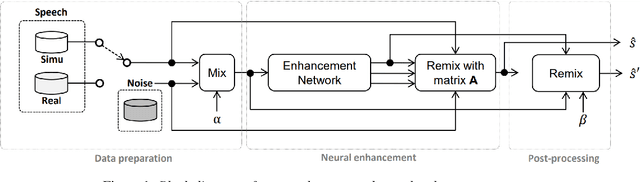
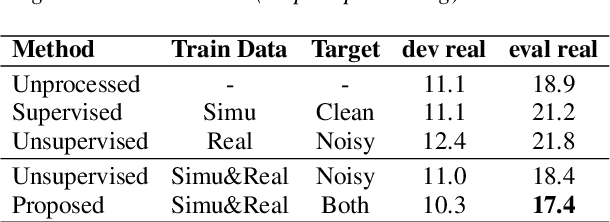
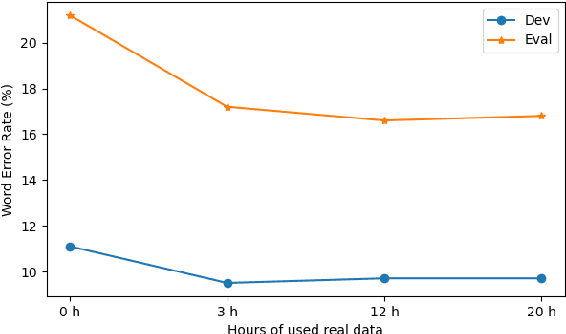
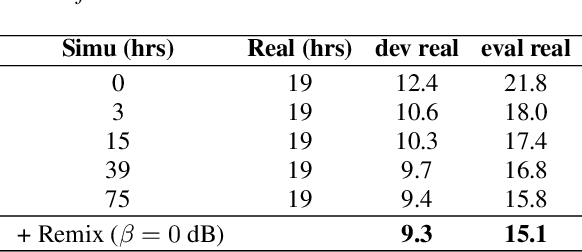
In this paper, we explore an improved framework to train a monoaural neural enhancement model for robust speech recognition. The designed training framework extends the existing mixture invariant training criterion to exploit both unpaired clean speech and real noisy data. It is found that the unpaired clean speech is crucial to improve quality of separated speech from real noisy speech. The proposed method also performs remixing of processed and unprocessed signals to alleviate the processing artifacts. Experiments on the single-channel CHiME-3 real test sets show that the proposed method improves significantly in terms of speech recognition performance over the enhancement system trained either on the mismatched simulated data in a supervised fashion or on the matched real data in an unsupervised fashion. Between 16% and 39% relative WER reduction has been achieved by the proposed system compared to the unprocessed signal using end-to-end and hybrid acoustic models without retraining on distorted data.
Teacher-Student MixIT for Unsupervised and Semi-supervised Speech Separation
Jun 16, 2021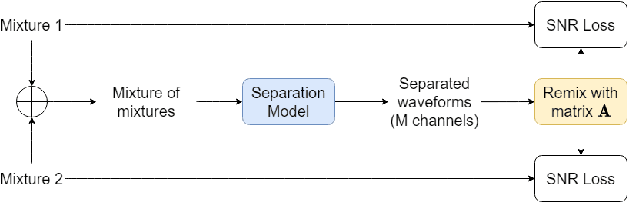
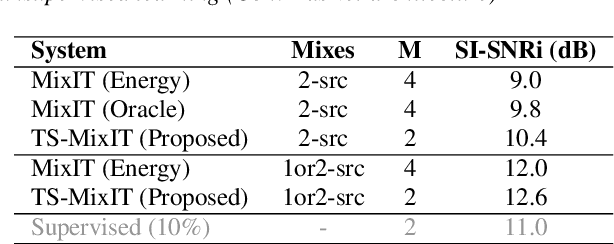
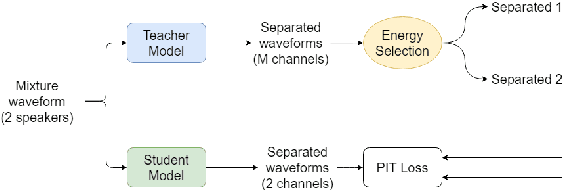
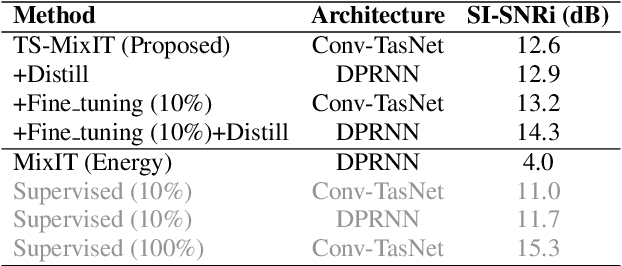
In this paper, we introduce a novel semi-supervised learning framework for end-to-end speech separation. The proposed method first uses mixtures of unseparated sources and the mixture invariant training (MixIT) criterion to train a teacher model. The teacher model then estimates separated sources that are used to train a student model with standard permutation invariant training (PIT). The student model can be fine-tuned with supervised data, i.e., paired artificial mixtures and clean speech sources, and further improved via model distillation. Experiments with single and multi channel mixtures show that the teacher-student training resolves the over-separation problem observed in the original MixIT method. Further, the semisupervised performance is comparable to a fully-supervised separation system trained using ten times the amount of supervised data.
Time-Domain Speech Extraction with Spatial Information and Multi Speaker Conditioning Mechanism
Feb 07, 2021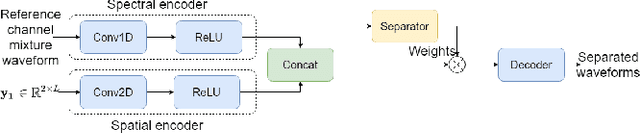
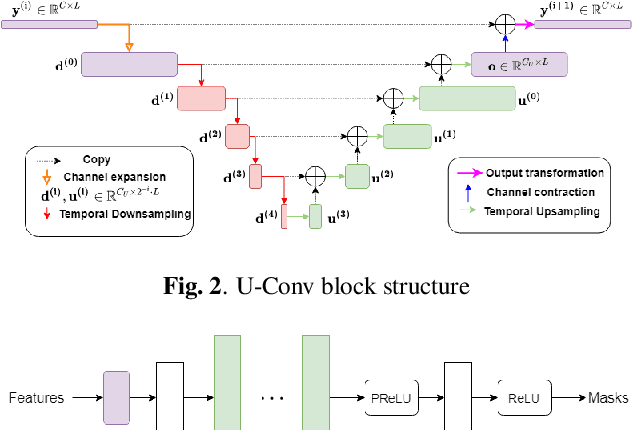

In this paper, we present a novel multi-channel speech extraction system to simultaneously extract multiple clean individual sources from a mixture in noisy and reverberant environments. The proposed method is built on an improved multi-channel time-domain speech separation network which employs speaker embeddings to identify and extract multiple targets without label permutation ambiguity. To efficiently inform the speaker information to the extraction model, we propose a new speaker conditioning mechanism by designing an additional speaker branch for receiving external speaker embeddings. Experiments on 2-channel WHAMR! data show that the proposed system improves by 9% relative the source separation performance over a strong multi-channel baseline, and it increases the speech recognition accuracy by more than 16% relative over the same baseline.
On End-to-end Multi-channel Time Domain Speech Separation in Reverberant Environments
Nov 11, 2020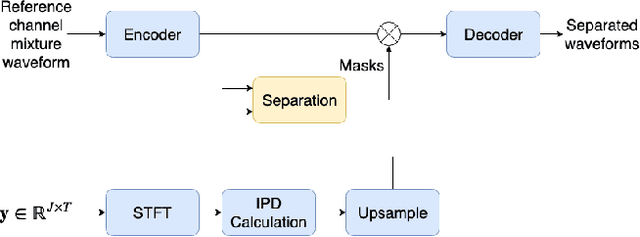

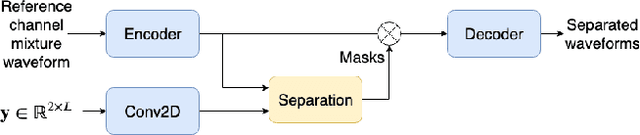
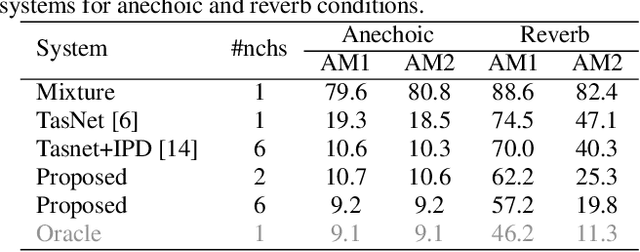
This paper introduces a new method for multi-channel time domain speech separation in reverberant environments. A fully-convolutional neural network structure has been used to directly separate speech from multiple microphone recordings, with no need of conventional spatial feature extraction. To reduce the influence of reverberation on spatial feature extraction, a dereverberation pre-processing method has been applied to further improve the separation performance. A spatialized version of wsj0-2mix dataset has been simulated to evaluate the proposed system. Both source separation and speech recognition performance of the separated signals have been evaluated objectively. Experiments show that the proposed fully-convolutional network improves the source separation metric and the word error rate (WER) by more than 13% and 50% relative, respectively, over a reference system with conventional features. Applying dereverberation as pre-processing to the proposed system can further reduce the WER by 29% relative using an acoustic model trained on clean and reverberated data.
* Presented at IEEE ICASSP 2020