 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValSub: Subsampling Validation Data to Mitigate Forgetting during ASR Personalization
Mar 12, 2025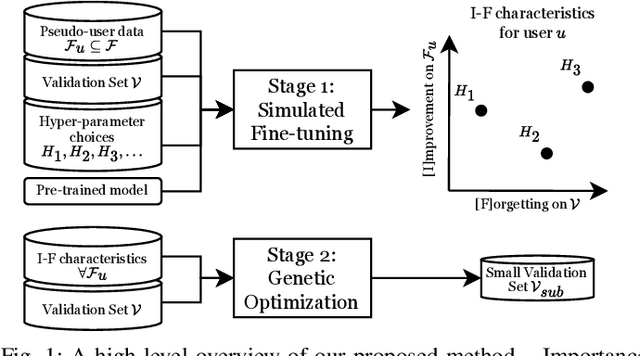
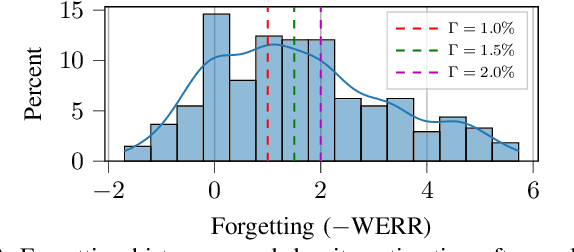
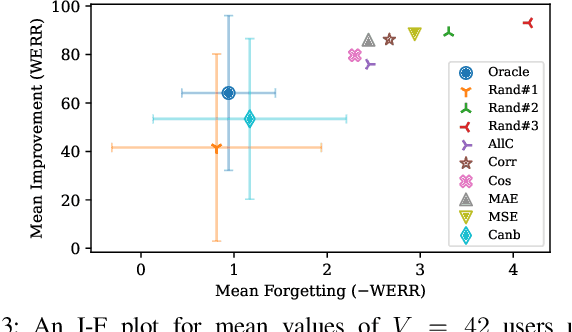
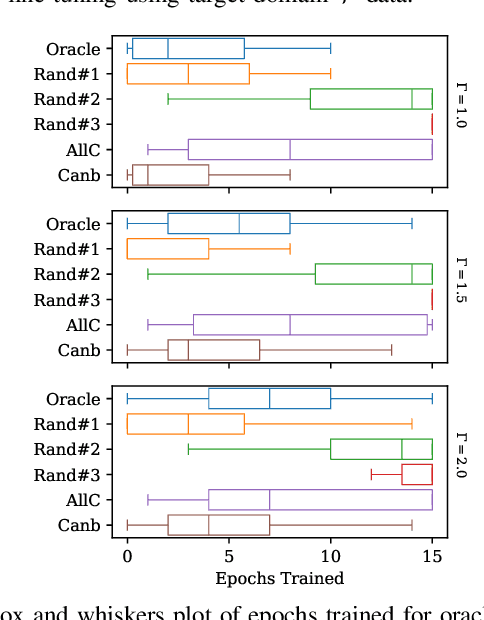
Automatic Speech Recognition (ASR) is widely used within consumer devices such as mobile phones. Recently, personalization or on-device model fine-tuning has shown that adaptation of ASR models towards target user speech improves their performance over rare words or accented speech. Despite these gains, fine-tuning on user data (target domain) risks the personalized model to forget knowledge about its original training distribution (source domain) i.e. catastrophic forgetting, leading to subpar general ASR performance. A simple and efficient approach to combat catastrophic forgetting is to measure forgetting via a validation set that represents the source domain distribution. However, such validation sets are large and impractical for mobile devices. Towards this, we propose a novel method to subsample a substantially large validation set into a smaller one while maintaining the ability to estimate forgetting. We demonstrate the efficacy of such a dataset in mitigating forgetting by utilizing it to dynamically determine the number of ideal fine-tuning epochs. When measuring the deviations in per user fine-tuning epochs against a 50x larger validation set (oracle), our method achieves a lower mean-absolute-error (3.39) compared to randomly selected subsets of the same size (3.78-8.65). Unlike random baselines, our method consistently tracks the oracle's behaviour across three different forgetting thresholds.
DP-DyLoRA: Fine-Tuning Transformer-Based Models On-Device under Differentially Private Federated Learning using Dynamic Low-Rank Adaptation
May 10, 2024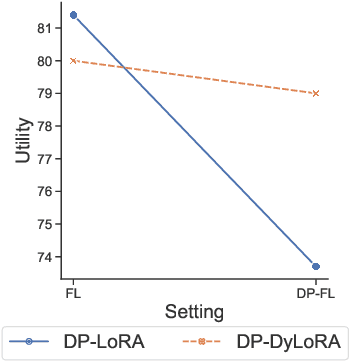
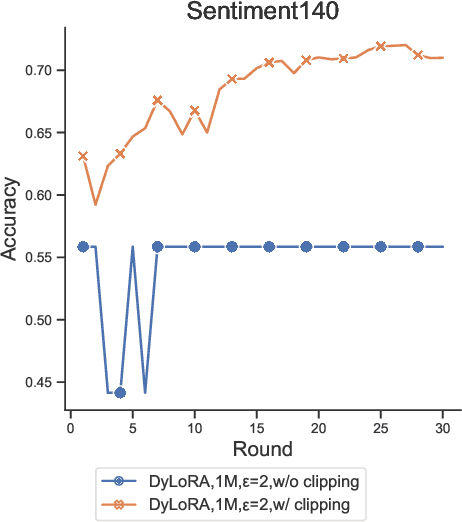
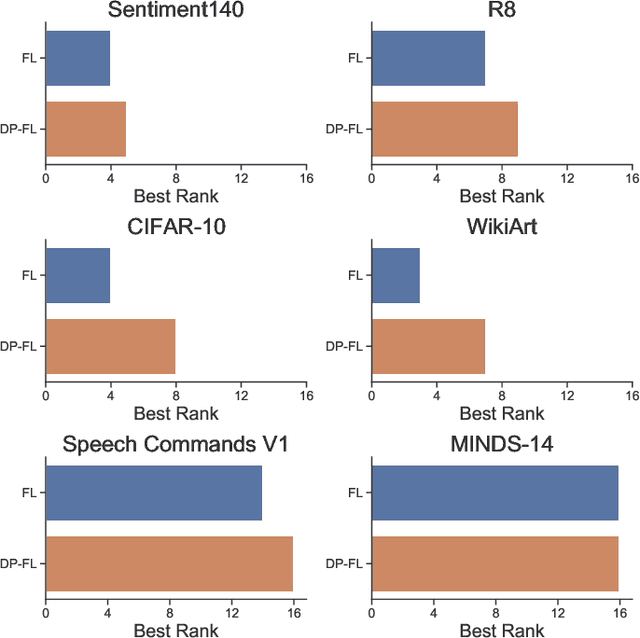
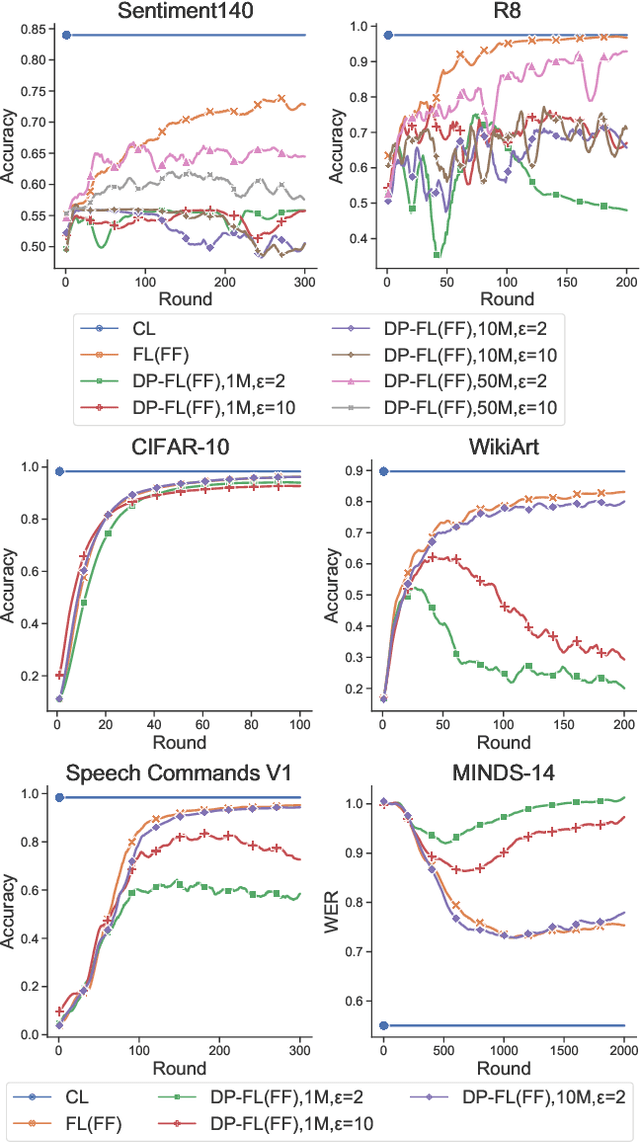
Federated learning (FL) allows clients in an Internet of Things (IoT) system to collaboratively train a global model without sharing their local data with a server. However, clients' contributions to the server can still leak sensitive information. Differential privacy (DP) addresses such leakage by providing formal privacy guarantees, with mechanisms that add randomness to the clients' contributions. The randomness makes it infeasible to train large transformer-based models, common in modern IoT systems. In this work, we empirically evaluate the practicality of fine-tuning large scale on-device transformer-based models with differential privacy in a federated learning system. We conduct comprehensive experiments on various system properties for tasks spanning a multitude of domains: speech recognition, computer vision (CV) and natural language understanding (NLU). Our results show that full fine-tuning under differentially private federated learning (DP-FL) generally leads to huge performance degradation which can be alleviated by reducing the dimensionality of contributions through parameter-efficient fine-tuning (PEFT). Our benchmarks of existing DP-PEFT methods show that DP-Low-Rank Adaptation (DP-LoRA) consistently outperforms other methods. An even more promising approach, DyLoRA, which makes the low rank variable, when naively combined with FL would straightforwardly break differential privacy. We therefore propose an adaptation method that can be combined with differential privacy and call it DP-DyLoRA. Finally, we are able to reduce the accuracy degradation and word error rate (WER) increase due to DP to less than 2% and 7% respectively with 1 million clients and a stringent privacy budget of {\epsilon}=2.
Consistency Based Unsupervised Self-training For ASR Personalisation
Jan 22, 2024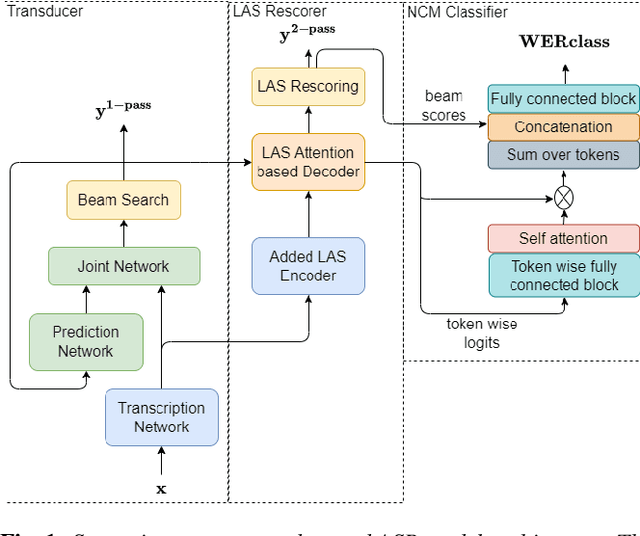

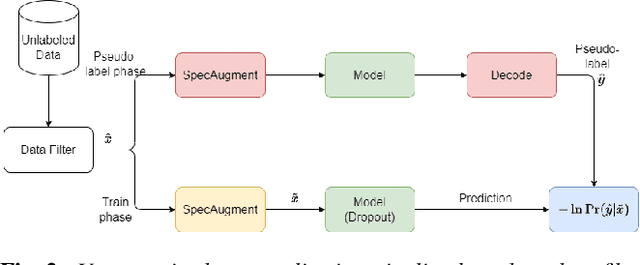
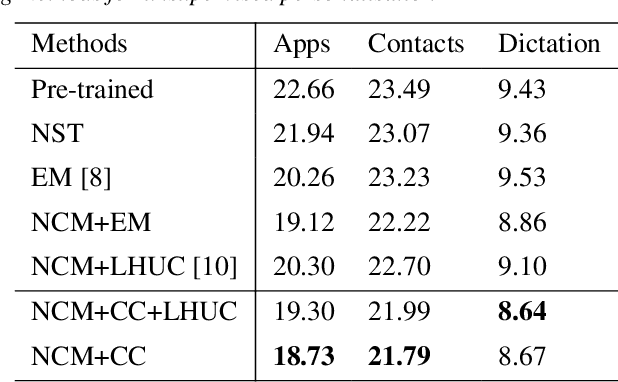
On-device Automatic Speech Recognition (ASR) models trained on speech data of a large population might underperform for individuals unseen during training. This is due to a domain shift between user data and the original training data, differed by user's speaking characteristics and environmental acoustic conditions. ASR personalisation is a solution that aims to exploit user data to improve model robustness. The majority of ASR personalisation methods assume labelled user data for supervision. Personalisation without any labelled data is challenging due to limited data size and poor quality of recorded audio samples. This work addresses unsupervised personalisation by developing a novel consistency based training method via pseudo-labelling. Our method achieves a relative Word Error Rate Reduction (WERR) of 17.3% on unlabelled training data and 8.1% on held-out data compared to a pre-trained model, and outperforms the current state-of-the art methods.
A general framework for scientifically inspired explanations in AI
Mar 02, 2020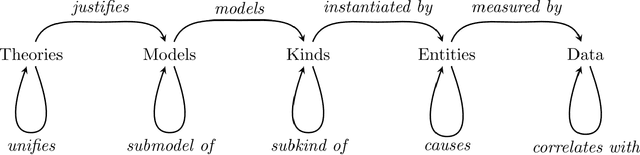
Explainability in AI is gaining attention in the computer science community in response to the increasing success of deep learning and the important need of justifying how such systems make predictions in life-critical applications. The focus of explainability in AI has predominantly been on trying to gain insights into how machine learning systems function by exploring relationships between input data and predicted outcomes or by extracting simpler interpretable models. Through literature surveys of philosophy and social science, authors have highlighted the sharp difference between these generated explanations and human-made explanations and claimed that current explanations in AI do not take into account the complexity of human interaction to allow for effective information passing to not-expert users. In this paper we instantiate the concept of structure of scientific explanation as the theoretical underpinning for a general framework in which explanations for AI systems can be implemented. This framework aims to provide the tools to build a "mental-model" of any AI system so that the interaction with the user can provide information on demand and be closer to the nature of human-made explanations. We illustrate how we can utilize this framework through two very different examples: an artificial neural network and a Prolog solver and we provide a possible implementation for both examples.
Saliency Maps Generation for Automatic Text Summarization
Jul 12, 2019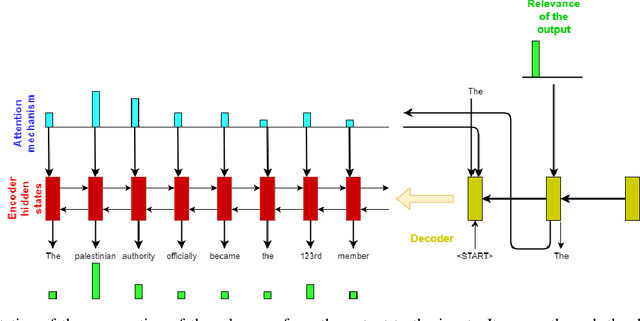


Saliency map generation techniques are at the forefront of explainable AI literature for a broad range of machine learning applications. Our goal is to question the limits of these approaches on more complex tasks. In this paper we apply Layer-Wise Relevance Propagation (LRP) to a sequence-to-sequence attention model trained on a text summarization dataset. We obtain unexpected saliency maps and discuss the rightfulness of these "explanations". We argue that we need a quantitative way of testing the counterfactual case to judge the truthfulness of the saliency maps. We suggest a protocol to check the validity of the importance attributed to the input and show that the saliency maps obtained sometimes capture the real use of the input features by the network, and sometimes do not. We use this example to discuss how careful we need to be when accepting them as explanation.