 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowW2N: Whispered-to-Normal Speech Conversion via Flow-Matching
Mar 04, 2026Whispered-to-normal (W2N) speech conversion aims to reconstruct missing phonation from whispered input while preserving content and speaker identity. This task is challenging due to temporal misalignment between whisper and voiced recordings and lack of paired data. We propose FlowW2N, a conditional flow matching approach that trains exclusively on synthetic, time-aligned whisper-normal pairs and conditions on domain-invariant features. We exploit high-level ASR embeddings that exhibits strong invariance between synthetic and real whispered speech, enabling generalization to real whispers despite never observing it during training. We verify this invariance across ASR layers and propose a selection criterion optimizing content informativeness and cross-domain invariance. Our method achieves SOTA intelligibility on the CHAINS and wTIMIT datasets, reducing Word Error Rate by 26-46% relative to prior work while using only 10 steps at inference and requiring no real paired data.
Robust Target Speaker Diarization and Separation via Augmented Speaker Embedding Sampling
Aug 08, 2025Traditional speech separation and speaker diarization approaches rely on prior knowledge of target speakers or a predetermined number of participants in audio signals. To address these limitations, recent advances focus on developing enrollment-free methods capable of identifying targets without explicit speaker labeling. This work introduces a new approach to train simultaneous speech separation and diarization using automatic identification of target speaker embeddings, within mixtures. Our proposed model employs a dual-stage training pipeline designed to learn robust speaker representation features that are resilient to background noise interference. Furthermore, we present an overlapping spectral loss function specifically tailored for enhancing diarization accuracy during overlapped speech frames. Experimental results show significant performance gains compared to the current SOTA baseline, achieving 71% relative improvement in DER and 69% in cpWER.
Diffusion based Text-to-Music Generation with Global and Local Text based Conditioning
Jan 27, 2025Diffusion based Text-To-Music (TTM) models generate music corresponding to text descriptions. Typically UNet based diffusion models condition on text embeddings generated from a pre-trained large language model or from a cross-modality audio-language representation model. This work proposes a diffusion based TTM, in which the UNet is conditioned on both (i) a uni-modal language model (e.g., T5) via cross-attention and (ii) a cross-modal audio-language representation model (e.g., CLAP) via Feature-wise Linear Modulation (FiLM). The diffusion model is trained to exploit both a local text representation from the T5 and a global representation from the CLAP. Furthermore, we propose modifications that extract both global and local representations from the T5 through pooling mechanisms that we call mean pooling and self-attention pooling. This approach mitigates the need for an additional encoder (e.g., CLAP) to extract a global representation, thereby reducing the number of model parameters. Our results show that incorporating the CLAP global embeddings to the T5 local embeddings enhances text adherence (KL=1.47) compared to a baseline model solely relying on the T5 local embeddings (KL=1.54). Alternatively, extracting global text embeddings directly from the T5 local embeddings through the proposed mean pooling approach yields superior generation quality (FAD=1.89) while exhibiting marginally inferior text adherence (KL=1.51) against the model conditioned on both CLAP and T5 text embeddings (FAD=1.94 and KL=1.47). Our proposed solution is not only efficient but also compact in terms of the number of parameters required.
persoDA: Personalized Data Augmentation for Personalized ASR
Jan 17, 2025



Data augmentation (DA) is ubiquitously used in training of Automatic Speech Recognition (ASR) models. DA offers increased data variability, robustness and generalization against different acoustic distortions. Recently, personalization of ASR models on mobile devices has been shown to improve Word Error Rate (WER). This paper evaluates data augmentation in this context and proposes persoDA; a DA method driven by user's data utilized to personalize ASR. persoDA aims to augment training with data specifically tuned towards acoustic characteristics of the end-user, as opposed to standard augmentation based on Multi-Condition Training (MCT) that applies random reverberation and noises. Our evaluation with an ASR conformer-based baseline trained on Librispeech and personalized for VOICES shows that persoDA achieves a 13.9% relative WER reduction over using standard data augmentation (using random noise & reverberation). Furthermore, persoDA shows 16% to 20% faster convergence over MCT.
persoDA: Personalized Data Augmentation forPersonalized ASR
Jan 15, 2025Data augmentation (DA) is ubiquitously used in training of Automatic Speech Recognition (ASR) models. DA offers increased data variability, robustness and generalization against different acoustic distortions. Recently, personalization of ASR models on mobile devices has been shown to improve Word Error Rate (WER). This paper evaluates data augmentation in this context and proposes persoDA; a DA method driven by user's data utilized to personalize ASR. persoDA aims to augment training with data specifically tuned towards acoustic characteristics of the end-user, as opposed to standard augmentation based on Multi-Condition Training (MCT) that applies random reverberation and noises. Our evaluation with an ASR conformer-based baseline trained on Librispeech and personalized for VOICES shows that persoDA achieves a 13.9% relative WER reduction over using standard data augmentation (using random noise & reverberation). Furthermore, persoDA shows 16% to 20% faster convergence over MCT.
Exploring compressibility of transformer based text-to-music (TTM) models
Jun 24, 2024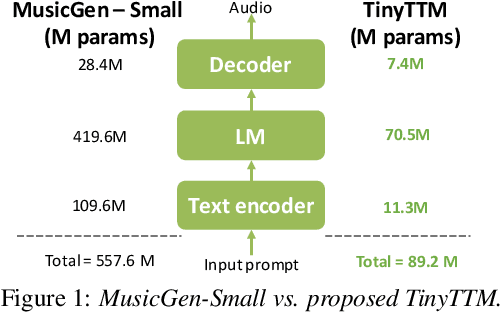
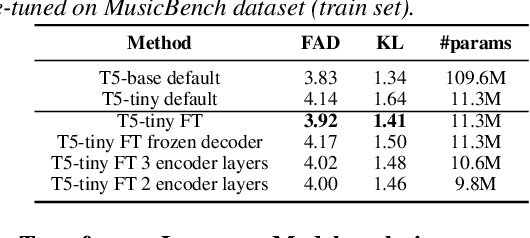
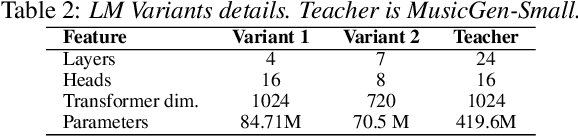
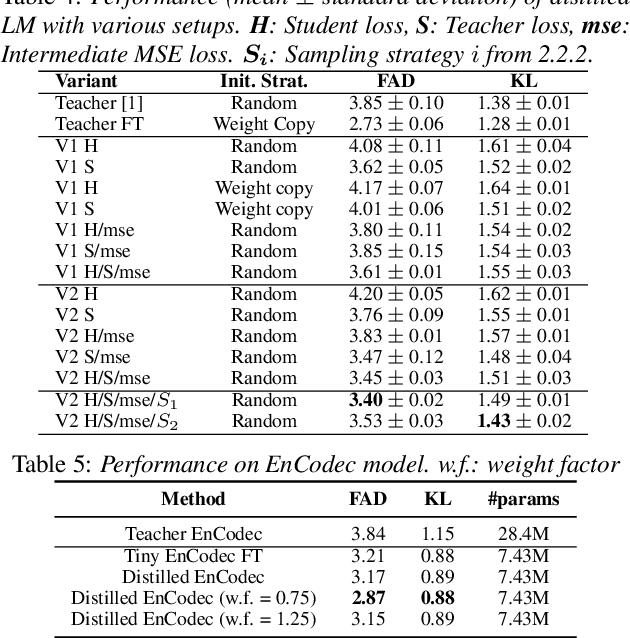
State-of-the art Text-To-Music (TTM) generative AI models are large and require desktop or server class compute, making them infeasible for deployment on mobile phones. This paper presents an analysis of trade-offs between model compression and generation performance of TTM models. We study compression through knowledge distillation and specific modifications that enable applicability over the various components of the TTM model (encoder, generative model and the decoder). Leveraging these methods we create TinyTTM (89.2M params) that achieves a FAD of 3.66 and KL of 1.32 on MusicBench dataset, better than MusicGen-Small (557.6M params) but not lower than MusicGen-small fine-tuned on MusicBench.
Locality enhanced dynamic biasing and sampling strategies for contextual ASR
Jan 23, 2024Automatic Speech Recognition (ASR) still face challenges when recognizing time-variant rare-phrases. Contextual biasing (CB) modules bias ASR model towards such contextually-relevant phrases. During training, a list of biasing phrases are selected from a large pool of phrases following a sampling strategy. In this work we firstly analyse different sampling strategies to provide insights into the training of CB for ASR with correlation plots between the bias embeddings among various training stages. Secondly, we introduce a neighbourhood attention (NA) that localizes self attention (SA) to the nearest neighbouring frames to further refine the CB output. The results show that this proposed approach provides on average a 25.84% relative WER improvement on LibriSpeech sets and rare-word evaluation compared to the baseline.
Consistency Based Unsupervised Self-training For ASR Personalisation
Jan 22, 2024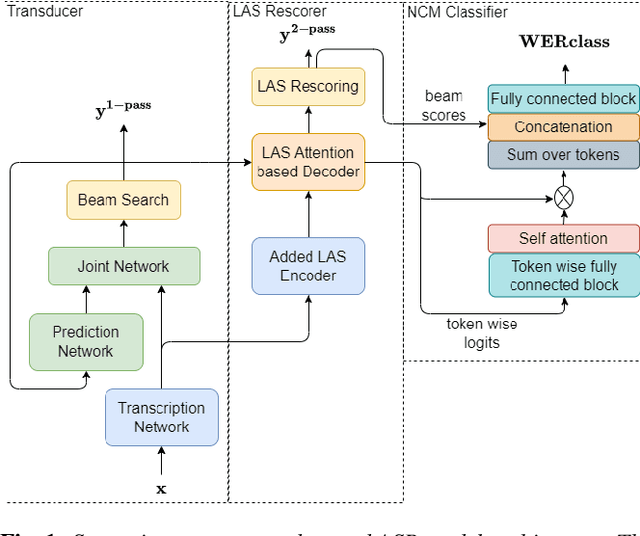

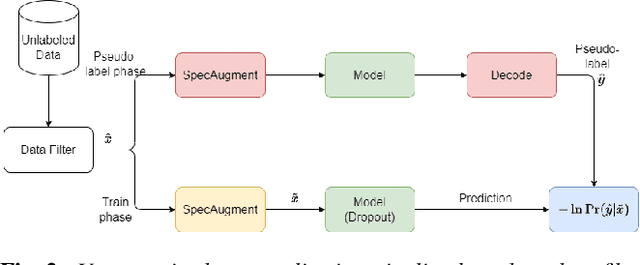
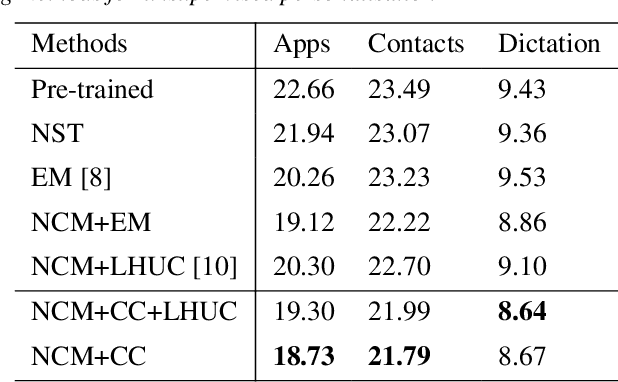
On-device Automatic Speech Recognition (ASR) models trained on speech data of a large population might underperform for individuals unseen during training. This is due to a domain shift between user data and the original training data, differed by user's speaking characteristics and environmental acoustic conditions. ASR personalisation is a solution that aims to exploit user data to improve model robustness. The majority of ASR personalisation methods assume labelled user data for supervision. Personalisation without any labelled data is challenging due to limited data size and poor quality of recorded audio samples. This work addresses unsupervised personalisation by developing a novel consistency based training method via pseudo-labelling. Our method achieves a relative Word Error Rate Reduction (WERR) of 17.3% on unlabelled training data and 8.1% on held-out data compared to a pre-trained model, and outperforms the current state-of-the art methods.
On-Device Speaker Anonymization of Acoustic Embeddings for ASR based onFlexible Location Gradient Reversal Layer
Jul 25, 2023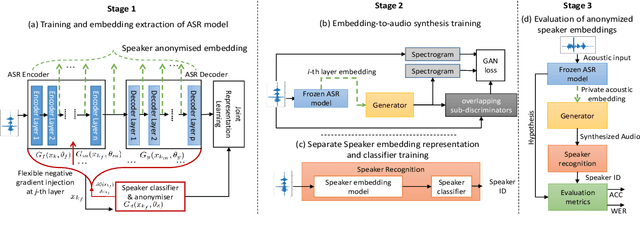
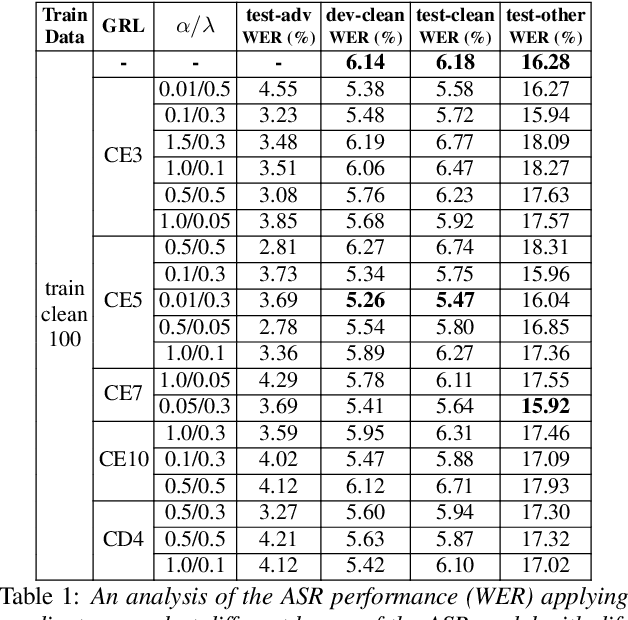

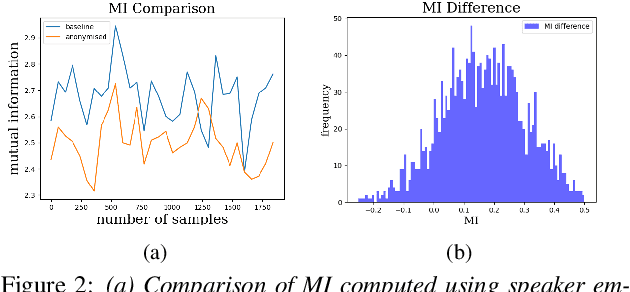
Smart devices serviced by large-scale AI models necessitates user data transfer to the cloud for inference. For speech applications, this means transferring private user information, e.g., speaker identity. Our paper proposes a privacy-enhancing framework that targets speaker identity anonymization while preserving speech recognition accuracy for our downstream task~-~Automatic Speech Recognition (ASR). The proposed framework attaches flexible gradient reversal based speaker adversarial layers to target layers within an ASR model, where speaker adversarial training anonymizes acoustic embeddings generated by the targeted layers to remove speaker identity. We propose on-device deployment by execution of initial layers of the ASR model, and transmitting anonymized embeddings to the cloud, where the rest of the model is executed while preserving privacy. Experimental results show that our method efficiently reduces speaker recognition relative accuracy by 33%, and improves ASR performance by achieving 6.2% relative Word Error Rate (WER) reduction.
Empirical Interpretation of the Relationship Between Speech Acoustic Context and Emotion Recognition
Jun 30, 2023



Speech emotion recognition (SER) is vital for obtaining emotional intelligence and understanding the contextual meaning of speech. Variations of consonant-vowel (CV) phonemic boundaries can enrich acoustic context with linguistic cues, which impacts SER. In practice, speech emotions are treated as single labels over an acoustic segment for a given time duration. However, phone boundaries within speech are not discrete events, therefore the perceived emotion state should also be distributed over potentially continuous time-windows. This research explores the implication of acoustic context and phone boundaries on local markers for SER using an attention-based approach. The benefits of using a distributed approach to speech emotion understanding are supported by the results of cross-corpora analysis experiments. Experiments where phones and words are mapped to the attention vectors along with the fundamental frequency to observe the overlapping distributions and thereby the relationship between acoustic context and emotion. This work aims to bridge psycholinguistic theory research with computational modelling for SER.