 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum vs. Classical Machine Learning: A Benchmark Study for Financial Prediction
Jan 07, 2026In this paper, we present a reproducible benchmarking framework that systematically compares QML models with architecture-matched classical counterparts across three financial tasks: (i) directional return prediction on U.S. and Turkish equities, (ii) live-trading simulation with Quantum LSTMs versus classical LSTMs on the S\&P 500, and (iii) realized volatility forecasting using Quantum Support Vector Regression. By standardizing data splits, features, and evaluation metrics, our study provides a fair assessment of when current-generation QML models can match or exceed classical methods. Our results reveal that quantum approaches show performance gains when data structure and circuit design are well aligned. In directional classification, hybrid quantum neural networks surpass the parameter-matched ANN by \textbf{+3.8 AUC} and \textbf{+3.4 accuracy points} on \texttt{AAPL} stock and by \textbf{+4.9 AUC} and \textbf{+3.6 accuracy points} on Turkish stock \texttt{KCHOL}. In live trading, the QLSTM achieves higher risk-adjusted returns in \textbf{two of four} S\&P~500 regimes. For volatility forecasting, an angle-encoded QSVR attains the \textbf{lowest QLIKE} on \texttt{KCHOL} and remains within $\sim$0.02-0.04 QLIKE of the best classical kernels on \texttt{S\&P~500} and \texttt{AAPL}. Our benchmarking framework clearly identifies the scenarios where current QML architectures offer tangible improvements and where established classical methods continue to dominate.
Progressive unsupervised domain adaptation for ASR using ensemble models and multi-stage training
Feb 07, 2024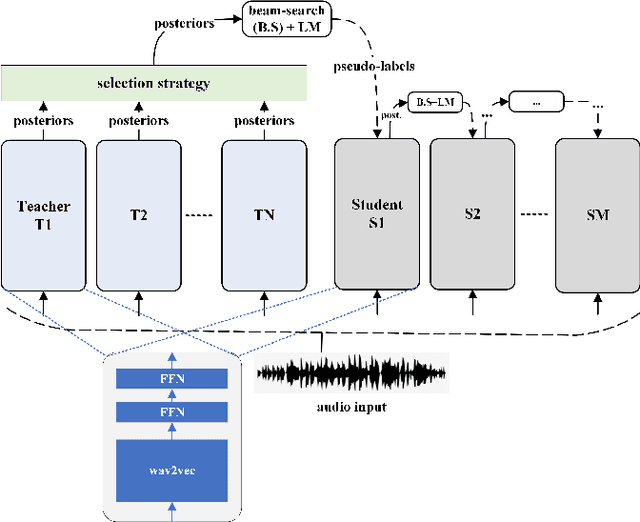
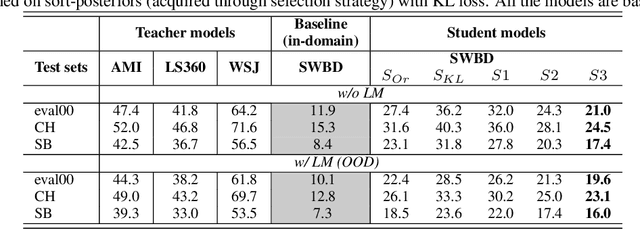
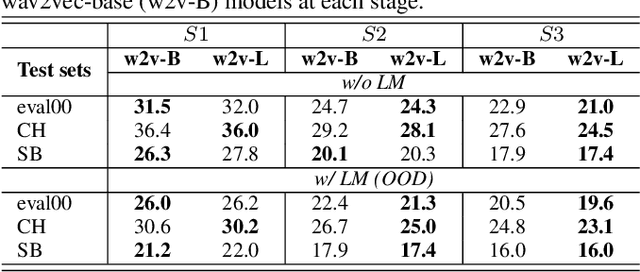
In Automatic Speech Recognition (ASR), teacher-student (T/S) training has shown to perform well for domain adaptation with small amount of training data. However, adaption without ground-truth labels is still challenging. A previous study has shown the effectiveness of using ensemble teacher models in T/S training for unsupervised domain adaptation (UDA) but its performance still lags behind compared to the model trained on in-domain data. This paper proposes a method to yield better UDA by training multi-stage students with ensemble teacher models. Initially, multiple teacher models are trained on labelled data from read and meeting domains. These teachers are used to train a student model on unlabelled out-of-domain telephone speech data. To improve the adaptation, subsequent student models are trained sequentially considering previously trained model as their teacher. Experiments are conducted with three teachers trained on AMI, WSJ and LibriSpeech and three stages of students on SwitchBoard data. Results shown on eval00 test set show significant WER improvement with multi-stage training with an absolute gain of 9.8%, 7.7% and 3.3% at each stage.
MUST: A Multilingual Student-Teacher Learning approach for low-resource speech recognition
Oct 29, 2023Student-teacher learning or knowledge distillation (KD) has been previously used to address data scarcity issue for training of speech recognition (ASR) systems. However, a limitation of KD training is that the student model classes must be a proper or improper subset of the teacher model classes. It prevents distillation from even acoustically similar languages if the character sets are not same. In this work, the aforementioned limitation is addressed by proposing a MUltilingual Student-Teacher (MUST) learning which exploits a posteriors mapping approach. A pre-trained mapping model is used to map posteriors from a teacher language to the student language ASR. These mapped posteriors are used as soft labels for KD learning. Various teacher ensemble schemes are experimented to train an ASR model for low-resource languages. A model trained with MUST learning reduces relative character error rate (CER) up to 9.5% in comparison with a baseline monolingual ASR.
Towards domain generalisation in ASR with elitist sampling and ensemble knowledge distillation
Mar 01, 2023



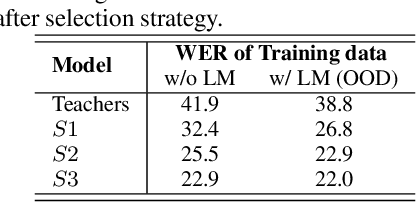
Knowledge distillation has widely been used for model compression and domain adaptation for speech applications. In the presence of multiple teachers, knowledge can easily be transferred to the student by averaging the models output. However, previous research shows that the student do not adapt well with such combination. This paper propose to use an elitist sampling strategy at the output of ensemble teacher models to select the best-decoded utterance generated by completely out-of-domain teacher models for generalizing unseen domain. The teacher models are trained on AMI, LibriSpeech and WSJ while the student is adapted for the Switchboard data. The results show that with the selection strategy based on the individual models posteriors the student model achieves a better WER compared to all the teachers and baselines with a minimum absolute improvement of about 8.4 percent. Furthermore, an insights on the model adaptation with out-of-domain data has also been studied via correlation analysis.
Unsupervised data selection for Speech Recognition with contrastive loss ratios
Jul 25, 2022
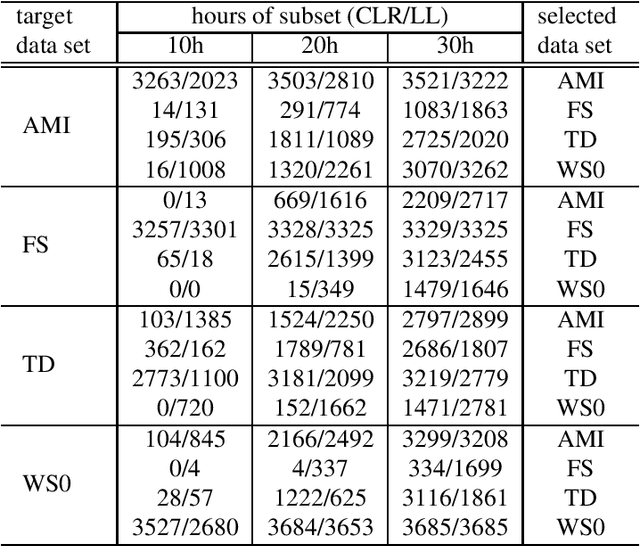
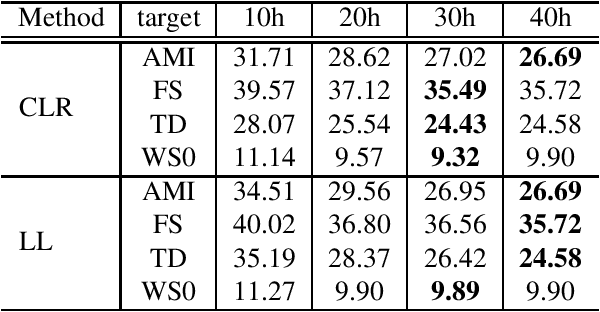
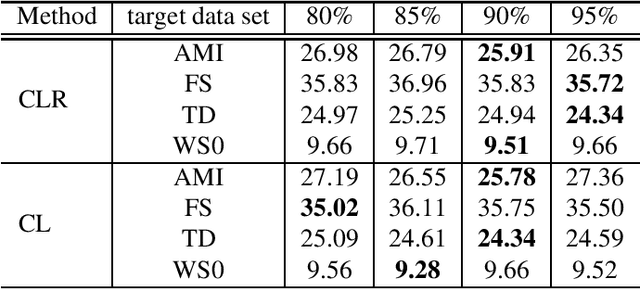
This paper proposes an unsupervised data selection method by using a submodular function based on contrastive loss ratios of target and training data sets. A model using a contrastive loss function is trained on both sets. Then the ratio of frame-level losses for each model is used by a submodular function. By using the submodular function, a training set for automatic speech recognition matching the target data set is selected. Experiments show that models trained on the data sets selected by the proposed method outperform the selection method based on log-likelihoods produced by GMM-HMM models, in terms of word error rate (WER). When selecting a fixed amount, e.g. 10 hours of data, the difference between the results of two methods on Tedtalks was 20.23% WER relative. The method can also be used to select data with the aim of minimising negative transfer, while maintaining or improving on performance of models trained on the whole training set. Results show that the WER on the WSJCAM0 data set was reduced by 6.26% relative when selecting 85% from the whole data set.
* 5 pages, accepted by ICASSP 2022