 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Interpretation of the Relationship Between Speech Acoustic Context and Emotion Recognition
Jun 30, 2023



Speech emotion recognition (SER) is vital for obtaining emotional intelligence and understanding the contextual meaning of speech. Variations of consonant-vowel (CV) phonemic boundaries can enrich acoustic context with linguistic cues, which impacts SER. In practice, speech emotions are treated as single labels over an acoustic segment for a given time duration. However, phone boundaries within speech are not discrete events, therefore the perceived emotion state should also be distributed over potentially continuous time-windows. This research explores the implication of acoustic context and phone boundaries on local markers for SER using an attention-based approach. The benefits of using a distributed approach to speech emotion understanding are supported by the results of cross-corpora analysis experiments. Experiments where phones and words are mapped to the attention vectors along with the fundamental frequency to observe the overlapping distributions and thereby the relationship between acoustic context and emotion. This work aims to bridge psycholinguistic theory research with computational modelling for SER.
Towards domain generalisation in ASR with elitist sampling and ensemble knowledge distillation
Mar 01, 2023



Knowledge distillation has widely been used for model compression and domain adaptation for speech applications. In the presence of multiple teachers, knowledge can easily be transferred to the student by averaging the models output. However, previous research shows that the student do not adapt well with such combination. This paper propose to use an elitist sampling strategy at the output of ensemble teacher models to select the best-decoded utterance generated by completely out-of-domain teacher models for generalizing unseen domain. The teacher models are trained on AMI, LibriSpeech and WSJ while the student is adapted for the Switchboard data. The results show that with the selection strategy based on the individual models posteriors the student model achieves a better WER compared to all the teachers and baselines with a minimum absolute improvement of about 8.4 percent. Furthermore, an insights on the model adaptation with out-of-domain data has also been studied via correlation analysis.
Dynamic Kernels and Channel Attention with Multi-Layer Embedding Aggregation for Speaker Verification
Nov 03, 2022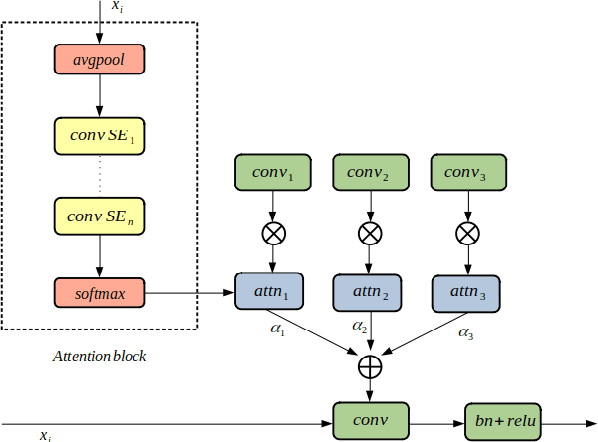



State-of-the-art speaker verification frameworks have typically focused on speech enhancement techniques with increasingly deeper (more layers) and wider (number of channels) models to improve their verification performance. Instead, this paper proposes an approach to increase the model resolution capability using attention-based dynamic kernels in a convolutional neural network to adapt the model parameters to be feature-conditioned. The attention weights on the kernels are further distilled by channel attention and multi-layer feature aggregation to learn global features from speech. This approach provides an efficient solution to improving representation capacity with lower data resources. This is due to the self-adaptation to inputs of the structures of the model parameters. The proposed dynamic convolutional model achieved 1.62\% EER and 0.18 miniDCF on the VoxCeleb1 test set and has a 17\% relative improvement compared to the ECAPA-TDNN.
Probing Statistical Representations For End-To-End ASR
Nov 03, 2022



End-to-End automatic speech recognition (ASR) models aim to learn a generalised speech representation to perform recognition. In this domain there is little research to analyse internal representation dependencies and their relationship to modelling approaches. This paper investigates cross-domain language model dependencies within transformer architectures using SVCCA and uses these insights to exploit modelling approaches. It was found that specific neural representations within the transformer layers exhibit correlated behaviour which impacts recognition performance. Altogether, this work provides analysis of the modelling approaches affecting contextual dependencies and ASR performance, and can be used to create or adapt better performing End-to-End ASR models and also for downstream tasks.
Insights on Neural Representations for End-to-End Speech Recognition
May 19, 2022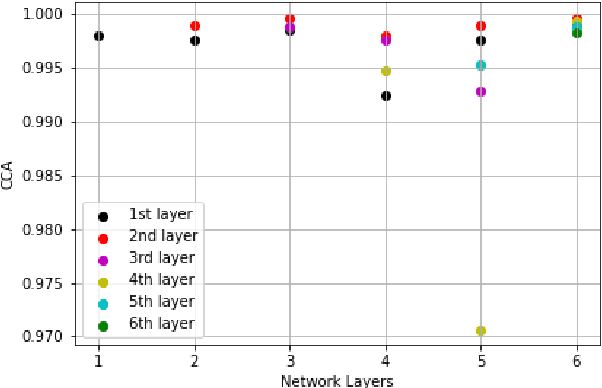

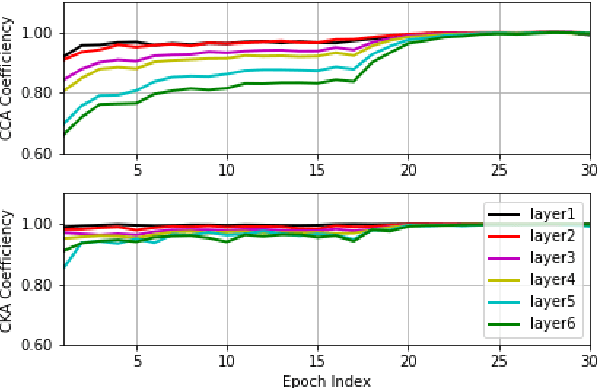
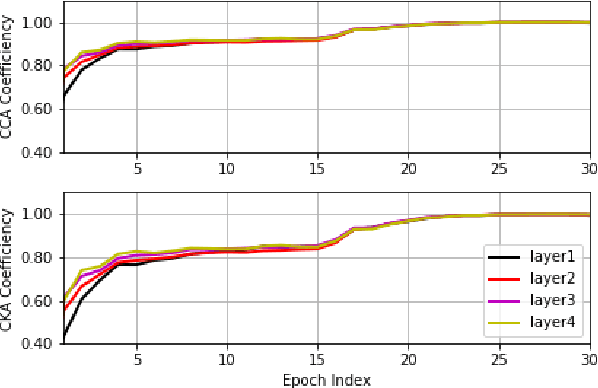
End-to-end automatic speech recognition (ASR) models aim to learn a generalised speech representation. However, there are limited tools available to understand the internal functions and the effect of hierarchical dependencies within the model architecture. It is crucial to understand the correlations between the layer-wise representations, to derive insights on the relationship between neural representations and performance. Previous investigations of network similarities using correlation analysis techniques have not been explored for End-to-End ASR models. This paper analyses and explores the internal dynamics between layers during training with CNN, LSTM and Transformer based approaches using Canonical correlation analysis (CCA) and centered kernel alignment (CKA) for the experiments. It was found that neural representations within CNN layers exhibit hierarchical correlation dependencies as layer depth increases but this is mostly limited to cases where neural representation correlates more closely. This behaviour is not observed in LSTM architecture, however there is a bottom-up pattern observed across the training process, while Transformer encoder layers exhibit irregular coefficiency correlation as neural depth increases. Altogether, these results provide new insights into the role that neural architectures have upon speech recognition performance. More specifically, these techniques can be used as indicators to build better performing speech recognition models.
* Submitted to Interspeech 2021