 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Kernels and Channel Attention with Multi-Layer Embedding Aggregation for Speaker Verification
Paper and Code
Nov 03, 2022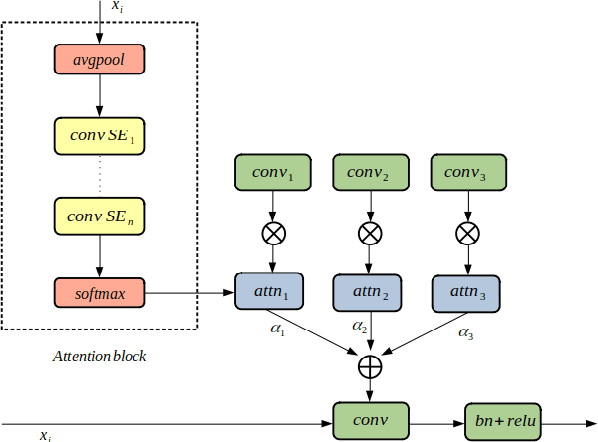



State-of-the-art speaker verification frameworks have typically focused on speech enhancement techniques with increasingly deeper (more layers) and wider (number of channels) models to improve their verification performance. Instead, this paper proposes an approach to increase the model resolution capability using attention-based dynamic kernels in a convolutional neural network to adapt the model parameters to be feature-conditioned. The attention weights on the kernels are further distilled by channel attention and multi-layer feature aggregation to learn global features from speech. This approach provides an efficient solution to improving representation capacity with lower data resources. This is due to the self-adaptation to inputs of the structures of the model parameters. The proposed dynamic convolutional model achieved 1.62\% EER and 0.18 miniDCF on the VoxCeleb1 test set and has a 17\% relative improvement compared to the ECAPA-TDNN.