 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition-invariant Fine-tuning of Speech Enhancement Models with Self-supervised Speech Representations
Jan 28, 2026Integrating front-end speech enhancement (SE) models with self-supervised learning (SSL)-based speech models is effective for downstream tasks in noisy conditions. SE models are commonly fine-tuned using SSL representations with mean squared error (MSE) loss between enhanced and clean speech. However, MSE is prone to exploiting positional embeddings in SSL models, allowing the objective to be minimised through positional correlations instead of content-related information. This work frames the problem as a general limitation of self-supervised representation fine-tuning and investigates it through representation-guided SE. Two strategies are considered: (1) zero-padding, previously explored in SSL pre-training but here examined in the fine-tuning setting, and (2) speed perturbations with a soft-DTW loss. Experiments show that the soft-DTW-based approach achieves faster convergence and improved downstream performance, underscoring the importance of position-invariant fine-tuning in SSL-based speech modelling.
Towards a Unified Benchmark for Arabic Pronunciation Assessment: Quranic Recitation as Case Study
Jun 09, 2025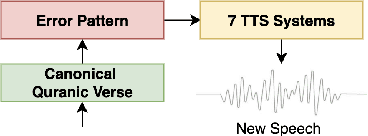
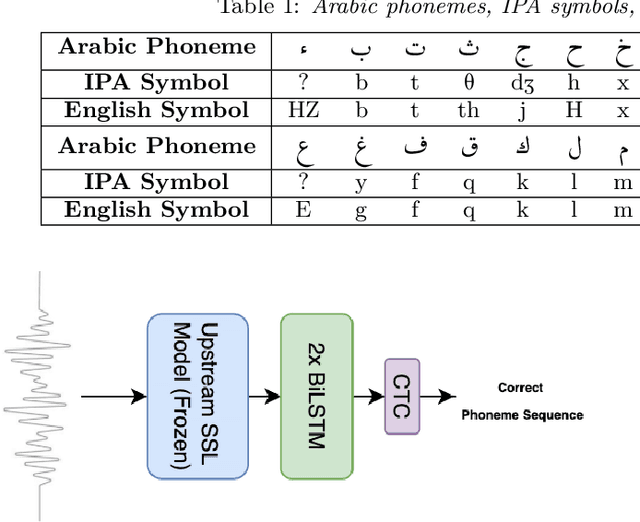

We present a unified benchmark for mispronunciation detection in Modern Standard Arabic (MSA) using Qur'anic recitation as a case study. Our approach lays the groundwork for advancing Arabic pronunciation assessment by providing a comprehensive pipeline that spans data processing, the development of a specialized phoneme set tailored to the nuances of MSA pronunciation, and the creation of the first publicly available test set for this task, which we term as the Qur'anic Mispronunciation Benchmark (QuranMB.v1). Furthermore, we evaluate several baseline models to provide initial performance insights, thereby highlighting both the promise and the challenges inherent in assessing MSA pronunciation. By establishing this standardized framework, we aim to foster further research and development in pronunciation assessment in Arabic language technology and related applications.
Methods for Automatic Matrix Language Determination of Code-Switched Speech
Oct 03, 2024



Code-switching (CS) is the process of speakers interchanging between two or more languages which in the modern world becomes increasingly common. In order to better describe CS speech the Matrix Language Frame (MLF) theory introduces the concept of a Matrix Language, which is the language that provides the grammatical structure for a CS utterance. In this work the MLF theory was used to develop systems for Matrix Language Identity (MLID) determination. The MLID of English/Mandarin and English/Spanish CS text and speech was compared to acoustic language identity (LID), which is a typical way to identify a language in monolingual utterances. MLID predictors from audio show higher correlation with the textual principles than LID in all cases while also outperforming LID in an MLID recognition task based on F1 macro (60\%) and correlation score (0.38). This novel approach has identified that non-English languages (Mandarin and Spanish) are preferred over the English language as the ML contrary to the monolingual choice of LID.
Using Speech Foundational Models in Loss Functions for Hearing Aid Speech Enhancement
Jul 18, 2024Machine learning techniques are an active area of research for speech enhancement for hearing aids, with one particular focus on improving the intelligibility of a noisy speech signal. Recent work has shown that feature encodings from self-supervised speech representation models can effectively capture speech intelligibility. In this work, it is shown that the distance between self-supervised speech representations of clean and noisy speech correlates more strongly with human intelligibility ratings than other signal-based metrics. Experiments show that training a speech enhancement model using this distance as part of a loss function improves the performance over using an SNR-based loss function, demonstrated by an increase in HASPI, STOI, PESQ and SI-SNR scores. This method takes inference of a high parameter count model only at training time, meaning the speech enhancement model can remain smaller, as is required for hearing aids.
Improving Accented Speech Recognition using Data Augmentation based on Unsupervised Text-to-Speech Synthesis
Jul 04, 2024



This paper investigates the use of unsupervised text-to-speech synthesis (TTS) as a data augmentation method to improve accented speech recognition. TTS systems are trained with a small amount of accented speech training data and their pseudo-labels rather than manual transcriptions, and hence unsupervised. This approach enables the use of accented speech data without manual transcriptions to perform data augmentation for accented speech recognition. Synthetic accented speech data, generated from text prompts by using the TTS systems, are then combined with available non-accented speech data to train automatic speech recognition (ASR) systems. ASR experiments are performed in a self-supervised learning framework using a Wav2vec2.0 model which was pre-trained on large amount of unsupervised accented speech data. The accented speech data for training the unsupervised TTS are read speech, selected from L2-ARCTIC and British Isles corpora, while spontaneous conversational speech from the Edinburgh international accents of English corpus are used as the evaluation data. Experimental results show that Wav2vec2.0 models which are fine-tuned to downstream ASR task with synthetic accented speech data, generated by the unsupervised TTS, yield up to 6.1% relative word error rate reductions compared to a Wav2vec2.0 baseline which is fine-tuned with the non-accented speech data from Librispeech corpus.
Transcription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
Jun 13, 2024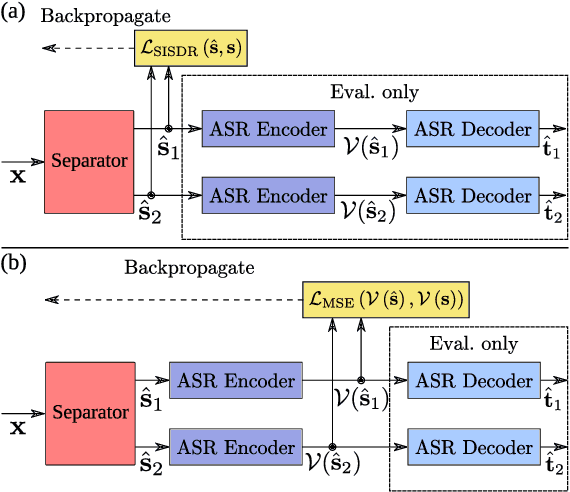

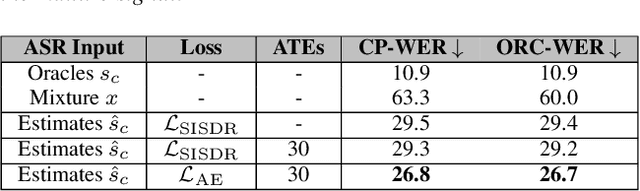
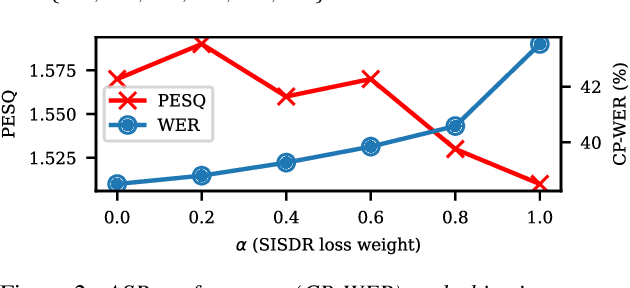
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
LASER: Learning by Aligning Self-supervised Representations of Speech for Improving Content-related Tasks
Jun 13, 2024



Self-supervised learning (SSL)-based speech models are extensively used for full-stack speech processing. However, it has been observed that improving SSL-based speech representations using unlabeled speech for content-related tasks is challenging and computationally expensive. Recent attempts have been made to address this issue with cost-effective self-supervised fine-tuning (SSFT) approaches. Continuing in this direction, a cost-effective SSFT method named "LASER: Learning by Aligning Self-supervised Representations" is presented. LASER is based on the soft-DTW alignment loss with temporal regularisation term. Experiments are conducted with HuBERT and WavLM models and evaluated on the SUPERB benchmark for two content-related tasks: automatic speech recognition (ASR) and phoneme recognition (PR). A relative improvement of 3.7% and 8.2% for HuBERT, and 4.1% and 11.7% for WavLM are observed, for the ASR and PR tasks respectively, with only < 3 hours of fine-tuning on a single GPU.
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Jun 11, 2024Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
1st Place Solution to Odyssey Emotion Recognition Challenge Task1: Tackling Class Imbalance Problem
May 30, 2024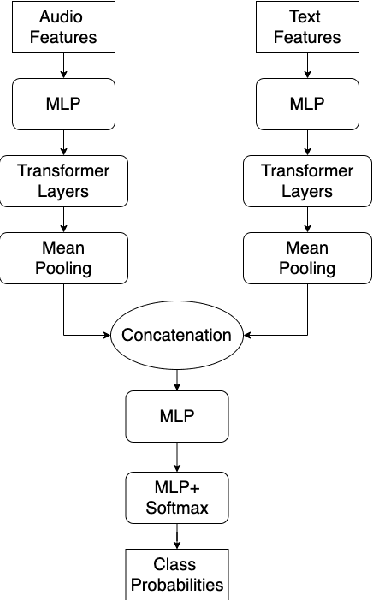



Speech emotion recognition is a challenging classification task with natural emotional speech, especially when the distribution of emotion types is imbalanced in the training and test data. In this case, it is more difficult for a model to learn to separate minority classes, resulting in those sometimes being ignored or frequently misclassified. Previous work has utilised class weighted loss for training, but problems remain as it sometimes causes over-fitting for minor classes or under-fitting for major classes. This paper presents the system developed by a multi-site team for the participation in the Odyssey 2024 Emotion Recognition Challenge Track-1. The challenge data has the aforementioned properties and therefore the presented systems aimed to tackle these issues, by introducing focal loss in optimisation when applying class weighted loss. Specifically, the focal loss is further weighted by prior-based class weights. Experimental results show that combining these two approaches brings better overall performance, by sacrificing performance on major classes. The system further employs a majority voting strategy to combine the outputs of an ensemble of 7 models. The models are trained independently, using different acoustic features and loss functions - with the aim to have different properties for different data. Hence these models show different performance preferences on major classes and minor classes. The ensemble system output obtained the best performance in the challenge, ranking top-1 among 68 submissions. It also outperformed all single models in our set. On the Odyssey 2024 Emotion Recognition Challenge Task-1 data the system obtained a Macro-F1 score of 35.69% and an accuracy of 37.32%.
Automatic Speech Recognition System-Independent Word Error Rate Estimation
Apr 26, 2024



Word error rate (WER) is a metric used to evaluate the quality of transcriptions produced by Automatic Speech Recognition (ASR) systems. In many applications, it is of interest to estimate WER given a pair of a speech utterance and a transcript. Previous work on WER estimation focused on building models that are trained with a specific ASR system in mind (referred to as ASR system-dependent). These are also domain-dependent and inflexible in real-world applications. In this paper, a hypothesis generation method for ASR System-Independent WER estimation (SIWE) is proposed. In contrast to prior work, the WER estimators are trained using data that simulates ASR system output. Hypotheses are generated using phonetically similar or linguistically more likely alternative words. In WER estimation experiments, the proposed method reaches a similar performance to ASR system-dependent WER estimators on in-domain data and achieves state-of-the-art performance on out-of-domain data. On the out-of-domain data, the SIWE model outperformed the baseline estimators in root mean square error and Pearson correlation coefficient by relative 17.58% and 18.21%, respectively, on Switchboard and CALLHOME. The performance was further improved when the WER of the training set was close to the WER of the evaluation dataset.