 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous bimodal attention fusion for speech emotion recognition
Mar 09, 2025Multi-modal emotion recognition in conversations is a challenging problem due to the complex and complementary interactions between different modalities. Audio and textual cues are particularly important for understanding emotions from a human perspective. Most existing studies focus on exploring interactions between audio and text modalities at the same representation level. However, a critical issue is often overlooked: the heterogeneous modality gap between low-level audio representations and high-level text representations. To address this problem, we propose a novel framework called Heterogeneous Bimodal Attention Fusion (HBAF) for multi-level multi-modal interaction in conversational emotion recognition. The proposed method comprises three key modules: the uni-modal representation module, the multi-modal fusion module, and the inter-modal contrastive learning module. The uni-modal representation module incorporates contextual content into low-level audio representations to bridge the heterogeneous multi-modal gap, enabling more effective fusion. The multi-modal fusion module uses dynamic bimodal attention and a dynamic gating mechanism to filter incorrect cross-modal relationships and fully exploit both intra-modal and inter-modal interactions. Finally, the inter-modal contrastive learning module captures complex absolute and relative interactions between audio and text modalities. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed HBAF method outperforms existing state-of-the-art baselines.
Bimodal Connection Attention Fusion for Speech Emotion Recognition
Mar 08, 2025Multi-modal emotion recognition is challenging due to the difficulty of extracting features that capture subtle emotional differences. Understanding multi-modal interactions and connections is key to building effective bimodal speech emotion recognition systems. In this work, we propose Bimodal Connection Attention Fusion (BCAF) method, which includes three main modules: the interactive connection network, the bimodal attention network, and the correlative attention network. The interactive connection network uses an encoder-decoder architecture to model modality connections between audio and text while leveraging modality-specific features. The bimodal attention network enhances semantic complementation and exploits intra- and inter-modal interactions. The correlative attention network reduces cross-modal noise and captures correlations between audio and text. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed BCAF method outperforms existing state-of-the-art baselines.
1st Place Solution to Odyssey Emotion Recognition Challenge Task1: Tackling Class Imbalance Problem
May 30, 2024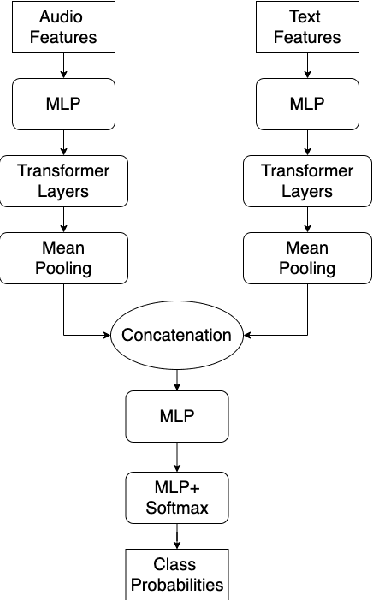



Speech emotion recognition is a challenging classification task with natural emotional speech, especially when the distribution of emotion types is imbalanced in the training and test data. In this case, it is more difficult for a model to learn to separate minority classes, resulting in those sometimes being ignored or frequently misclassified. Previous work has utilised class weighted loss for training, but problems remain as it sometimes causes over-fitting for minor classes or under-fitting for major classes. This paper presents the system developed by a multi-site team for the participation in the Odyssey 2024 Emotion Recognition Challenge Track-1. The challenge data has the aforementioned properties and therefore the presented systems aimed to tackle these issues, by introducing focal loss in optimisation when applying class weighted loss. Specifically, the focal loss is further weighted by prior-based class weights. Experimental results show that combining these two approaches brings better overall performance, by sacrificing performance on major classes. The system further employs a majority voting strategy to combine the outputs of an ensemble of 7 models. The models are trained independently, using different acoustic features and loss functions - with the aim to have different properties for different data. Hence these models show different performance preferences on major classes and minor classes. The ensemble system output obtained the best performance in the challenge, ranking top-1 among 68 submissions. It also outperformed all single models in our set. On the Odyssey 2024 Emotion Recognition Challenge Task-1 data the system obtained a Macro-F1 score of 35.69% and an accuracy of 37.32%.
cross-modal fusion techniques for utterance-level emotion recognition from text and speech
Feb 05, 2023



Multimodal emotion recognition (MER) is a fundamental complex research problem due to the uncertainty of human emotional expression and the heterogeneity gap between different modalities. Audio and text modalities are particularly important for a human participant in understanding emotions. Although many successful attempts have been designed multimodal representations for MER, there still exist multiple challenges to be addressed: 1) bridging the heterogeneity gap between multimodal features and model inter- and intra-modal interactions of multiple modalities; 2) effectively and efficiently modelling the contextual dynamics in the conversation sequence. In this paper, we propose Cross-Modal RoBERTa (CM-RoBERTa) model for emotion detection from spoken audio and corresponding transcripts. As the core unit of the CM-RoBERTa, parallel self- and cross- attention is designed to dynamically capture inter- and intra-modal interactions of audio and text. Specially, the mid-level fusion and residual module are employed to model long-term contextual dependencies and learn modality-specific patterns. We evaluate the approach on the MELD dataset and the experimental results show the proposed approach achieves the state-of-art performance on the dataset.
deep learning of segment-level feature representation for speech emotion recognition in conversations
Feb 05, 2023

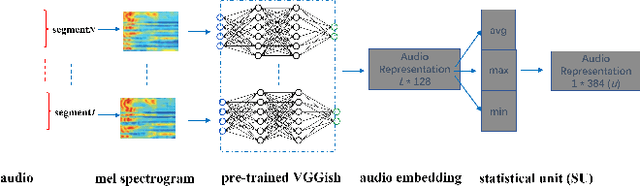

Accurately detecting emotions in conversation is a necessary yet challenging task due to the complexity of emotions and dynamics in dialogues. The emotional state of a speaker can be influenced by many different factors, such as interlocutor stimulus, dialogue scene, and topic. In this work, we propose a conversational speech emotion recognition method to deal with capturing attentive contextual dependency and speaker-sensitive interactions. First, we use a pretrained VGGish model to extract segment-based audio representation in individual utterances. Second, an attentive bi-directional gated recurrent unit (GRU) models contextual-sensitive information and explores intra- and inter-speaker dependencies jointly in a dynamic manner. The experiments conducted on the standard conversational dataset MELD demonstrate the effectiveness of the proposed method when compared against state-of the-art methods.