 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedeep learning of segment-level feature representation for speech emotion recognition in conversations
Paper and Code
Feb 05, 2023

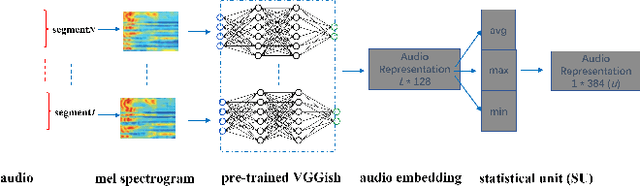

Accurately detecting emotions in conversation is a necessary yet challenging task due to the complexity of emotions and dynamics in dialogues. The emotional state of a speaker can be influenced by many different factors, such as interlocutor stimulus, dialogue scene, and topic. In this work, we propose a conversational speech emotion recognition method to deal with capturing attentive contextual dependency and speaker-sensitive interactions. First, we use a pretrained VGGish model to extract segment-based audio representation in individual utterances. Second, an attentive bi-directional gated recurrent unit (GRU) models contextual-sensitive information and explores intra- and inter-speaker dependencies jointly in a dynamic manner. The experiments conducted on the standard conversational dataset MELD demonstrate the effectiveness of the proposed method when compared against state-of the-art methods.