 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-theoretic Multimodal Representation Learning for Electrocardiogram Signals
May 26, 2026Electrocardiograms (ECGs) are widely used non-invasive measurements of cardiac activity and play a central role in clinical diagnosis. Recent multimodal approaches align ECG signals with clinical reports to incorporate diagnostic semantics, but clinical reports often fail to preserve the rich physiological structure of ECG waveforms, particularly across multiple levels of abstraction ranging from coarse diagnostic categories to fine-grained morphology. To address this limitation, we formulate ECG representation learning from an information-theoretic perspective and derive a tractable objective that jointly preserves signal structure and integrates clinical semantics. Based on this principle, we propose \textbf{MERIT} (Multimodal ECG Representation via Information Theory), a dual-branch pretraining framework combining masked ECG modeling with ECG--text contrastive alignment. Extensive experiments on PTB-XL and additional benchmarks demonstrate consistent improvements over prior methods, including gains exceeding $3%$ F1 on PTB-XL All and $5%$ F1 on SubClass classification. In zero-shot evaluation, MERIT further improves performance by up to $ +2.66\%$ AUC and $ +2.11\%$ F1 on PTB-XL SubClass, while also demonstrating robustness under multiple distribution-shift settings. Moreover, leveraging the learned ECG representations for ECG-conditioned clinical text generation with large language models improves text quality across several metrics, including ROUGE and METEOR. Together, these results demonstrate that MERIT learns more informative and clinically meaningful ECG representations, particularly for fine-grained clinical applications.
Spectrogram features for audio and speech analysis
Mar 16, 2026Spectrogram-based representations have grown to dominate the feature space for deep learning audio analysis systems, and are often adopted for speech analysis also. Initially, the primary motivator for spectrogram-based representations was their ability to present sound as a two dimensional signal in the time-frequency plane, which not only provides an interpretable physical basis for analysing sound, but also unlocks the use of a wide range of machine learning techniques such as convolutional neural networks, that had been developed for image processing. A spectrogram is a matrix characterised by the resolution and span of its two dimensions, as well as by the representation and scaling of each element. Many possibilities for these three characteristics have been explored by researchers across numerous application areas, with different settings showing affinity for various tasks. This paper reviews the use of spectrogram-based representations and surveys the state-of-the-art to question how front-end feature representation choice allies with back-end classifier architecture for different tasks.
* 30 pages
EcoSpa: Efficient Transformer Training with Coupled Sparsity
Nov 09, 2025Transformers have become the backbone of modern AI, yet their high computational demands pose critical system challenges. While sparse training offers efficiency gains, existing methods fail to preserve critical structural relationships between weight matrices that interact multiplicatively in attention and feed-forward layers. This oversight leads to performance degradation at high sparsity levels. We introduce EcoSpa, an efficient structured sparse training method that jointly evaluates and sparsifies coupled weight matrix pairs, preserving their interaction patterns through aligned row/column removal. EcoSpa introduces a new granularity for calibrating structural component importance and performs coupled estimation and sparsification across both pre-training and fine-tuning scenarios. Evaluations demonstrate substantial improvements: EcoSpa enables efficient training of LLaMA-1B with 50\% memory reduction and 21\% faster training, achieves $2.2\times$ model compression on GPT-2-Medium with $2.4$ lower perplexity, and delivers $1.6\times$ inference speedup. The approach uses standard PyTorch operations, requiring no custom hardware or kernels, making efficient transformer training accessible on commodity hardware.
From Aesthetics to Human Preferences: Comparative Perspectives of Evaluating Text-to-Music Systems
Apr 30, 2025Evaluating generative models remains a fundamental challenge, particularly when the goal is to reflect human preferences. In this paper, we use music generation as a case study to investigate the gap between automatic evaluation metrics and human preferences. We conduct comparative experiments across five state-of-the-art music generation approaches, assessing both perceptual quality and distributional similarity to human-composed music. Specifically, we evaluate synthesis music from various perceptual dimensions and examine reference-based metrics such as Mauve Audio Divergence (MAD) and Kernel Audio Distance (KAD). Our findings reveal significant inconsistencies across the different metrics, highlighting the limitation of the current evaluation practice. To support further research, we release a benchmark dataset comprising samples from multiple models. This study provides a broader perspective on the alignment of human preference in generative modeling, advocating for more human-centered evaluation strategies across domains.
Heterogeneous bimodal attention fusion for speech emotion recognition
Mar 09, 2025Multi-modal emotion recognition in conversations is a challenging problem due to the complex and complementary interactions between different modalities. Audio and textual cues are particularly important for understanding emotions from a human perspective. Most existing studies focus on exploring interactions between audio and text modalities at the same representation level. However, a critical issue is often overlooked: the heterogeneous modality gap between low-level audio representations and high-level text representations. To address this problem, we propose a novel framework called Heterogeneous Bimodal Attention Fusion (HBAF) for multi-level multi-modal interaction in conversational emotion recognition. The proposed method comprises three key modules: the uni-modal representation module, the multi-modal fusion module, and the inter-modal contrastive learning module. The uni-modal representation module incorporates contextual content into low-level audio representations to bridge the heterogeneous multi-modal gap, enabling more effective fusion. The multi-modal fusion module uses dynamic bimodal attention and a dynamic gating mechanism to filter incorrect cross-modal relationships and fully exploit both intra-modal and inter-modal interactions. Finally, the inter-modal contrastive learning module captures complex absolute and relative interactions between audio and text modalities. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed HBAF method outperforms existing state-of-the-art baselines.
Bimodal Connection Attention Fusion for Speech Emotion Recognition
Mar 08, 2025Multi-modal emotion recognition is challenging due to the difficulty of extracting features that capture subtle emotional differences. Understanding multi-modal interactions and connections is key to building effective bimodal speech emotion recognition systems. In this work, we propose Bimodal Connection Attention Fusion (BCAF) method, which includes three main modules: the interactive connection network, the bimodal attention network, and the correlative attention network. The interactive connection network uses an encoder-decoder architecture to model modality connections between audio and text while leveraging modality-specific features. The bimodal attention network enhances semantic complementation and exploits intra- and inter-modal interactions. The correlative attention network reduces cross-modal noise and captures correlations between audio and text. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed BCAF method outperforms existing state-of-the-art baselines.
LHGNN: Local-Higher Order Graph Neural Networks For Audio Classification and Tagging
Jan 07, 2025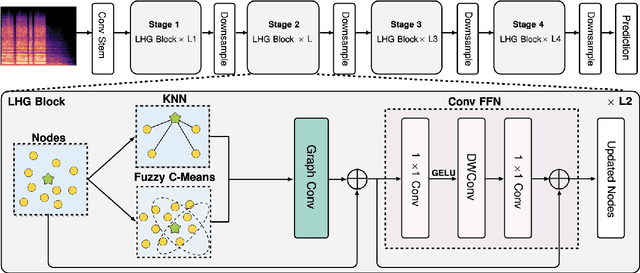



Transformers have set new benchmarks in audio processing tasks, leveraging self-attention mechanisms to capture complex patterns and dependencies within audio data. However, their focus on pairwise interactions limits their ability to process the higher-order relations essential for identifying distinct audio objects. To address this limitation, this work introduces the Local- Higher Order Graph Neural Network (LHGNN), a graph based model that enhances feature understanding by integrating local neighbourhood information with higher-order data from Fuzzy C-Means clusters, thereby capturing a broader spectrum of audio relationships. Evaluation of the model on three publicly available audio datasets shows that it outperforms Transformer-based models across all benchmarks while operating with substantially fewer parameters. Moreover, LHGNN demonstrates a distinct advantage in scenarios lacking ImageNet pretraining, establishing its effectiveness and efficiency in environments where extensive pretraining data is unavailable.
AADNet: An End-to-End Deep Learning Model for Auditory Attention Decoding
Oct 16, 2024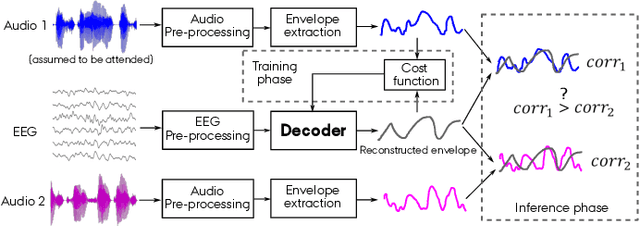
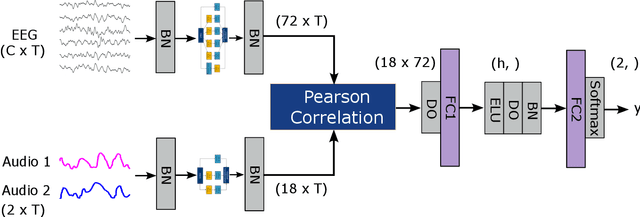
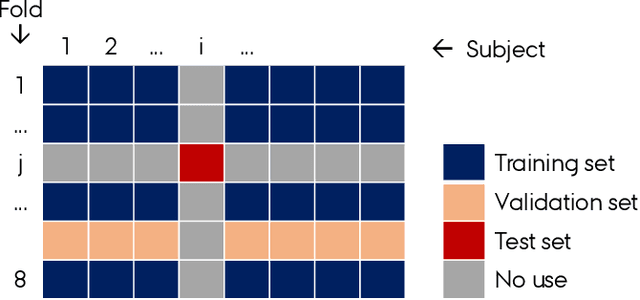
Auditory attention decoding (AAD) is the process of identifying the attended speech in a multi-talker environment using brain signals, typically recorded through electroencephalography (EEG). Over the past decade, AAD has undergone continuous development, driven by its promising application in neuro-steered hearing devices. Most AAD algorithms are relying on the increase in neural entrainment to the envelope of attended speech, as compared to unattended speech, typically using a two-step approach. First, the algorithm predicts representations of the attended speech signal envelopes; second, it identifies the attended speech by finding the highest correlation between the predictions and the representations of the actual speech signals. In this study, we proposed a novel end-to-end neural network architecture, named AADNet, which combines these two stages into a direct approach to address the AAD problem. We compare the proposed network against the traditional approaches, including linear stimulus reconstruction, canonical correlation analysis, and an alternative non-linear stimulus reconstruction using two different datasets. AADNet shows a significant performance improvement for both subject-specific and subject-independent models. Notably, the average subject-independent classification accuracies from 56.1 % to 82.7 % with analysis window lengths ranging from 1 to 40 seconds, respectively, show a significantly improved ability to generalize to data from unseen subjects. These results highlight the potential of deep learning models for advancing AAD, with promising implications for future hearing aids, assistive devices, and clinical assessments.
MixNet: Joining Force of Classical and Modern Approaches Toward the Comprehensive Pipeline in Motor Imagery EEG Classification
Sep 06, 2024



Recent advances in deep learning (DL) have significantly impacted motor imagery (MI)-based brain-computer interface (BCI) systems, enhancing the decoding of electroencephalography (EEG) signals. However, most studies struggle to identify discriminative patterns across subjects during MI tasks, limiting MI classification performance. In this article, we propose MixNet, a novel classification framework designed to overcome this limitation by utilizing spectral-spatial signals from MI data, along with a multitask learning architecture named MIN2Net, for classification. Here, the spectral-spatial signals are generated using the filter-bank common spatial patterns (FBCSPs) method on MI data. Since the multitask learning architecture is used for the classification task, the learning in each task may exhibit different generalization rates and potential overfitting across tasks. To address this issue, we implement adaptive gradient blending, simultaneously regulating multiple loss weights and adjusting the learning pace for each task based on its generalization/overfitting tendencies. Experimental results on six benchmark data sets of different data sizes demonstrate that MixNet consistently outperforms all state-of-the-art algorithms in subject-dependent and -independent settings. Finally, the low-density EEG MI classification results show that MixNet outperforms all state-of-the-art algorithms, offering promising implications for Internet of Thing (IoT) applications, such as lightweight and portable EEG wearable devices based on low-density montages.
* Supplementary materials and source codes are available on-line at https://github.com/Max-Phairot-A/MixNet
Data-Centric Human Preference Optimization with Rationales
Jul 19, 2024



Reinforcement learning from human feedback plays a crucial role in aligning language models towards human preferences, traditionally represented through comparisons between pairs or sets of responses within a given context. While many studies have enhanced algorithmic techniques to optimize learning from such data, this work shifts focus to improving preference learning through a data-centric approach. Specifically, we propose enriching existing preference datasets with machine-generated rationales that explain the reasons behind choices. We develop a simple and principled framework to augment current preference learning methods with rationale information. Our comprehensive analysis highlights how rationales enhance learning efficiency. Extensive experiments reveal that rationale-enriched preference learning offers multiple advantages: it improves data efficiency, accelerates convergence to higher-performing models, and reduces verbosity bias and hallucination. Furthermore, this framework is versatile enough to integrate with various preference optimization algorithms. Overall, our findings highlight the potential of re-imagining data design for preference learning, demonstrating that even freely available machine-generated rationales can significantly boost performance across multiple dimensions. The code repository is available at https: //github.com/reds-lab/preference-learning-with-rationales