 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than the Final Answer: Improving Visual Extraction and Logical Consistency in Vision-Language Models
Dec 13, 2025Reinforcement learning from verifiable rewards (RLVR) has recently been extended from text-only LLMs to vision-language models (VLMs) to elicit long-chain multimodal reasoning. However, RLVR-trained VLMs still exhibit two persistent failure modes: inaccurate visual extraction (missing or hallucinating details) and logically inconsistent chains-of-thought, largely because verifiable signals supervise only the final answer. We propose PeRL-VL (Perception and Reasoning Learning for Vision-Language Models), a decoupled framework that separately improves visual perception and textual reasoning on top of RLVR. For perception, PeRL-VL introduces a VLM-based description reward that scores the model's self-generated image descriptions for faithfulness and sufficiency. For reasoning, PeRL-VL adds a text-only Reasoning SFT stage on logic-rich chain-of-thought data, enhancing coherence and logical consistency independently of vision. Across diverse multimodal benchmarks, PeRL-VL improves average Pass@1 accuracy from 63.3% (base Qwen2.5-VL-7B) to 68.8%, outperforming standard RLVR, text-only reasoning SFT, and naive multimodal distillation from GPT-4o.
Optimizing Product Provenance Verification using Data Valuation Methods
Feb 21, 2025Determining and verifying product provenance remains a critical challenge in global supply chains, particularly as geopolitical conflicts and shifting borders create new incentives for misrepresentation of commodities, such as hiding the origin of illegally harvested timber or stolen agricultural products. Stable Isotope Ratio Analysis (SIRA), combined with Gaussian process regression-based isoscapes, has emerged as a powerful tool for geographic origin verification. However, the effectiveness of these models is often constrained by data scarcity and suboptimal dataset selection. In this work, we introduce a novel data valuation framework designed to enhance the selection and utilization of training data for machine learning models applied in SIRA. By prioritizing high-informative samples, our approach improves model robustness and predictive accuracy across diverse datasets and geographies. We validate our methodology with extensive experiments, demonstrating its potential to significantly enhance provenance verification, mitigate fraudulent trade practices, and strengthen regulatory enforcement of global supply chains.
DiPT: Enhancing LLM reasoning through diversified perspective-taking
Sep 10, 2024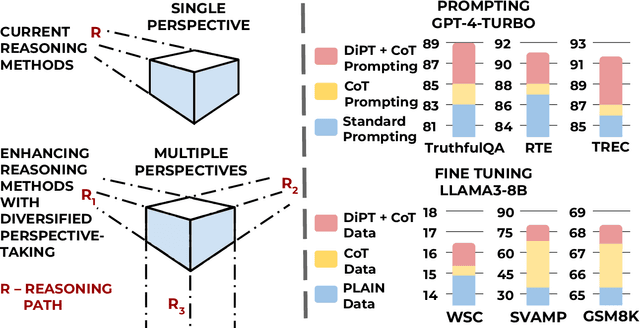
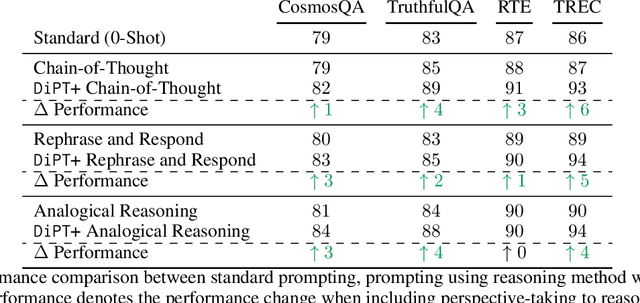

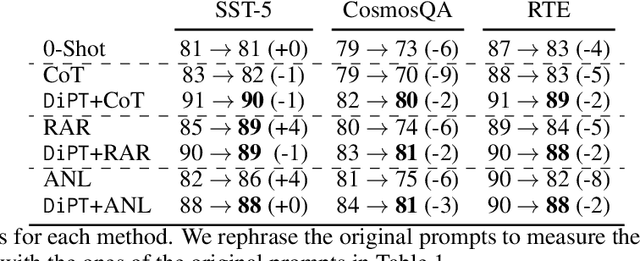
Existing work on improving language model reasoning typically explores a single solution path, which can be prone to errors. Inspired by perspective-taking in social studies, this paper introduces DiPT, a novel approach that complements current reasoning methods by explicitly incorporating diversified viewpoints. This approach allows the model to gain a deeper understanding of the problem's context and identify the most effective solution path during the inference stage. Additionally, it provides a general data-centric AI recipe for augmenting existing data to improve their quality for fine-tuning. Our empirical results demonstrate that DiPT can be flexibly integrated into existing methods that focus on a single reasoning approach, enhancing their reasoning performance and stability when presented with paraphrased problems. Furthermore, we illustrate improved context understanding by maintaining the model's safe outputs against "jailbreaking" prompts intentionally designed to bypass safeguards built into deployed models. Lastly, we show that fine-tuning with data enriched with diverse perspectives can boost the reasoning capabilities of the model compared to fine-tuning with raw data alone.
Data-Centric Human Preference Optimization with Rationales
Jul 19, 2024



Reinforcement learning from human feedback plays a crucial role in aligning language models towards human preferences, traditionally represented through comparisons between pairs or sets of responses within a given context. While many studies have enhanced algorithmic techniques to optimize learning from such data, this work shifts focus to improving preference learning through a data-centric approach. Specifically, we propose enriching existing preference datasets with machine-generated rationales that explain the reasons behind choices. We develop a simple and principled framework to augment current preference learning methods with rationale information. Our comprehensive analysis highlights how rationales enhance learning efficiency. Extensive experiments reveal that rationale-enriched preference learning offers multiple advantages: it improves data efficiency, accelerates convergence to higher-performing models, and reduces verbosity bias and hallucination. Furthermore, this framework is versatile enough to integrate with various preference optimization algorithms. Overall, our findings highlight the potential of re-imagining data design for preference learning, demonstrating that even freely available machine-generated rationales can significantly boost performance across multiple dimensions. The code repository is available at https: //github.com/reds-lab/preference-learning-with-rationales
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
May 05, 2024



This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
Performance Scaling via Optimal Transport: Enabling Data Selection from Partially Revealed Sources
Jul 05, 2023



Traditionally, data selection has been studied in settings where all samples from prospective sources are fully revealed to a machine learning developer. However, in practical data exchange scenarios, data providers often reveal only a limited subset of samples before an acquisition decision is made. Recently, there have been efforts to fit scaling laws that predict model performance at any size and data source composition using the limited available samples. However, these scaling functions are black-box, computationally expensive to fit, highly susceptible to overfitting, or/and difficult to optimize for data selection. This paper proposes a framework called <projektor>, which predicts model performance and supports data selection decisions based on partial samples of prospective data sources. Our approach distinguishes itself from existing work by introducing a novel *two-stage* performance inference process. In the first stage, we leverage the Optimal Transport distance to predict the model's performance for any data mixture ratio within the range of disclosed data sizes. In the second stage, we extrapolate the performance to larger undisclosed data sizes based on a novel parameter-free mapping technique inspired by neural scaling laws. We further derive an efficient gradient-based method to select data sources based on the projected model performance. Evaluation over a diverse range of applications demonstrates that <projektor> significantly improves existing performance scaling approaches in terms of both the accuracy of performance inference and the computation costs associated with constructing the performance predictor. Also, <projektor> outperforms by a wide margin in data selection effectiveness compared to a range of other off-the-shelf solutions.
2D-Shapley: A Framework for Fragmented Data Valuation
Jun 18, 2023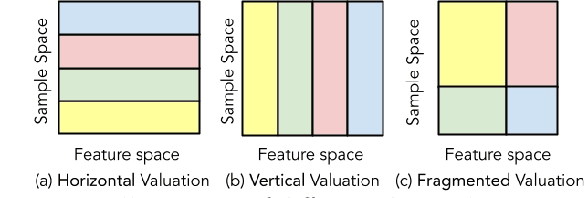

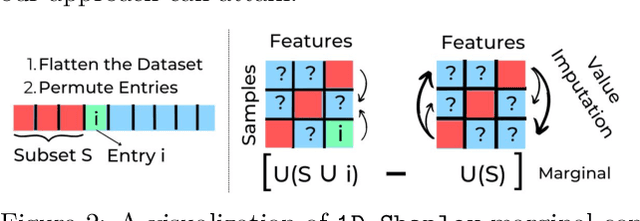
Data valuation -- quantifying the contribution of individual data sources to certain predictive behaviors of a model -- is of great importance to enhancing the transparency of machine learning and designing incentive systems for data sharing. Existing work has focused on evaluating data sources with the shared feature or sample space. How to valuate fragmented data sources of which each only contains partial features and samples remains an open question. We start by presenting a method to calculate the counterfactual of removing a fragment from the aggregated data matrix. Based on the counterfactual calculation, we further propose 2D-Shapley, a theoretical framework for fragmented data valuation that uniquely satisfies some appealing axioms in the fragmented data context. 2D-Shapley empowers a range of new use cases, such as selecting useful data fragments, providing interpretation for sample-wise data values, and fine-grained data issue diagnosis.
LAVA: Data Valuation without Pre-Specified Learning Algorithms
Apr 28, 2023



Traditionally, data valuation is posed as a problem of equitably splitting the validation performance of a learning algorithm among the training data. As a result, the calculated data values depend on many design choices of the underlying learning algorithm. However, this dependence is undesirable for many use cases of data valuation, such as setting priorities over different data sources in a data acquisition process and informing pricing mechanisms in a data marketplace. In these scenarios, data needs to be valued before the actual analysis and the choice of the learning algorithm is still undetermined then. Another side-effect of the dependence is that to assess the value of individual points, one needs to re-run the learning algorithm with and without a point, which incurs a large computation burden. This work leapfrogs over the current limits of data valuation methods by introducing a new framework that can value training data in a way that is oblivious to the downstream learning algorithm. (1) We develop a proxy for the validation performance associated with a training set based on a non-conventional class-wise Wasserstein distance between the training and the validation set. We show that the distance characterizes the upper bound of the validation performance for any given model under certain Lipschitz conditions. (2) We develop a novel method to value individual data based on the sensitivity analysis of the class-wise Wasserstein distance. Importantly, these values can be directly obtained for free from the output of off-the-shelf optimization solvers when computing the distance. (3) We evaluate our new data valuation framework over various use cases related to detecting low-quality data and show that, surprisingly, the learning-agnostic feature of our framework enables a significant improvement over the state-of-the-art performance while being orders of magnitude faster.
Narcissus: A Practical Clean-Label Backdoor Attack with Limited Information
Apr 15, 2022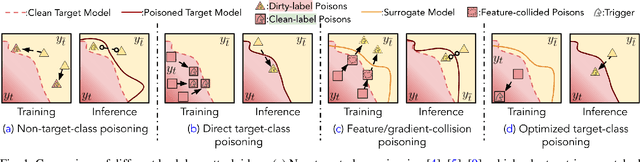



Backdoor attacks insert malicious data into a training set so that, during inference time, it misclassifies inputs that have been patched with a backdoor trigger as the malware specified label. For backdoor attacks to bypass human inspection, it is essential that the injected data appear to be correctly labeled. The attacks with such property are often referred to as "clean-label attacks." Existing clean-label backdoor attacks require knowledge of the entire training set to be effective. Obtaining such knowledge is difficult or impossible because training data are often gathered from multiple sources (e.g., face images from different users). It remains a question whether backdoor attacks still present a real threat. This paper provides an affirmative answer to this question by designing an algorithm to mount clean-label backdoor attacks based only on the knowledge of representative examples from the target class. With poisoning equal to or less than 0.5% of the target-class data and 0.05% of the training set, we can train a model to classify test examples from arbitrary classes into the target class when the examples are patched with a backdoor trigger. Our attack works well across datasets and models, even when the trigger presents in the physical world. We explore the space of defenses and find that, surprisingly, our attack can evade the latest state-of-the-art defenses in their vanilla form, or after a simple twist, we can adapt to the downstream defenses. We study the cause of the intriguing effectiveness and find that because the trigger synthesized by our attack contains features as persistent as the original semantic features of the target class, any attempt to remove such triggers would inevitably hurt the model accuracy first.
Label-Only Model Inversion Attacks via Boundary Repulsion
Mar 03, 2022

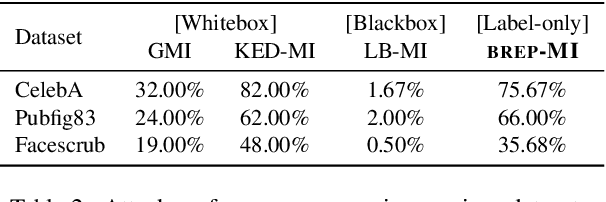
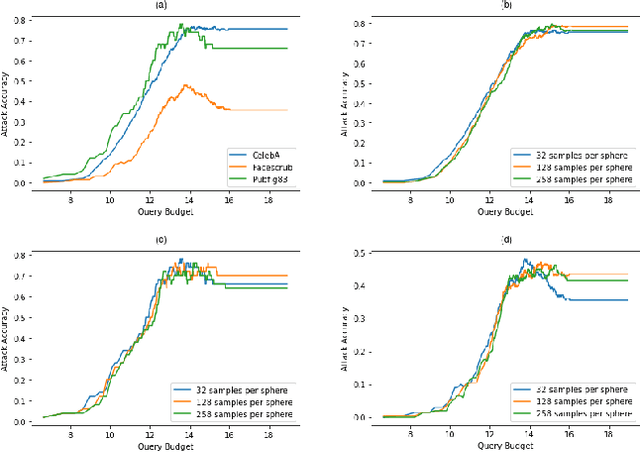
Recent studies show that the state-of-the-art deep neural networks are vulnerable to model inversion attacks, in which access to a model is abused to reconstruct private training data of any given target class. Existing attacks rely on having access to either the complete target model (whitebox) or the model's soft-labels (blackbox). However, no prior work has been done in the harder but more practical scenario, in which the attacker only has access to the model's predicted label, without a confidence measure. In this paper, we introduce an algorithm, Boundary-Repelling Model Inversion (BREP-MI), to invert private training data using only the target model's predicted labels. The key idea of our algorithm is to evaluate the model's predicted labels over a sphere and then estimate the direction to reach the target class's centroid. Using the example of face recognition, we show that the images reconstructed by BREP-MI successfully reproduce the semantics of the private training data for various datasets and target model architectures. We compare BREP-MI with the state-of-the-art whitebox and blackbox model inversion attacks and the results show that despite assuming less knowledge about the target model, BREP-MI outperforms the blackbox attack and achieves comparable results to the whitebox attack.