 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Weak Cues to Real Identities: Evaluating Inference-Driven De-Anonymization in LLM Agents
Mar 19, 2026Anonymization is widely treated as a practical safeguard because re-identifying anonymous records was historically costly, requiring domain expertise, tailored algorithms, and manual corroboration. We study a growing privacy risk that may weaken this barrier: LLM-based agents can autonomously reconstruct real-world identities from scattered, individually non-identifying cues. By combining these sparse cues with public information, agents resolve identities without bespoke engineering. We formalize this threat as \emph{inference-driven linkage} and systematically evaluate it across three settings: classical linkage scenarios (Netflix and AOL), \emph{InferLink} (a controlled benchmark varying task intent, shared cues, and attacker knowledge), and modern text-rich artifacts. Without task-specific heuristics, agents successfully execute both fixed-pool matching and open-ended identity resolution. In the Netflix Prize setting, an agent reconstructs 79.2\% of identities, significantly outperforming a 56.0\% classical baseline. Furthermore, linkage emerges not only under explicit adversarial prompts but also as a byproduct of benign cross-source analysis in \emph{InferLink} and unstructured research narratives. These findings establish that identity inference -- not merely explicit information disclosure -- must be treated as a first-class privacy risk; evaluations must measure what identities an agent can infer.
Boosting Alignment for Post-Unlearning Text-to-Image Generative Models
Dec 09, 2024

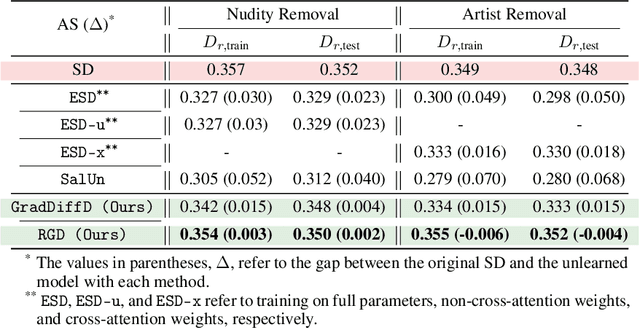

Large-scale generative models have shown impressive image-generation capabilities, propelled by massive data. However, this often inadvertently leads to the generation of harmful or inappropriate content and raises copyright concerns. Driven by these concerns, machine unlearning has become crucial to effectively purge undesirable knowledge from models. While existing literature has studied various unlearning techniques, these often suffer from either poor unlearning quality or degradation in text-image alignment after unlearning, due to the competitive nature of these objectives. To address these challenges, we propose a framework that seeks an optimal model update at each unlearning iteration, ensuring monotonic improvement on both objectives. We further derive the characterization of such an update. In addition, we design procedures to strategically diversify the unlearning and remaining datasets to boost performance improvement. Our evaluation demonstrates that our method effectively removes target classes from recent diffusion-based generative models and concepts from stable diffusion models while maintaining close alignment with the models' original trained states, thus outperforming state-of-the-art baselines. Our code will be made available at \url{https://github.com/reds-lab/Restricted_gradient_diversity_unlearning.git}.
The Mirrored Influence Hypothesis: Efficient Data Influence Estimation by Harnessing Forward Passes
Feb 14, 2024

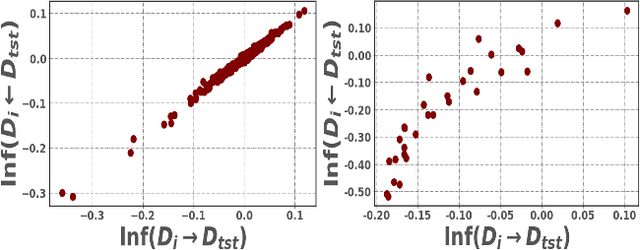

Large-scale black-box models have become ubiquitous across numerous applications. Understanding the influence of individual training data sources on predictions made by these models is crucial for improving their trustworthiness. Current influence estimation techniques involve computing gradients for every training point or repeated training on different subsets. These approaches face obvious computational challenges when scaled up to large datasets and models. In this paper, we introduce and explore the Mirrored Influence Hypothesis, highlighting a reciprocal nature of influence between training and test data. Specifically, it suggests that evaluating the influence of training data on test predictions can be reformulated as an equivalent, yet inverse problem: assessing how the predictions for training samples would be altered if the model were trained on specific test samples. Through both empirical and theoretical validations, we demonstrate the wide applicability of our hypothesis. Inspired by this, we introduce a new method for estimating the influence of training data, which requires calculating gradients for specific test samples, paired with a forward pass for each training point. This approach can capitalize on the common asymmetry in scenarios where the number of test samples under concurrent examination is much smaller than the scale of the training dataset, thus gaining a significant improvement in efficiency compared to existing approaches. We demonstrate the applicability of our method across a range of scenarios, including data attribution in diffusion models, data leakage detection, analysis of memorization, mislabeled data detection, and tracing behavior in language models. Our code will be made available at https://github.com/ruoxi-jia-group/Forward-INF.
Practical Membership Inference Attacks Against Large-Scale Multi-Modal Models: A Pilot Study
Sep 29, 2023Membership inference attacks (MIAs) aim to infer whether a data point has been used to train a machine learning model. These attacks can be employed to identify potential privacy vulnerabilities and detect unauthorized use of personal data. While MIAs have been traditionally studied for simple classification models, recent advancements in multi-modal pre-training, such as CLIP, have demonstrated remarkable zero-shot performance across a range of computer vision tasks. However, the sheer scale of data and models presents significant computational challenges for performing the attacks. This paper takes a first step towards developing practical MIAs against large-scale multi-modal models. We introduce a simple baseline strategy by thresholding the cosine similarity between text and image features of a target point and propose further enhancing the baseline by aggregating cosine similarity across transformations of the target. We also present a new weakly supervised attack method that leverages ground-truth non-members (e.g., obtained by using the publication date of a target model and the timestamps of the open data) to further enhance the attack. Our evaluation shows that CLIP models are susceptible to our attack strategies, with our simple baseline achieving over $75\%$ membership identification accuracy. Furthermore, our enhanced attacks outperform the baseline across multiple models and datasets, with the weakly supervised attack demonstrating an average-case performance improvement of $17\%$ and being at least $7$X more effective at low false-positive rates. These findings highlight the importance of protecting the privacy of multi-modal foundational models, which were previously assumed to be less susceptible to MIAs due to less overfitting. Our code is available at https://github.com/ruoxi-jia-group/CLIP-MIA.
LAVA: Data Valuation without Pre-Specified Learning Algorithms
Apr 28, 2023



Traditionally, data valuation is posed as a problem of equitably splitting the validation performance of a learning algorithm among the training data. As a result, the calculated data values depend on many design choices of the underlying learning algorithm. However, this dependence is undesirable for many use cases of data valuation, such as setting priorities over different data sources in a data acquisition process and informing pricing mechanisms in a data marketplace. In these scenarios, data needs to be valued before the actual analysis and the choice of the learning algorithm is still undetermined then. Another side-effect of the dependence is that to assess the value of individual points, one needs to re-run the learning algorithm with and without a point, which incurs a large computation burden. This work leapfrogs over the current limits of data valuation methods by introducing a new framework that can value training data in a way that is oblivious to the downstream learning algorithm. (1) We develop a proxy for the validation performance associated with a training set based on a non-conventional class-wise Wasserstein distance between the training and the validation set. We show that the distance characterizes the upper bound of the validation performance for any given model under certain Lipschitz conditions. (2) We develop a novel method to value individual data based on the sensitivity analysis of the class-wise Wasserstein distance. Importantly, these values can be directly obtained for free from the output of off-the-shelf optimization solvers when computing the distance. (3) We evaluate our new data valuation framework over various use cases related to detecting low-quality data and show that, surprisingly, the learning-agnostic feature of our framework enables a significant improvement over the state-of-the-art performance while being orders of magnitude faster.