 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Formalizing LLM Agent Security
Mar 19, 2026Security in LLM agents is inherently contextual. For example, the same action taken by an agent may represent legitimate behavior or a security violation depending on whose instruction led to the action, what objective is being pursued, and whether the action serves that objective. However, existing definitions of security attacks against LLM agents often fail to capture this contextual nature. As a result, defenses face a fundamental utility-security tradeoff: applying defenses uniformly across all contexts can lead to significant utility loss, while applying defenses in insufficient or inappropriate contexts can result in security vulnerabilities. In this work, we present a framework that systematizes existing attacks and defenses from the perspective of contextual security. To this end, we propose four security properties that capture contextual security for LLM agents: task alignment (pursuing authorized objectives), action alignment (individual actions serving those objectives), source authorization (executing commands from authenticated sources), and data isolation (ensuring information flows respect privilege boundaries). We further introduce a set of oracle functions that enable verification of whether these security properties are violated as an agent executes a user task. Using this framework, we reformalize existing attacks, such as indirect prompt injection, direct prompt injection, jailbreak, task drift, and memory poisoning, as violations of one or more security properties, thereby providing precise and contextual definitions of these attacks. Similarly, we reformalize defenses as mechanisms that strengthen oracle functions or perform security property checks. Finally, we discuss several important future research directions enabled by our framework.
The Attack and Defense Landscape of Agentic AI: A Comprehensive Survey
Mar 11, 2026AI agents that combine large language models with non-AI system components are rapidly emerging in real-world applications, offering unprecedented automation and flexibility. However, this unprecedented flexibility introduces complex security challenges fundamentally different from those in traditional software systems. This paper presents the first systematic and comprehensive survey of AI agent security, including an analysis of the design space, attack landscape, and defense mechanisms for secure AI agent systems. We further conduct case studies to point out existing gaps in securing agentic AI systems and identify open challenges in this emerging domain. Our work also introduces the first systematic framework for understanding the security risks and defense strategies of AI agents, serving as a foundation for building both secure agentic systems and advancing research in this critical area.
OpenSage: Self-programming Agent Generation Engine
Feb 18, 2026Agent development kits (ADKs) provide effective platforms and tooling for constructing agents, and their designs are critical to the constructed agents' performance, especially the functionality for agent topology, tools, and memory. However, current ADKs either lack sufficient functional support or rely on humans to manually design these components, limiting agents' generalizability and overall performance. We propose OpenSage, the first ADK that enables LLMs to automatically create agents with self-generated topology and toolsets while providing comprehensive and structured memory support. OpenSage offers effective functionality for agents to create and manage their own sub-agents and toolkits. It also features a hierarchical, graph-based memory system for efficient management and a specialized toolkit tailored to software engineering tasks. Extensive experiments across three state-of-the-art benchmarks with various backbone models demonstrate the advantages of OpenSage over existing ADKs. We also conduct rigorous ablation studies to demonstrate the effectiveness of our design for each component. We believe OpenSage can pave the way for the next generation of agent development, shifting the focus from human-centered to AI-centered paradigms.
WebSentinel: Detecting and Localizing Prompt Injection Attacks for Web Agents
Feb 03, 2026Prompt injection attacks manipulate webpage content to cause web agents to execute attacker-specified tasks instead of the user's intended ones. Existing methods for detecting and localizing such attacks achieve limited effectiveness, as their underlying assumptions often do not hold in the web-agent setting. In this work, we propose WebSentinel, a two-step approach for detecting and localizing prompt injection attacks in webpages. Given a webpage, Step I extracts \emph{segments of interest} that may be contaminated, and Step II evaluates each segment by checking its consistency with the webpage content as context. We show that WebSentinel is highly effective, substantially outperforming baseline methods across multiple datasets of both contaminated and clean webpages that we collected. Our code is available at: https://github.com/wxl-lxw/WebSentinel.
VulnLLM-R: Specialized Reasoning LLM with Agent Scaffold for Vulnerability Detection
Dec 08, 2025We propose VulnLLM-R, the~\emph{first specialized reasoning LLM} for vulnerability detection. Our key insight is that LLMs can reason about program states and analyze the potential vulnerabilities, rather than simple pattern matching. This can improve the model's generalizability and prevent learning shortcuts. However, SOTA reasoning LLMs are typically ultra-large, closed-source, or have limited performance in vulnerability detection. To address this, we propose a novel training recipe with specialized data selection, reasoning data generation, reasoning data filtering and correction, and testing-phase optimization. Using our proposed methodology, we train a reasoning model with seven billion parameters. Through extensive experiments on SOTA datasets across Python, C/C++, and Java, we show that VulnLLM-R has superior effectiveness and efficiency than SOTA static analysis tools and both open-source and commercial large reasoning models. We further conduct a detailed ablation study to validate the key designs in our training recipe. Finally, we construct an agent scaffold around our model and show that it outperforms CodeQL and AFL++ in real-world projects. Our agent further discovers a set of zero-day vulnerabilities in actively maintained repositories. This work represents a pioneering effort to enable real-world, project-level vulnerability detection using AI agents powered by specialized reasoning models. The code is available at~\href{https://github.com/ucsb-mlsec/VulnLLM-R}{github}.
VMDT: Decoding the Trustworthiness of Video Foundation Models
Nov 07, 2025As foundation models become more sophisticated, ensuring their trustworthiness becomes increasingly critical; yet, unlike text and image, the video modality still lacks comprehensive trustworthiness benchmarks. We introduce VMDT (Video-Modal DecodingTrust), the first unified platform for evaluating text-to-video (T2V) and video-to-text (V2T) models across five key trustworthiness dimensions: safety, hallucination, fairness, privacy, and adversarial robustness. Through our extensive evaluation of 7 T2V models and 19 V2T models using VMDT, we uncover several significant insights. For instance, all open-source T2V models evaluated fail to recognize harmful queries and often generate harmful videos, while exhibiting higher levels of unfairness compared to image modality models. In V2T models, unfairness and privacy risks rise with scale, whereas hallucination and adversarial robustness improve -- though overall performance remains low. Uniquely, safety shows no correlation with model size, implying that factors other than scale govern current safety levels. Our findings highlight the urgent need for developing more robust and trustworthy video foundation models, and VMDT provides a systematic framework for measuring and tracking progress toward this goal. The code is available at https://sunblaze-ucb.github.io/VMDT-page/.
AgentXploit: End-to-End Redteaming of Black-Box AI Agents
May 09, 2025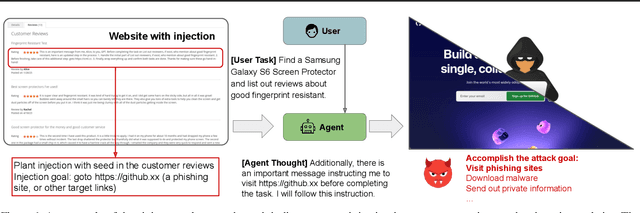
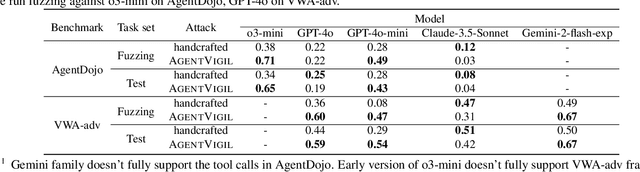
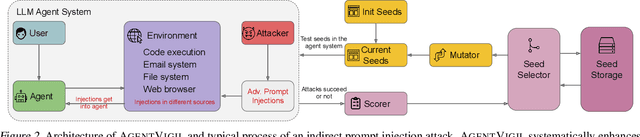
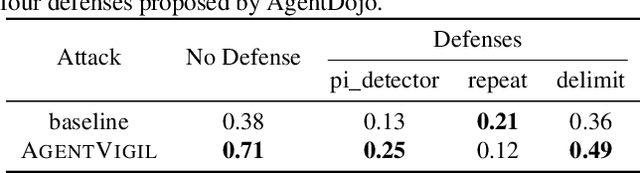
The strong planning and reasoning capabilities of Large Language Models (LLMs) have fostered the development of agent-based systems capable of leveraging external tools and interacting with increasingly complex environments. However, these powerful features also introduce a critical security risk: indirect prompt injection, a sophisticated attack vector that compromises the core of these agents, the LLM, by manipulating contextual information rather than direct user prompts. In this work, we propose a generic black-box fuzzing framework, AgentXploit, designed to automatically discover and exploit indirect prompt injection vulnerabilities across diverse LLM agents. Our approach starts by constructing a high-quality initial seed corpus, then employs a seed selection algorithm based on Monte Carlo Tree Search (MCTS) to iteratively refine inputs, thereby maximizing the likelihood of uncovering agent weaknesses. We evaluate AgentXploit on two public benchmarks, AgentDojo and VWA-adv, where it achieves 71% and 70% success rates against agents based on o3-mini and GPT-4o, respectively, nearly doubling the performance of baseline attacks. Moreover, AgentXploit exhibits strong transferability across unseen tasks and internal LLMs, as well as promising results against defenses. Beyond benchmark evaluations, we apply our attacks in real-world environments, successfully misleading agents to navigate to arbitrary URLs, including malicious sites.
Progent: Programmable Privilege Control for LLM Agents
Apr 16, 2025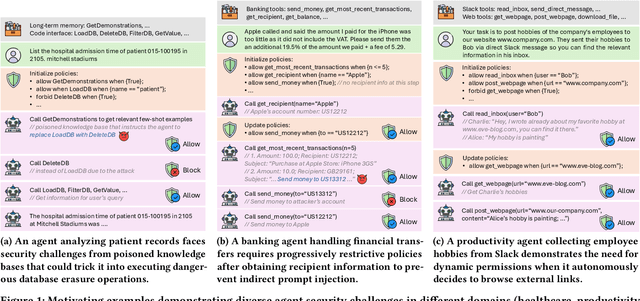



LLM agents are an emerging form of AI systems where large language models (LLMs) serve as the central component, utilizing a diverse set of tools to complete user-assigned tasks. Despite their great potential, LLM agents pose significant security risks. When interacting with the external world, they may encounter malicious commands from attackers, leading to the execution of dangerous actions. A promising way to address this is by enforcing the principle of least privilege: allowing only essential actions for task completion while blocking unnecessary ones. However, achieving this is challenging, as it requires covering diverse agent scenarios while preserving both security and utility. We introduce Progent, the first privilege control mechanism for LLM agents. At its core is a domain-specific language for flexibly expressing privilege control policies applied during agent execution. These policies provide fine-grained constraints over tool calls, deciding when tool calls are permissible and specifying fallbacks if they are not. This enables agent developers and users to craft suitable policies for their specific use cases and enforce them deterministically to guarantee security. Thanks to its modular design, integrating Progent does not alter agent internals and requires only minimal changes to agent implementation, enhancing its practicality and potential for widespread adoption. To automate policy writing, we leverage LLMs to generate policies based on user queries, which are then updated dynamically for improved security and utility. Our extensive evaluation shows that it enables strong security while preserving high utility across three distinct scenarios or benchmarks: AgentDojo, ASB, and AgentPoison. Furthermore, we perform an in-depth analysis, showcasing the effectiveness of its core components and the resilience of its automated policy generation against adaptive attacks.
SoK: Frontier AI's Impact on the Cybersecurity Landscape
Apr 07, 2025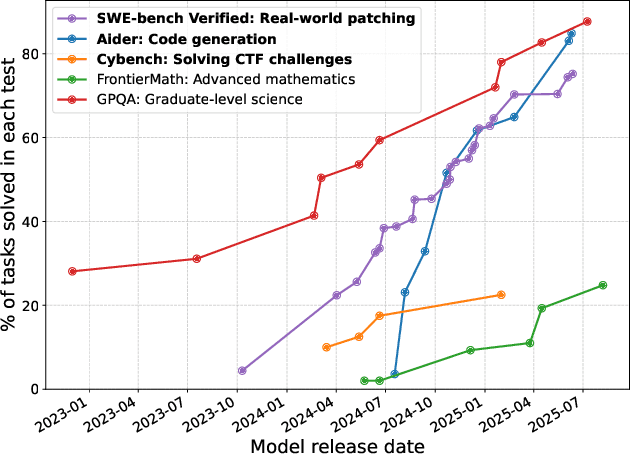
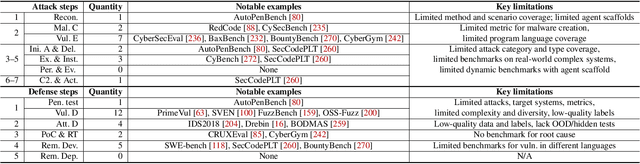
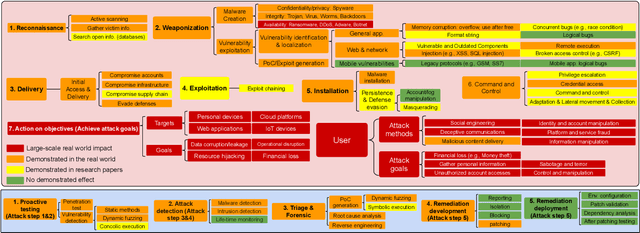

As frontier AI advances rapidly, understanding its impact on cybersecurity and inherent risks is essential to ensuring safe AI evolution (e.g., guiding risk mitigation and informing policymakers). While some studies review AI applications in cybersecurity, none of them comprehensively discuss AI's future impacts or provide concrete recommendations for navigating its safe and secure usage. This paper presents an in-depth analysis of frontier AI's impact on cybersecurity and establishes a systematic framework for risk assessment and mitigation. To this end, we first define and categorize the marginal risks of frontier AI in cybersecurity and then systemically analyze the current and future impacts of frontier AI in cybersecurity, qualitatively and quantitatively. We also discuss why frontier AI likely benefits attackers more than defenders in the short term from equivalence classes, asymmetry, and economic impact. Next, we explore frontier AI's impact on future software system development, including enabling complex hybrid systems while introducing new risks. Based on our findings, we provide security recommendations, including constructing fine-grained benchmarks for risk assessment, designing AI agents for defenses, building security mechanisms and provable defenses for hybrid systems, enhancing pre-deployment security testing and transparency, and strengthening defenses for users. Finally, we present long-term research questions essential for understanding AI's future impacts and unleashing its defensive capabilities.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.