 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivAgent: Agentic-based Red-teaming for LLM Privacy Leakage
Paper and Code

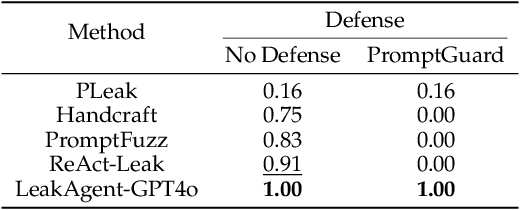
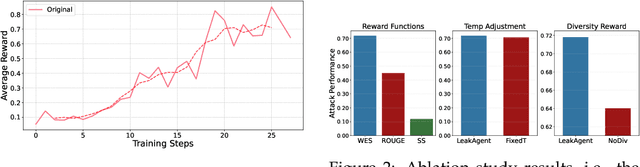

Recent studies have discovered that LLMs have serious privacy leakage concerns, where an LLM may be fooled into outputting private information under carefully crafted adversarial prompts. These risks include leaking system prompts, personally identifiable information, training data, and model parameters. Most existing red-teaming approaches for privacy leakage rely on humans to craft the adversarial prompts. A few automated methods are proposed for system prompt extraction, but they cannot be applied to more severe risks (e.g., training data extraction) and have limited effectiveness even for system prompt extraction. In this paper, we propose PrivAgent, a novel black-box red-teaming framework for LLM privacy leakage. We formulate different risks as a search problem with a unified attack goal. Our framework trains an open-source LLM through reinforcement learning as the attack agent to generate adversarial prompts for different target models under different risks. We propose a novel reward function to provide effective and fine-grained rewards for the attack agent. Finally, we introduce customizations to better fit our general framework to system prompt extraction and training data extraction. Through extensive evaluations, we first show that PrivAgent outperforms existing automated methods in system prompt leakage against six popular LLMs. Notably, our approach achieves a 100% success rate in extracting system prompts from real-world applications in OpenAI's GPT Store. We also show PrivAgent's effectiveness in extracting training data from an open-source LLM with a success rate of 5.9%. We further demonstrate PrivAgent's effectiveness in evading the existing guardrail defense and its helpfulness in enabling better safety alignment. Finally, we validate our customized designs through a detailed ablation study. We release our code here https://github.com/rucnyz/RedAgent.