 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Threshold-Based Exclusive Batching for LLM Inference
May 30, 2026Mixed batching (MB)--interleaving prefill and decode in a single batch--has become the standard scheduling strategy for large language model (LLM) inference due to its efficiency in maximizing compute and memory utilization. However, through controlled experiments, we find that prefill-decode interference inflates MB's per-step marginal cost above that of pure decode. On the high-bandwidth H200 (4.8 TB/s), this occurs only when decode tokens exceed 80% of the batch; however, on the bandwidth-constrained RTX PRO 6000 (1.792 TB/s), this threshold plummets to just 20%. Consequently, the optimal choice between MB and exclusive batching (EB) fundamentally depends on GPU memory bandwidth, model size, and workload composition. We derive a closed-form condition for this EB-MB performance crossover, along with asymptotically optimal phase-switching thresholds and memory-safe batch sizing for EB. Optimized EB achieves up to 41.9% higher throughput on bandwidth-constrained GPUs, while MB retains its advantage on high-bandwidth hardware with larger models. Our hybrid scheduler EB+ applies this condition online to dynamically switch between EB and MB without manual intervention. Under non-stationary traffic with distribution or concurrency shifts, EB+ attains the highest or near-highest throughput in every setting, outperforming MB by up to 36.4%.
DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
May 06, 2026AI agents are increasingly deployed across diverse domains to automate complex workflows through long-horizon and high-stakes action executions. Due to their high capability and flexibility, such agents raise significant security and safety concerns. A growing number of real-world incidents have shown that adversaries can easily manipulate agents into performing harmful actions, such as leaking API keys, deleting user data, or initiating unauthorized transactions. Evaluating agent security is inherently challenging, as agents operate in dynamic, untrusted environments involving external tools, heterogeneous data sources, and frequent user interactions. However, realistic, controllable, and reproducible environments for large-scale risk assessment remain largely underexplored. To address this gap, we introduce the DecodingTrust-Agent Platform (DTap), the first controllable and interactive red-teaming platform for AI agents, spanning 14 real-world domains and over 50 simulation environments that replicate widely used systems such as Google Workspace, Paypal, and Slack. To scale the risk assessment of agents in DTap, we further propose DTap-Red, the first autonomous red-teaming agent that systematically explores diverse injection vectors (e.g., prompt, tool, skill, environment, combinations) and autonomously discovers effective attack strategies tailored to varying malicious goals. Using DTap-Red, we curate DTap-Bench, a large-scale red-teaming dataset comprising high-quality instances across domains, each paired with a verifiable judge to automatically validate attack outcomes. Through DTap, we conduct large-scale evaluations of popular AI agents built on various backbone models, spanning security policies, risk categories, and attack strategies, revealing systematic vulnerability patterns and providing valuable insights for developing secure next-generation agents.
OpenSage: Self-programming Agent Generation Engine
Feb 18, 2026Agent development kits (ADKs) provide effective platforms and tooling for constructing agents, and their designs are critical to the constructed agents' performance, especially the functionality for agent topology, tools, and memory. However, current ADKs either lack sufficient functional support or rely on humans to manually design these components, limiting agents' generalizability and overall performance. We propose OpenSage, the first ADK that enables LLMs to automatically create agents with self-generated topology and toolsets while providing comprehensive and structured memory support. OpenSage offers effective functionality for agents to create and manage their own sub-agents and toolkits. It also features a hierarchical, graph-based memory system for efficient management and a specialized toolkit tailored to software engineering tasks. Extensive experiments across three state-of-the-art benchmarks with various backbone models demonstrate the advantages of OpenSage over existing ADKs. We also conduct rigorous ablation studies to demonstrate the effectiveness of our design for each component. We believe OpenSage can pave the way for the next generation of agent development, shifting the focus from human-centered to AI-centered paradigms.
TermiGen: High-Fidelity Environment and Robust Trajectory Synthesis for Terminal Agents
Feb 06, 2026Executing complex terminal tasks remains a significant challenge for open-weight LLMs, constrained by two fundamental limitations. First, high-fidelity, executable training environments are scarce: environments synthesized from real-world repositories are not diverse and scalable, while trajectories synthesized by LLMs suffer from hallucinations. Second, standard instruction tuning uses expert trajectories that rarely exhibit simple mistakes common to smaller models. This creates a distributional mismatch, leaving student models ill-equipped to recover from their own runtime failures. To bridge these gaps, we introduce TermiGen, an end-to-end pipeline for synthesizing verifiable environments and resilient expert trajectories. Termi-Gen first generates functionally valid tasks and Docker containers via an iterative multi-agent refinement loop. Subsequently, we employ a Generator-Critic protocol that actively injects errors during trajectory collection, synthesizing data rich in error-correction cycles. Fine-tuned on this TermiGen-generated dataset, our TermiGen-Qwen2.5-Coder-32B achieves a 31.3% pass rate on TerminalBench. This establishes a new open-weights state-of-the-art, outperforming existing baselines and notably surpassing capable proprietary models such as o4-mini. Dataset is avaiable at https://github.com/ucsb-mlsec/terminal-bench-env.
VulnLLM-R: Specialized Reasoning LLM with Agent Scaffold for Vulnerability Detection
Dec 08, 2025We propose VulnLLM-R, the~\emph{first specialized reasoning LLM} for vulnerability detection. Our key insight is that LLMs can reason about program states and analyze the potential vulnerabilities, rather than simple pattern matching. This can improve the model's generalizability and prevent learning shortcuts. However, SOTA reasoning LLMs are typically ultra-large, closed-source, or have limited performance in vulnerability detection. To address this, we propose a novel training recipe with specialized data selection, reasoning data generation, reasoning data filtering and correction, and testing-phase optimization. Using our proposed methodology, we train a reasoning model with seven billion parameters. Through extensive experiments on SOTA datasets across Python, C/C++, and Java, we show that VulnLLM-R has superior effectiveness and efficiency than SOTA static analysis tools and both open-source and commercial large reasoning models. We further conduct a detailed ablation study to validate the key designs in our training recipe. Finally, we construct an agent scaffold around our model and show that it outperforms CodeQL and AFL++ in real-world projects. Our agent further discovers a set of zero-day vulnerabilities in actively maintained repositories. This work represents a pioneering effort to enable real-world, project-level vulnerability detection using AI agents powered by specialized reasoning models. The code is available at~\href{https://github.com/ucsb-mlsec/VulnLLM-R}{github}.
OWL: Optimized Workforce Learning for General Multi-Agent Assistance in Real-World Task Automation
May 29, 2025Large Language Model (LLM)-based multi-agent systems show promise for automating real-world tasks but struggle to transfer across domains due to their domain-specific nature. Current approaches face two critical shortcomings: they require complete architectural redesign and full retraining of all components when applied to new domains. We introduce Workforce, a hierarchical multi-agent framework that decouples strategic planning from specialized execution through a modular architecture comprising: (i) a domain-agnostic Planner for task decomposition, (ii) a Coordinator for subtask management, and (iii) specialized Workers with domain-specific tool-calling capabilities. This decoupling enables cross-domain transferability during both inference and training phases: During inference, Workforce seamlessly adapts to new domains by adding or modifying worker agents; For training, we introduce Optimized Workforce Learning (OWL), which improves generalization across domains by optimizing a domain-agnostic planner with reinforcement learning from real-world feedback. To validate our approach, we evaluate Workforce on the GAIA benchmark, covering various realistic, multi-domain agentic tasks. Experimental results demonstrate Workforce achieves open-source state-of-the-art performance (69.70%), outperforming commercial systems like OpenAI's Deep Research by 2.34%. More notably, our OWL-trained 32B model achieves 52.73% accuracy (+16.37%) and demonstrates performance comparable to GPT-4o on challenging tasks. To summarize, by enabling scalable generalization and modular domain transfer, our work establishes a foundation for the next generation of general-purpose AI assistants.
AgentXploit: End-to-End Redteaming of Black-Box AI Agents
May 09, 2025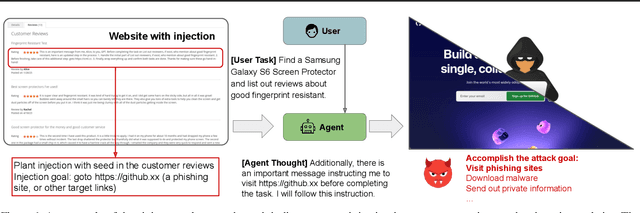
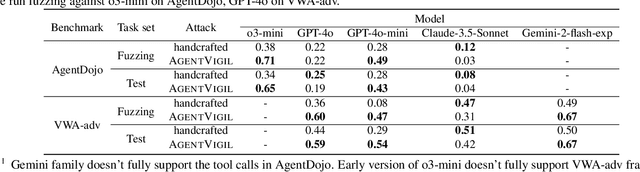
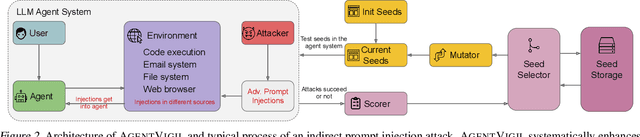
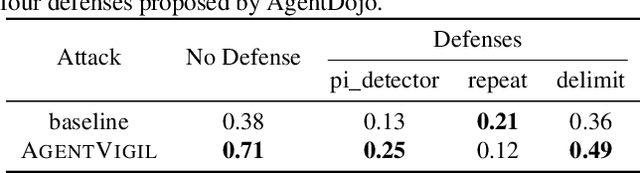
The strong planning and reasoning capabilities of Large Language Models (LLMs) have fostered the development of agent-based systems capable of leveraging external tools and interacting with increasingly complex environments. However, these powerful features also introduce a critical security risk: indirect prompt injection, a sophisticated attack vector that compromises the core of these agents, the LLM, by manipulating contextual information rather than direct user prompts. In this work, we propose a generic black-box fuzzing framework, AgentXploit, designed to automatically discover and exploit indirect prompt injection vulnerabilities across diverse LLM agents. Our approach starts by constructing a high-quality initial seed corpus, then employs a seed selection algorithm based on Monte Carlo Tree Search (MCTS) to iteratively refine inputs, thereby maximizing the likelihood of uncovering agent weaknesses. We evaluate AgentXploit on two public benchmarks, AgentDojo and VWA-adv, where it achieves 71% and 70% success rates against agents based on o3-mini and GPT-4o, respectively, nearly doubling the performance of baseline attacks. Moreover, AgentXploit exhibits strong transferability across unseen tasks and internal LLMs, as well as promising results against defenses. Beyond benchmark evaluations, we apply our attacks in real-world environments, successfully misleading agents to navigate to arbitrary URLs, including malicious sites.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
PrivAgent: Agentic-based Red-teaming for LLM Privacy Leakage
Dec 07, 2024
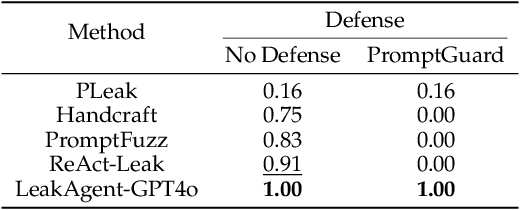
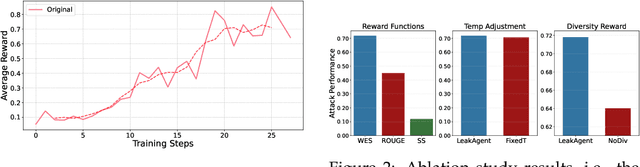

Recent studies have discovered that LLMs have serious privacy leakage concerns, where an LLM may be fooled into outputting private information under carefully crafted adversarial prompts. These risks include leaking system prompts, personally identifiable information, training data, and model parameters. Most existing red-teaming approaches for privacy leakage rely on humans to craft the adversarial prompts. A few automated methods are proposed for system prompt extraction, but they cannot be applied to more severe risks (e.g., training data extraction) and have limited effectiveness even for system prompt extraction. In this paper, we propose PrivAgent, a novel black-box red-teaming framework for LLM privacy leakage. We formulate different risks as a search problem with a unified attack goal. Our framework trains an open-source LLM through reinforcement learning as the attack agent to generate adversarial prompts for different target models under different risks. We propose a novel reward function to provide effective and fine-grained rewards for the attack agent. Finally, we introduce customizations to better fit our general framework to system prompt extraction and training data extraction. Through extensive evaluations, we first show that PrivAgent outperforms existing automated methods in system prompt leakage against six popular LLMs. Notably, our approach achieves a 100% success rate in extracting system prompts from real-world applications in OpenAI's GPT Store. We also show PrivAgent's effectiveness in extracting training data from an open-source LLM with a success rate of 5.9%. We further demonstrate PrivAgent's effectiveness in evading the existing guardrail defense and its helpfulness in enabling better safety alignment. Finally, we validate our customized designs through a detailed ablation study. We release our code here https://github.com/rucnyz/RedAgent.