 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Curator: Co-adaptive Curriculum Learning via Policy-Improvement Bandits for RL Post-Training
Feb 24, 2026Post-training large foundation models with reinforcement learning typically relies on massive and heterogeneous datasets, making effective curriculum learning both critical and challenging. In this work, we propose ACTOR-CURATOR, a scalable and fully automated curriculum learning framework for reinforcement learning post-training of large language models (LLMs). ACTOR-CURATOR learns a neural curator that dynamically selects training problems from large problem banks by directly optimizing for expected policy performance improvement. We formulate problem selection as a non-stationary stochastic bandit problem, derive a principled loss function based on online stochastic mirror descent, and establish regret guarantees under partial feedback. Empirically, ACTOR-CURATOR consistently outperforms uniform sampling and strong curriculum baselines across a wide range of challenging reasoning benchmarks, demonstrating improved training stability and efficiency. Notably, it achieves relative gains of 28.6% on AIME2024 and 30.5% on ARC-1D over the strongest baseline and up to 80% speedup. These results suggest that ACTOR-CURATOR is a powerful and practical approach for scalable LLM post-training.
Unsupervised Domain Adaptation via Similarity-based Prototypes for Cross-Modality Segmentation
Oct 23, 2025Deep learning models have achieved great success on various vision challenges, but a well-trained model would face drastic performance degradation when applied to unseen data. Since the model is sensitive to domain shift, unsupervised domain adaptation attempts to reduce the domain gap and avoid costly annotation of unseen domains. This paper proposes a novel framework for cross-modality segmentation via similarity-based prototypes. In specific, we learn class-wise prototypes within an embedding space, then introduce a similarity constraint to make these prototypes representative for each semantic class while separable from different classes. Moreover, we use dictionaries to store prototypes extracted from different images, which prevents the class-missing problem and enables the contrastive learning of prototypes, and further improves performance. Extensive experiments show that our method achieves better results than other state-of-the-art methods.
Distilling Tool Knowledge into Language Models via Back-Translated Traces
Jun 23, 2025Large language models (LLMs) often struggle with mathematical problems that require exact computation or multi-step algebraic reasoning. Tool-integrated reasoning (TIR) offers a promising solution by leveraging external tools such as code interpreters to ensure correctness, but it introduces inference-time dependencies that hinder scalability and deployment. In this work, we propose a new paradigm for distilling tool knowledge into LLMs purely through natural language. We first construct a Solver Agent that solves math problems by interleaving planning, symbolic tool calls, and reflective reasoning. Then, using a back-translation pipeline powered by multiple LLM-based agents, we convert interleaved TIR traces into natural language reasoning traces. A Translator Agent generates explanations for individual tool calls, while a Rephrase Agent merges them into a fluent and globally coherent narrative. Empirically, we show that fine-tuning a small open-source model on these synthesized traces enables it to internalize both tool knowledge and structured reasoning patterns, yielding gains on competition-level math benchmarks without requiring tool access at inference.
OWL: Optimized Workforce Learning for General Multi-Agent Assistance in Real-World Task Automation
May 29, 2025Large Language Model (LLM)-based multi-agent systems show promise for automating real-world tasks but struggle to transfer across domains due to their domain-specific nature. Current approaches face two critical shortcomings: they require complete architectural redesign and full retraining of all components when applied to new domains. We introduce Workforce, a hierarchical multi-agent framework that decouples strategic planning from specialized execution through a modular architecture comprising: (i) a domain-agnostic Planner for task decomposition, (ii) a Coordinator for subtask management, and (iii) specialized Workers with domain-specific tool-calling capabilities. This decoupling enables cross-domain transferability during both inference and training phases: During inference, Workforce seamlessly adapts to new domains by adding or modifying worker agents; For training, we introduce Optimized Workforce Learning (OWL), which improves generalization across domains by optimizing a domain-agnostic planner with reinforcement learning from real-world feedback. To validate our approach, we evaluate Workforce on the GAIA benchmark, covering various realistic, multi-domain agentic tasks. Experimental results demonstrate Workforce achieves open-source state-of-the-art performance (69.70%), outperforming commercial systems like OpenAI's Deep Research by 2.34%. More notably, our OWL-trained 32B model achieves 52.73% accuracy (+16.37%) and demonstrates performance comparable to GPT-4o on challenging tasks. To summarize, by enabling scalable generalization and modular domain transfer, our work establishes a foundation for the next generation of general-purpose AI assistants.
Understanding the Role of Equivariance in Self-supervised Learning
Nov 10, 2024Contrastive learning has been a leading paradigm for self-supervised learning, but it is widely observed that it comes at the price of sacrificing useful features (\eg colors) by being invariant to data augmentations. Given this limitation, there has been a surge of interest in equivariant self-supervised learning (E-SSL) that learns features to be augmentation-aware. However, even for the simplest rotation prediction method, there is a lack of rigorous understanding of why, when, and how E-SSL learns useful features for downstream tasks. To bridge this gap between practice and theory, we establish an information-theoretic perspective to understand the generalization ability of E-SSL. In particular, we identify a critical explaining-away effect in E-SSL that creates a synergy between the equivariant and classification tasks. This synergy effect encourages models to extract class-relevant features to improve its equivariant prediction, which, in turn, benefits downstream tasks requiring semantic features. Based on this perspective, we theoretically analyze the influence of data transformations and reveal several principles for practical designs of E-SSL. Our theory not only aligns well with existing E-SSL methods but also sheds light on new directions by exploring the benefits of model equivariance. We believe that a theoretically grounded understanding on the role of equivariance would inspire more principled and advanced designs in this field. Code is available at https://github.com/kaotty/Understanding-ESSL.
Practical hybrid PQC-QKD protocols with enhanced security and performance
Nov 05, 2024


Quantum resistance is vital for emerging cryptographic systems as quantum technologies continue to advance towards large-scale, fault-tolerant quantum computers. Resistance may be offered by quantum key distribution (QKD), which provides information-theoretic security using quantum states of photons, but may be limited by transmission loss at long distances. An alternative approach uses classical means and is conjectured to be resistant to quantum attacks, so-called post-quantum cryptography (PQC), but it is yet to be rigorously proven, and its current implementations are computationally expensive. To overcome the security and performance challenges present in each, here we develop hybrid protocols by which QKD and PQC inter-operate within a joint quantum-classical network. In particular, we consider different hybrid designs that may offer enhanced speed and/or security over the individual performance of either approach. Furthermore, we present a method for analyzing the security of hybrid protocols in key distribution networks. Our hybrid approach paves the way for joint quantum-classical communication networks, which leverage the advantages of both QKD and PQC and can be tailored to the requirements of various practical networks.
Evolving Alignment via Asymmetric Self-Play
Oct 31, 2024



Current RLHF frameworks for aligning large language models (LLMs) typically assume a fixed prompt distribution, which is sub-optimal and limits the scalability of alignment and generalizability of models. To address this, we introduce a general open-ended RLHF framework that casts alignment as an asymmetric game between two players: (i) a creator that generates increasingly informative prompt distributions using the reward model, and (ii) a solver that learns to produce more preferred responses on prompts produced by the creator. This framework of Evolving Alignment via Asymmetric Self-Play (eva), results in a simple and efficient approach that can utilize any existing RLHF algorithm for scalable alignment. eva outperforms state-of-the-art methods on widely-used benchmarks, without the need of any additional human crafted prompts. Specifically, eva improves the win rate of Gemma-2-9B-it on Arena-Hard from 51.6% to 60.1% with DPO, from 55.7% to 58.9% with SPPO, from 52.3% to 60.7% with SimPO, and from 54.8% to 60.3% with ORPO, surpassing its 27B version and matching claude-3-opus. This improvement is persistent even when new human crafted prompts are introduced. Finally, we show eva is effective and robust under various ablation settings.
Can Large Language Model Agents Simulate Human Trust Behaviors?
Feb 07, 2024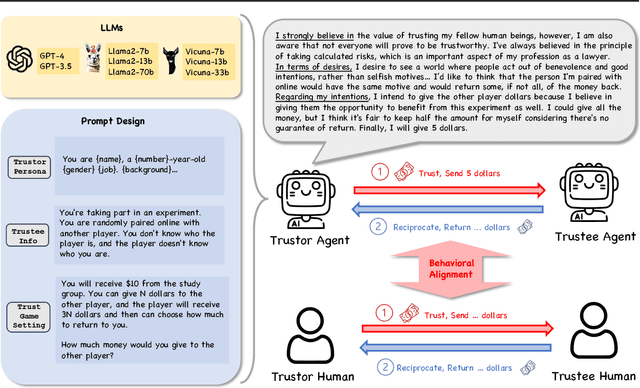
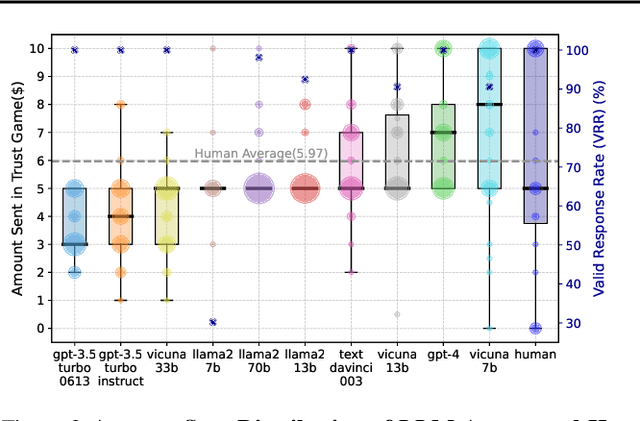
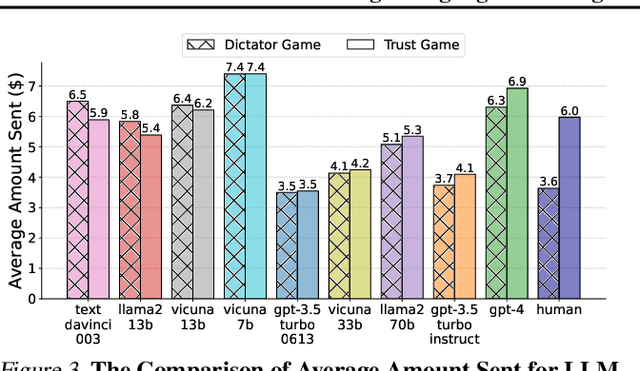
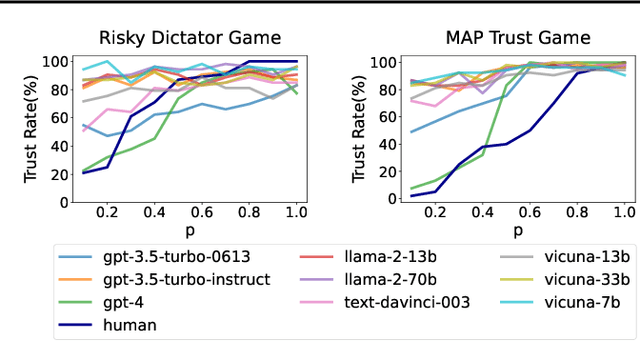
Large Language Model (LLM) agents have been increasingly adopted as simulation tools to model humans in applications such as social science. However, one fundamental question remains: can LLM agents really simulate human behaviors? In this paper, we focus on one of the most critical behaviors in human interactions, trust, and aim to investigate whether or not LLM agents can simulate human trust behaviors. We first find that LLM agents generally exhibit trust behaviors, referred to as agent trust, under the framework of Trust Games, which are widely recognized in behavioral economics. Then, we discover that LLM agents can have high behavioral alignment with humans regarding trust behaviors, indicating the feasibility to simulate human trust behaviors with LLM agents. In addition, we probe into the biases in agent trust and the differences in agent trust towards agents and humans. We also explore the intrinsic properties of agent trust under conditions including advanced reasoning strategies and external manipulations. We further offer important implications for various scenarios where trust is paramount. Our study represents a significant step in understanding the behaviors of LLM agents and the LLM-human analogy.
Follow-ups Also Matter: Improving Contextual Bandits via Post-serving Contexts
Sep 25, 2023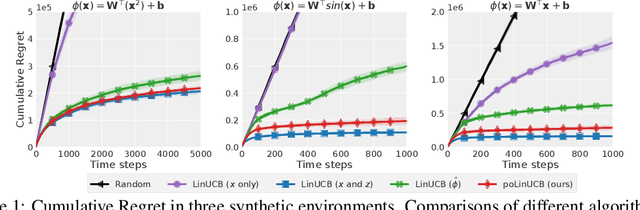
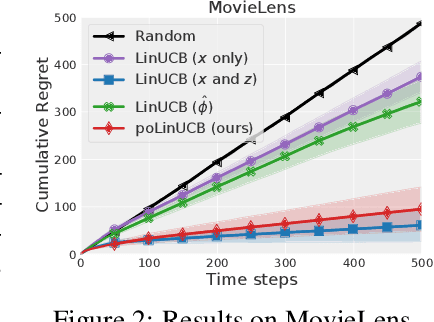
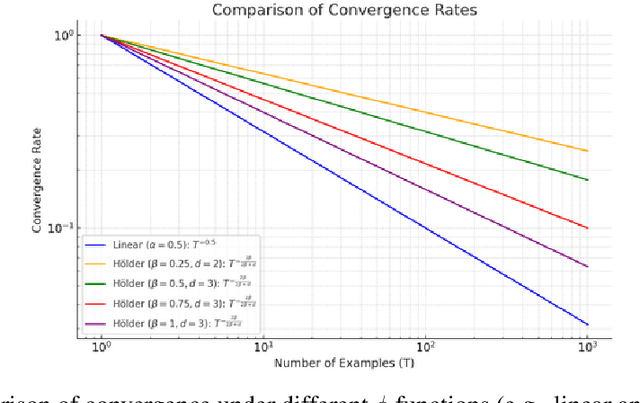
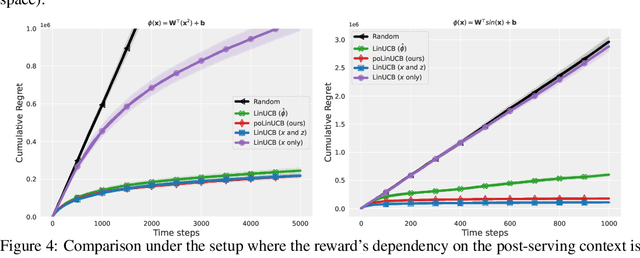
Standard contextual bandit problem assumes that all the relevant contexts are observed before the algorithm chooses an arm. This modeling paradigm, while useful, often falls short when dealing with problems in which valuable additional context can be observed after arm selection. For example, content recommendation platforms like Youtube, Instagram, Tiktok also observe valuable follow-up information pertinent to the user's reward after recommendation (e.g., how long the user stayed, what is the user's watch speed, etc.). To improve online learning efficiency in these applications, we study a novel contextual bandit problem with post-serving contexts and design a new algorithm, poLinUCB, that achieves tight regret under standard assumptions. Core to our technical proof is a robustified and generalized version of the well-known Elliptical Potential Lemma (EPL), which can accommodate noise in data. Such robustification is necessary for tackling our problem, and we believe it could also be of general interest. Extensive empirical tests on both synthetic and real-world datasets demonstrate the significant benefit of utilizing post-serving contexts as well as the superior performance of our algorithm over the state-of-the-art approaches.
Efficient Online Decision Tree Learning with Active Feature Acquisition
May 03, 2023



Constructing decision trees online is a classical machine learning problem. Existing works often assume that features are readily available for each incoming data point. However, in many real world applications, both feature values and the labels are unknown a priori and can only be obtained at a cost. For example, in medical diagnosis, doctors have to choose which tests to perform (i.e., making costly feature queries) on a patient in order to make a diagnosis decision (i.e., predicting labels). We provide a fresh perspective to tackle this practical challenge. Our framework consists of an active planning oracle embedded in an online learning scheme for which we investigate several information acquisition functions. Specifically, we employ a surrogate information acquisition function based on adaptive submodularity to actively query feature values with a minimal cost, while using a posterior sampling scheme to maintain a low regret for online prediction. We demonstrate the efficiency and effectiveness of our framework via extensive experiments on various real-world datasets. Our framework also naturally adapts to the challenging setting of online learning with concept drift and is shown to be competitive with baseline models while being more flexible.