 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards efficient quantum algorithms for diffusion probability models
Feb 20, 2025A diffusion probabilistic model (DPM) is a generative model renowned for its ability to produce high-quality outputs in tasks such as image and audio generation. However, training DPMs on large, high-dimensional datasets such as high-resolution images or audio incurs significant computational, energy, and hardware costs. In this work, we introduce efficient quantum algorithms for implementing DPMs through various quantum ODE solvers. These algorithms highlight the potential of quantum Carleman linearization for diverse mathematical structures, leveraging state-of-the-art quantum linear system solvers (QLSS) or linear combination of Hamiltonian simulations (LCHS). Specifically, we focus on two approaches: DPM-solver-$k$ which employs exact $k$-th order derivatives to compute a polynomial approximation of $\epsilon_\theta(x_\lambda,\lambda)$; and UniPC which uses finite difference of $\epsilon_\theta(x_\lambda,\lambda)$ at different points $(x_{s_m}, \lambda_{s_m})$ to approximate higher-order derivatives. As such, this work represents one of the most direct and pragmatic applications of quantum algorithms to large-scale machine learning models, presumably talking substantial steps towards demonstrating the practical utility of quantum computing.
Towards provably efficient quantum algorithms for large-scale machine-learning models
Mar 06, 2023Large machine learning models are revolutionary technologies of artificial intelligence whose bottlenecks include huge computational expenses, power, and time used both in the pre-training and fine-tuning process. In this work, we show that fault-tolerant quantum computing could possibly provide provably efficient resolutions for generic (stochastic) gradient descent algorithms, scaling as $O(T^2 \times \text{polylog}(n))$, where $n$ is the size of the models and $T$ is the number of iterations in the training, as long as the models are both sufficiently dissipative and sparse. Based on earlier efficient quantum algorithms for dissipative differential equations, we find and prove that similar algorithms work for (stochastic) gradient descent, the primary algorithm for machine learning. In practice, we benchmark instances of large machine learning models from 7 million to 103 million parameters. We find that, in the context of sparse training, a quantum enhancement is possible at the early stage of learning after model pruning, motivating a sparse parameter download and re-upload scheme. Our work shows solidly that fault-tolerant quantum algorithms could potentially contribute to most state-of-the-art, large-scale machine-learning problems.
Quantum Algorithms for Sampling Log-Concave Distributions and Estimating Normalizing Constants
Oct 12, 2022
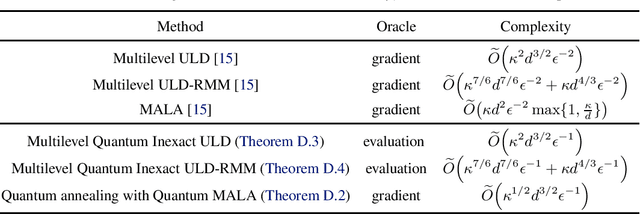
Given a convex function $f\colon\mathbb{R}^{d}\to\mathbb{R}$, the problem of sampling from a distribution $\propto e^{-f(x)}$ is called log-concave sampling. This task has wide applications in machine learning, physics, statistics, etc. In this work, we develop quantum algorithms for sampling log-concave distributions and for estimating their normalizing constants $\int_{\mathbb{R}^d}e^{-f(x)}\mathrm{d} x$. First, we use underdamped Langevin diffusion to develop quantum algorithms that match the query complexity (in terms of the condition number $\kappa$ and dimension $d$) of analogous classical algorithms that use gradient (first-order) queries, even though the quantum algorithms use only evaluation (zeroth-order) queries. For estimating normalizing constants, these algorithms also achieve quadratic speedup in the multiplicative error $\epsilon$. Second, we develop quantum Metropolis-adjusted Langevin algorithms with query complexity $\widetilde{O}(\kappa^{1/2}d)$ and $\widetilde{O}(\kappa^{1/2}d^{3/2}/\epsilon)$ for log-concave sampling and normalizing constant estimation, respectively, achieving polynomial speedups in $\kappa,d,\epsilon$ over the best known classical algorithms by exploiting quantum analogs of the Monte Carlo method and quantum walks. We also prove a $1/\epsilon^{1-o(1)}$ quantum lower bound for estimating normalizing constants, implying near-optimality of our quantum algorithms in $\epsilon$.