 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossFlow: One-Step Generation Across Latent and Pixel Spaces
Jun 18, 2026Most diffusion and flow-matching generators define the prior, probability path, and prediction target in the same representation space. Latent diffusion improves efficiency by moving this path into an autoencoder latent space, but the final sample is still produced by a separately trained decoder. This separation creates a mismatch: the generator is optimized for latent-space prediction, while final quality depends on how the decoder handles generated latents that may differ from clean encoder outputs. We introduce CrossFlow, a cross-space flow formulation that maps noisy latent inputs directly to pixel-space images. The key technical step is a velocity-free one-step objective: the latent trajectory defines the training path, but the supervised prediction is an image rather than a latent displacement. This lets one model act both as a one-step latent-to-pixel generator and as a decoder replacement for latent diffusion pipelines. On class-conditional ImageNet-1k at $256\times256$, CrossFlow-XL achieves 1.62 FID with one function evaluation. Ablations show that the latent encoder and pixel-space perceptual and adversarial losses are important for fidelity. These results indicate that cross-space flow objectives can combine the efficiency of latent representations with direct pixel-space supervision, without requiring a separate decoder at inference.
Project and Generate: Divergence-Free Neural Operators for Incompressible Flows
Mar 25, 2026Learning-based models for fluid dynamics often operate in unconstrained function spaces, leading to physically inadmissible, unstable simulations. While penalty-based methods offer soft regularization, they provide no structural guarantees, resulting in spurious divergence and long-term collapse. In this work, we introduce a unified framework that enforces the incompressible continuity equation as a hard, intrinsic constraint for both deterministic and generative modeling. First, to project deterministic models onto the divergence-free subspace, we integrate a differentiable spectral Leray projection grounded in the Helmholtz-Hodge decomposition, which restricts the regression hypothesis space to physically admissible velocity fields. Second, to generate physically consistent distributions, we show that simply projecting model outputs is insufficient when the prior is incompatible. To address this, we construct a divergence-free Gaussian reference measure via a curl-based pushforward, ensuring the entire probability flow remains subspace-consistent by construction. Experiments on 2D Navier-Stokes equations demonstrate exact incompressibility up to discretization error and substantially improved stability and physical consistency.
Accelerating PDE Surrogates via RL-Guided Mesh Optimization
Mar 02, 2026Deep surrogate models for parametric partial differential equations (PDEs) can deliver high-fidelity approximations but remain prohibitively data-hungry: training often requires thousands of fine-grid simulations, each incurring substantial computational cost. To address this challenge, we introduce RLMesh, an end-to-end framework for efficient surrogate training under limited simulation budget. The key idea is to use reinforcement learning (RL) to adaptively allocate mesh grid points non-uniformly within each simulation domain, focusing numerical resolution in regions most critical for accurate PDE solutions. A lightweight proxy model further accelerates RL training by providing efficient reward estimates without full surrogate retraining. Experiments on PDE benchmarks demonstrate that RLMesh achieves competitive accuracy to baselines but with substantially fewer simulation queries. These results show that solver-level spatial adaptivity can dramatically improve the efficiency of surrogate training pipelines, enabling practical deployment of learning-based PDE surrogates across a wide range of problems.
Hierarchical Implicit Neural Emulators
Jun 05, 2025Neural PDE solvers offer a powerful tool for modeling complex dynamical systems, but often struggle with error accumulation over long time horizons and maintaining stability and physical consistency. We introduce a multiscale implicit neural emulator that enhances long-term prediction accuracy by conditioning on a hierarchy of lower-dimensional future state representations. Drawing inspiration from the stability properties of numerical implicit time-stepping methods, our approach leverages predictions several steps ahead in time at increasing compression rates for next-timestep refinements. By actively adjusting the temporal downsampling ratios, our design enables the model to capture dynamics across multiple granularities and enforce long-range temporal coherence. Experiments on turbulent fluid dynamics show that our method achieves high short-term accuracy and produces long-term stable forecasts, significantly outperforming autoregressive baselines while adding minimal computational overhead.
Towards efficient quantum algorithms for diffusion probability models
Feb 20, 2025A diffusion probabilistic model (DPM) is a generative model renowned for its ability to produce high-quality outputs in tasks such as image and audio generation. However, training DPMs on large, high-dimensional datasets such as high-resolution images or audio incurs significant computational, energy, and hardware costs. In this work, we introduce efficient quantum algorithms for implementing DPMs through various quantum ODE solvers. These algorithms highlight the potential of quantum Carleman linearization for diverse mathematical structures, leveraging state-of-the-art quantum linear system solvers (QLSS) or linear combination of Hamiltonian simulations (LCHS). Specifically, we focus on two approaches: DPM-solver-$k$ which employs exact $k$-th order derivatives to compute a polynomial approximation of $\epsilon_\theta(x_\lambda,\lambda)$; and UniPC which uses finite difference of $\epsilon_\theta(x_\lambda,\lambda)$ at different points $(x_{s_m}, \lambda_{s_m})$ to approximate higher-order derivatives. As such, this work represents one of the most direct and pragmatic applications of quantum algorithms to large-scale machine learning models, presumably talking substantial steps towards demonstrating the practical utility of quantum computing.
Nested Diffusion Models Using Hierarchical Latent Priors
Dec 08, 2024We introduce nested diffusion models, an efficient and powerful hierarchical generative framework that substantially enhances the generation quality of diffusion models, particularly for images of complex scenes. Our approach employs a series of diffusion models to progressively generate latent variables at different semantic levels. Each model in this series is conditioned on the output of the preceding higher-level models, culminating in image generation. Hierarchical latent variables guide the generation process along predefined semantic pathways, allowing our approach to capture intricate structural details while significantly improving image quality. To construct these latent variables, we leverage a pre-trained visual encoder, which learns strong semantic visual representations, and modulate its capacity via dimensionality reduction and noise injection. Across multiple datasets, our system demonstrates significant enhancements in image quality for both unconditional and class/text conditional generation. Moreover, our unconditional generation system substantially outperforms the baseline conditional system. These advancements incur minimal computational overhead as the more abstract levels of our hierarchy work with lower-dimensional representations.
Embed and Emulate: Contrastive representations for simulation-based inference
Sep 27, 2024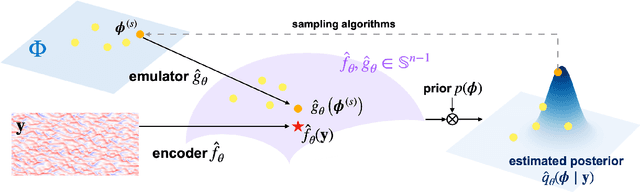

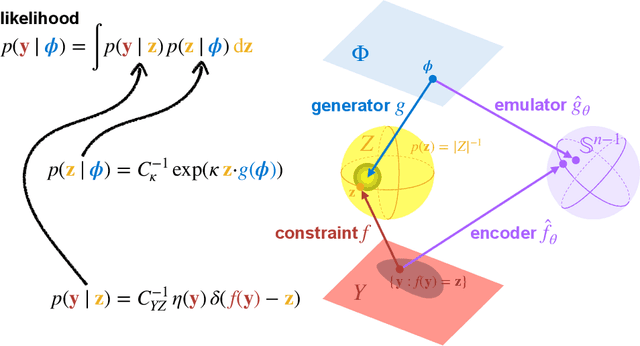

Scientific modeling and engineering applications rely heavily on parameter estimation methods to fit physical models and calibrate numerical simulations using real-world measurements. In the absence of analytic statistical models with tractable likelihoods, modern simulation-based inference (SBI) methods first use a numerical simulator to generate a dataset of parameters and simulated outputs. This dataset is then used to approximate the likelihood and estimate the system parameters given observation data. Several SBI methods employ machine learning emulators to accelerate data generation and parameter estimation. However, applying these approaches to high-dimensional physical systems remains challenging due to the cost and complexity of training high-dimensional emulators. This paper introduces Embed and Emulate (E&E): a new SBI method based on contrastive learning that efficiently handles high-dimensional data and complex, multimodal parameter posteriors. E&E learns a low-dimensional latent embedding of the data (i.e., a summary statistic) and a corresponding fast emulator in the latent space, eliminating the need to run expensive simulations or a high dimensional emulator during inference. We illustrate the theoretical properties of the learned latent space through a synthetic experiment and demonstrate superior performance over existing methods in a realistic, non-identifiable parameter estimation task using the high-dimensional, chaotic Lorenz 96 system.
Residual Connections Harm Self-Supervised Abstract Feature Learning
Apr 16, 2024



We demonstrate that adding a weighting factor to decay the strength of identity shortcuts within residual networks substantially improves semantic feature learning in the state-of-the-art self-supervised masked autoencoding (MAE) paradigm. Our modification to the identity shortcuts within a VIT-B/16 backbone of an MAE boosts linear probing accuracy on ImageNet from 67.3% to 72.3%. This significant gap suggests that, while residual connection structure serves an essential role in facilitating gradient propagation, it may have a harmful side effect of reducing capacity for abstract learning by virtue of injecting an echo of shallower representations into deeper layers. We ameliorate this downside via a fixed formula for monotonically decreasing the contribution of identity connections as layer depth increases. Our design promotes the gradual development of feature abstractions, without impacting network trainability. Analyzing the representations learned by our modified residual networks, we find correlation between low effective feature rank and downstream task performance.
Training neural operators to preserve invariant measures of chaotic attractors
Jun 01, 2023
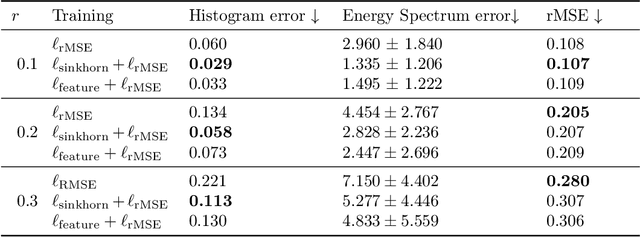


Chaotic systems make long-horizon forecasts difficult because small perturbations in initial conditions cause trajectories to diverge at an exponential rate. In this setting, neural operators trained to minimize squared error losses, while capable of accurate short-term forecasts, often fail to reproduce statistical or structural properties of the dynamics over longer time horizons and can yield degenerate results. In this paper, we propose an alternative framework designed to preserve invariant measures of chaotic attractors that characterize the time-invariant statistical properties of the dynamics. Specifically, in the multi-environment setting (where each sample trajectory is governed by slightly different dynamics), we consider two novel approaches to training with noisy data. First, we propose a loss based on the optimal transport distance between the observed dynamics and the neural operator outputs. This approach requires expert knowledge of the underlying physics to determine what statistical features should be included in the optimal transport loss. Second, we show that a contrastive learning framework, which does not require any specialized prior knowledge, can preserve statistical properties of the dynamics nearly as well as the optimal transport approach. On a variety of chaotic systems, our method is shown empirically to preserve invariant measures of chaotic attractors.
Deep Stochastic Mechanics
May 31, 2023This paper introduces a novel deep-learning-based approach for numerical simulation of a time-evolving Schr\"odinger equation inspired by stochastic mechanics and generative diffusion models. Unlike existing approaches, which exhibit computational complexity that scales exponentially in the problem dimension, our method allows us to adapt to the latent low-dimensional structure of the wave function by sampling from the Markovian diffusion. Depending on the latent dimension, our method may have far lower computational complexity in higher dimensions. Moreover, we propose novel equations for stochastic quantum mechanics, resulting in linear computational complexity with respect to the number of dimensions. Numerical simulations verify our theoretical findings and show a significant advantage of our method compared to other deep-learning-based approaches used for quantum mechanics.