 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Intrinsics Emerge from Training to Relight
May 31, 2024



Image relighting is the task of showing what a scene from a source image would look like if illuminated differently. Inverse graphics schemes recover an explicit representation of geometry and a set of chosen intrinsics, then relight with some form of renderer. However error control for inverse graphics is difficult, and inverse graphics methods can represent only the effects of the chosen intrinsics. This paper describes a relighting method that is entirely data-driven, where intrinsics and lighting are each represented as latent variables. Our approach produces SOTA relightings of real scenes, as measured by standard metrics. We show that albedo can be recovered from our latent intrinsics without using any example albedos, and that the albedos recovered are competitive with SOTA methods.
Residual Connections Harm Self-Supervised Abstract Feature Learning
Apr 16, 2024We demonstrate that adding a weighting factor to decay the strength of identity shortcuts within residual networks substantially improves semantic feature learning in the state-of-the-art self-supervised masked autoencoding (MAE) paradigm. Our modification to the identity shortcuts within a VIT-B/16 backbone of an MAE boosts linear probing accuracy on ImageNet from 67.3% to 72.3%. This significant gap suggests that, while residual connection structure serves an essential role in facilitating gradient propagation, it may have a harmful side effect of reducing capacity for abstract learning by virtue of injecting an echo of shallower representations into deeper layers. We ameliorate this downside via a fixed formula for monotonically decreasing the contribution of identity connections as layer depth increases. Our design promotes the gradual development of feature abstractions, without impacting network trainability. Analyzing the representations learned by our modified residual networks, we find correlation between low effective feature rank and downstream task performance.
Efficient Denoising using Score Embedding in Score-based Diffusion Models
Apr 10, 2024It is well known that training a denoising score-based diffusion models requires tens of thousands of epochs and a substantial number of image data to train the model. In this paper, we propose to increase the efficiency in training score-based diffusion models. Our method allows us to decrease the number of epochs needed to train the diffusion model. We accomplish this by solving the log-density Fokker-Planck (FP) Equation numerically to compute the score \textit{before} training. The pre-computed score is embedded into the image to encourage faster training under slice Wasserstein distance. Consequently, it also allows us to decrease the number of images we need to train the neural network to learn an accurate score. We demonstrate through our numerical experiments the improved performance of our proposed method compared to standard score-based diffusion models. Our proposed method achieves a similar quality to the standard method meaningfully faster.
Designing a Deep Learning-Driven Resource-Efficient Diagnostic System for Metastatic Breast Cancer: Reducing Long Delays of Clinical Diagnosis and Improving Patient Survival in Developing Countries
Aug 04, 2023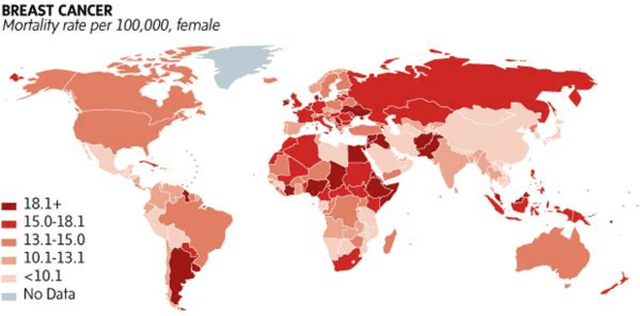
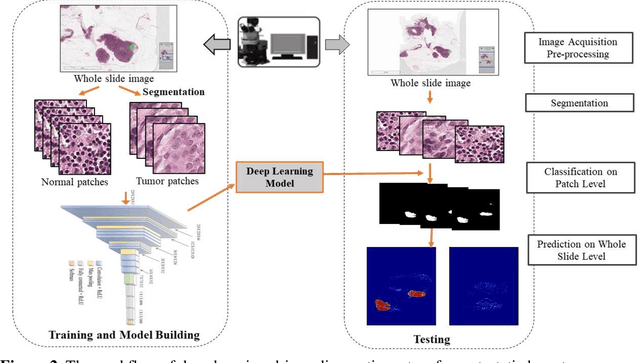
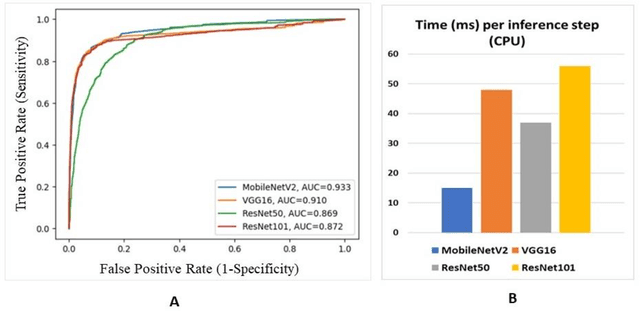
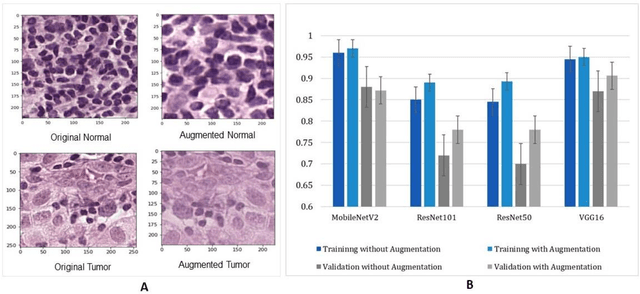
Breast cancer is one of the leading causes of cancer mortality. Breast cancer patients in developing countries, especially sub-Saharan Africa, South Asia, and South America, suffer from the highest mortality rate in the world. One crucial factor contributing to the global disparity in mortality rate is long delay of diagnosis due to a severe shortage of trained pathologists, which consequently has led to a large proportion of late-stage presentation at diagnosis. The delay between the initial development of symptoms and the receipt of a diagnosis could stretch upwards 15 months. To tackle this critical healthcare disparity, this research has developed a deep learning-based diagnosis system for metastatic breast cancer that can achieve high diagnostic accuracy as well as computational efficiency. Based on our evaluation, the MobileNetV2-based diagnostic model outperformed the more complex VGG16, ResNet50 and ResNet101 models in diagnostic accuracy, model generalization, and model training efficiency. The visual comparisons between the model prediction and ground truth have demonstrated that the MobileNetV2 diagnostic models can identify very small cancerous nodes embedded in a large area of normal cells which is challenging for manual image analysis. Equally Important, the light weighted MobleNetV2 models were computationally efficient and ready for mobile devices or devices of low computational power. These advances empower the development of a resource-efficient and high performing AI-based metastatic breast cancer diagnostic system that can adapt to under-resourced healthcare facilities in developing countries. This research provides an innovative technological solution to address the long delays in metastatic breast cancer diagnosis and the consequent disparity in patient survival outcome in developing countries.
TextDeformer: Geometry Manipulation using Text Guidance
Apr 26, 2023

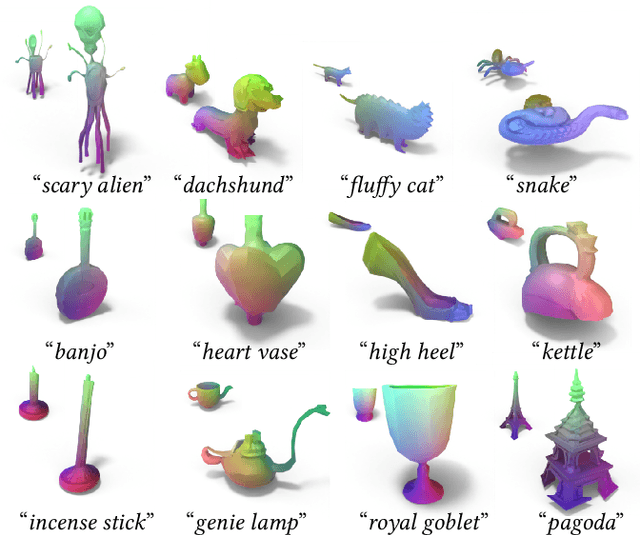

We present a technique for automatically producing a deformation of an input triangle mesh, guided solely by a text prompt. Our framework is capable of deformations that produce both large, low-frequency shape changes, and small high-frequency details. Our framework relies on differentiable rendering to connect geometry to powerful pre-trained image encoders, such as CLIP and DINO. Notably, updating mesh geometry by taking gradient steps through differentiable rendering is notoriously challenging, commonly resulting in deformed meshes with significant artifacts. These difficulties are amplified by noisy and inconsistent gradients from CLIP. To overcome this limitation, we opt to represent our mesh deformation through Jacobians, which updates deformations in a global, smooth manner (rather than locally-sub-optimal steps). Our key observation is that Jacobians are a representation that favors smoother, large deformations, leading to a global relation between vertices and pixels, and avoiding localized noisy gradients. Additionally, to ensure the resulting shape is coherent from all 3D viewpoints, we encourage the deep features computed on the 2D encoding of the rendering to be consistent for a given vertex from all viewpoints. We demonstrate that our method is capable of smoothly-deforming a wide variety of source mesh and target text prompts, achieving both large modifications to, e.g., body proportions of animals, as well as adding fine semantic details, such as shoe laces on an army boot and fine details of a face.
TetGAN: A Convolutional Neural Network for Tetrahedral Mesh Generation
Oct 11, 2022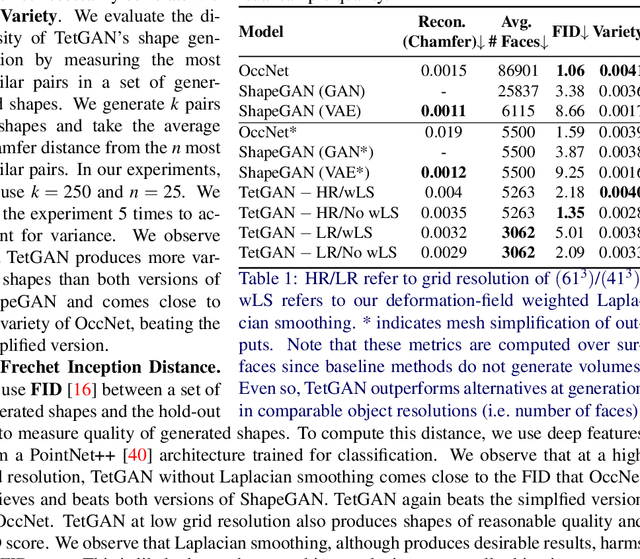

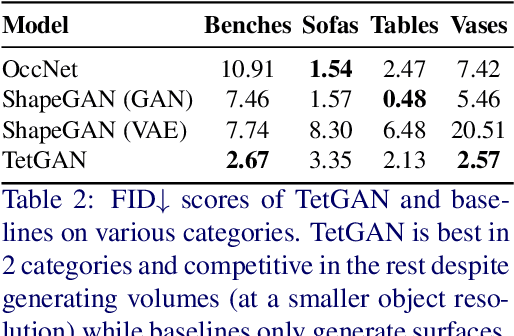

We present TetGAN, a convolutional neural network designed to generate tetrahedral meshes. We represent shapes using an irregular tetrahedral grid which encodes an occupancy and displacement field. Our formulation enables defining tetrahedral convolution, pooling, and upsampling operations to synthesize explicit mesh connectivity with variable topological genus. The proposed neural network layers learn deep features over each tetrahedron and learn to extract patterns within spatial regions across multiple scales. We illustrate the capabilities of our technique to encode tetrahedral meshes into a semantically meaningful latent-space which can be used for shape editing and synthesis. Our project page is at https://threedle.github.io/tetGAN/.