 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning a Deep Learning-Driven Resource-Efficient Diagnostic System for Metastatic Breast Cancer: Reducing Long Delays of Clinical Diagnosis and Improving Patient Survival in Developing Countries
Aug 04, 2023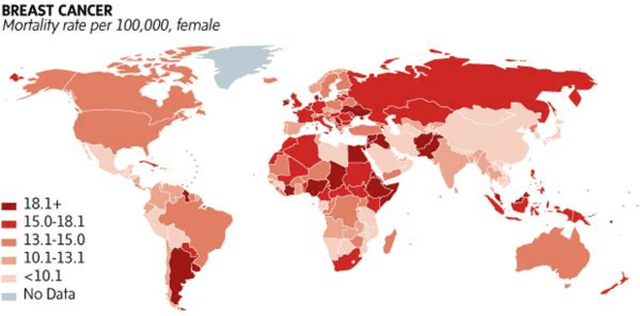
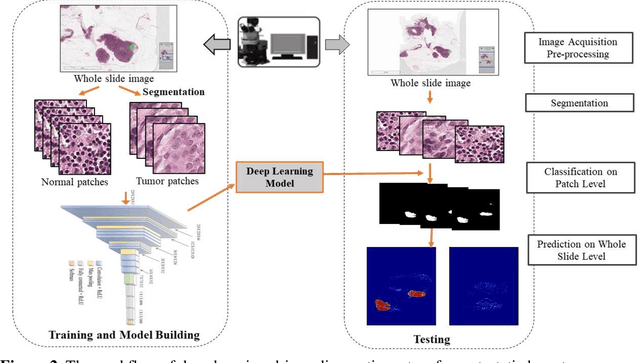
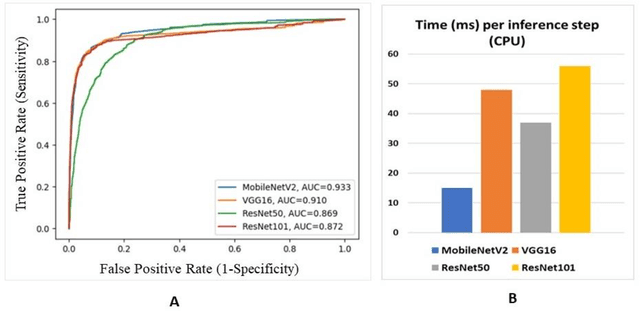
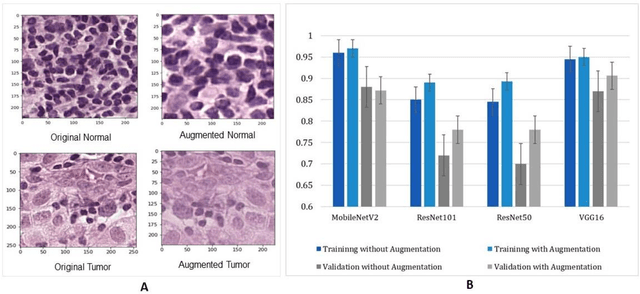
Breast cancer is one of the leading causes of cancer mortality. Breast cancer patients in developing countries, especially sub-Saharan Africa, South Asia, and South America, suffer from the highest mortality rate in the world. One crucial factor contributing to the global disparity in mortality rate is long delay of diagnosis due to a severe shortage of trained pathologists, which consequently has led to a large proportion of late-stage presentation at diagnosis. The delay between the initial development of symptoms and the receipt of a diagnosis could stretch upwards 15 months. To tackle this critical healthcare disparity, this research has developed a deep learning-based diagnosis system for metastatic breast cancer that can achieve high diagnostic accuracy as well as computational efficiency. Based on our evaluation, the MobileNetV2-based diagnostic model outperformed the more complex VGG16, ResNet50 and ResNet101 models in diagnostic accuracy, model generalization, and model training efficiency. The visual comparisons between the model prediction and ground truth have demonstrated that the MobileNetV2 diagnostic models can identify very small cancerous nodes embedded in a large area of normal cells which is challenging for manual image analysis. Equally Important, the light weighted MobleNetV2 models were computationally efficient and ready for mobile devices or devices of low computational power. These advances empower the development of a resource-efficient and high performing AI-based metastatic breast cancer diagnostic system that can adapt to under-resourced healthcare facilities in developing countries. This research provides an innovative technological solution to address the long delays in metastatic breast cancer diagnosis and the consequent disparity in patient survival outcome in developing countries.
Predicting breast tumor proliferation from whole-slide images: the TUPAC16 challenge
Jul 22, 2018
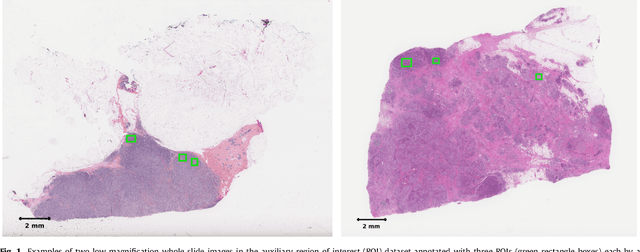
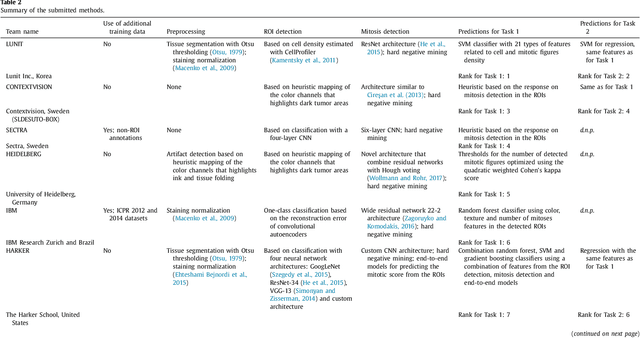
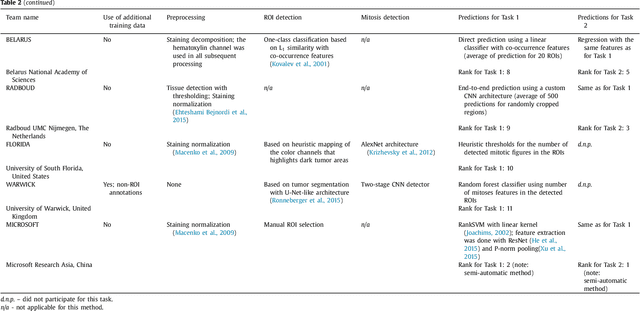
Tumor proliferation is an important biomarker indicative of the prognosis of breast cancer patients. Assessment of tumor proliferation in a clinical setting is highly subjective and labor-intensive task. Previous efforts to automate tumor proliferation assessment by image analysis only focused on mitosis detection in predefined tumor regions. However, in a real-world scenario, automatic mitosis detection should be performed in whole-slide images (WSIs) and an automatic method should be able to produce a tumor proliferation score given a WSI as input. To address this, we organized the TUmor Proliferation Assessment Challenge 2016 (TUPAC16) on prediction of tumor proliferation scores from WSIs. The challenge dataset consisted of 500 training and 321 testing breast cancer histopathology WSIs. In order to ensure fair and independent evaluation, only the ground truth for the training dataset was provided to the challenge participants. The first task of the challenge was to predict mitotic scores, i.e., to reproduce the manual method of assessing tumor proliferation by a pathologist. The second task was to predict the gene expression based PAM50 proliferation scores from the WSI. The best performing automatic method for the first task achieved a quadratic-weighted Cohen's kappa score of $\kappa$ = 0.567, 95% CI [0.464, 0.671] between the predicted scores and the ground truth. For the second task, the predictions of the top method had a Spearman's correlation coefficient of r = 0.617, 95% CI [0.581 0.651] with the ground truth. This was the first study that investigated tumor proliferation assessment from WSIs. The achieved results are promising given the difficulty of the tasks and weakly-labelled nature of the ground truth. However, further research is needed to improve the practical utility of image analysis methods for this task.
Deep Learning Assessment of Tumor Proliferation in Breast Cancer Histological Images
Oct 11, 2016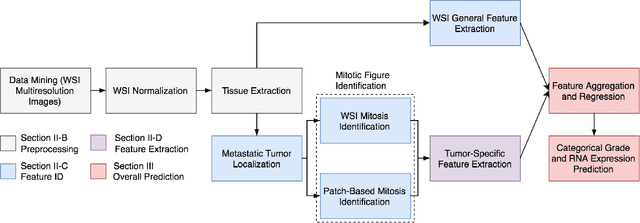
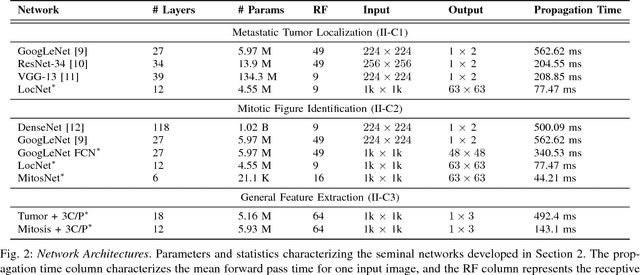
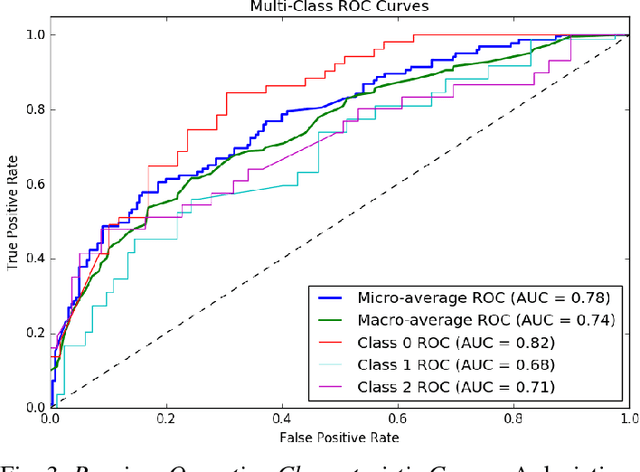
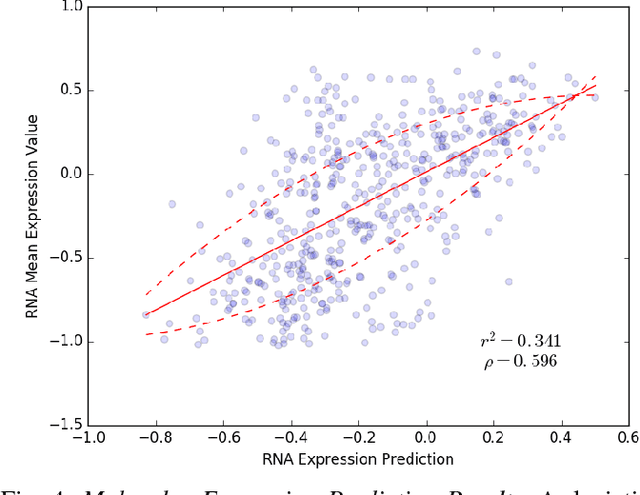
Current analysis of tumor proliferation, the most salient prognostic biomarker for invasive breast cancer, is limited to subjective mitosis counting by pathologists in localized regions of tissue images. This study presents the first data-driven integrative approach to characterize the severity of tumor growth and spread on a categorical and molecular level, utilizing multiple biologically salient deep learning classifiers to develop a comprehensive prognostic model. Our approach achieves pathologist-level performance on three-class categorical tumor severity prediction. It additionally pioneers prediction of molecular expression data from a tissue image, obtaining a Spearman's rank correlation coefficient of 0.60 with ex vivo mean calculated RNA expression. Furthermore, our framework is applied to identify over two hundred unprecedented biomarkers critical to the accurate assessment of tumor proliferation, validating our proposed integrative pipeline as the first to holistically and objectively analyze histopathological images.
Deep Learning for Identifying Metastatic Breast Cancer
Jun 18, 2016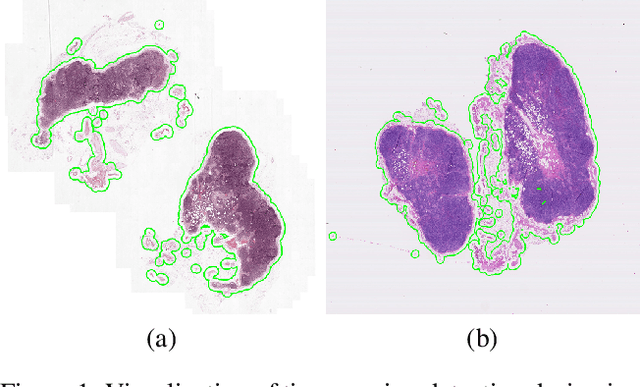
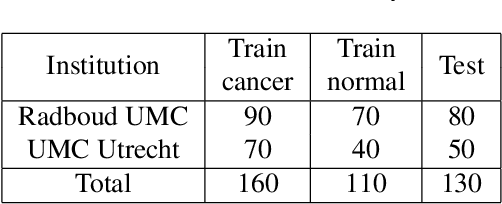
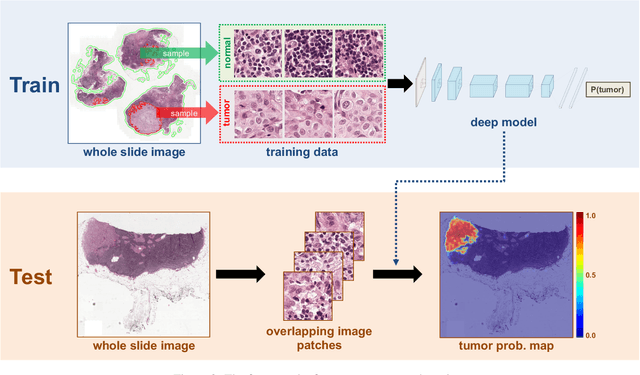
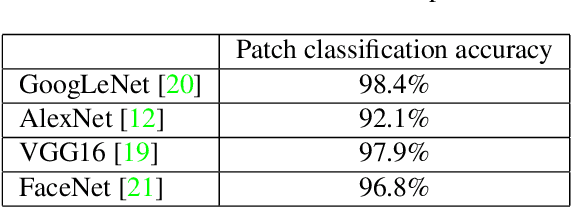
The International Symposium on Biomedical Imaging (ISBI) held a grand challenge to evaluate computational systems for the automated detection of metastatic breast cancer in whole slide images of sentinel lymph node biopsies. Our team won both competitions in the grand challenge, obtaining an area under the receiver operating curve (AUC) of 0.925 for the task of whole slide image classification and a score of 0.7051 for the tumor localization task. A pathologist independently reviewed the same images, obtaining a whole slide image classification AUC of 0.966 and a tumor localization score of 0.733. Combining our deep learning system's predictions with the human pathologist's diagnoses increased the pathologist's AUC to 0.995, representing an approximately 85 percent reduction in human error rate. These results demonstrate the power of using deep learning to produce significant improvements in the accuracy of pathological diagnoses.
Clustering Millions of Faces by Identity
Apr 04, 2016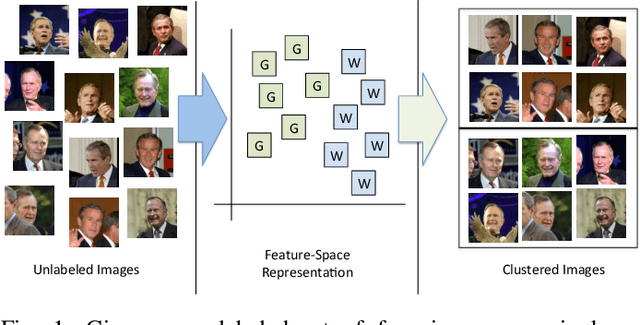

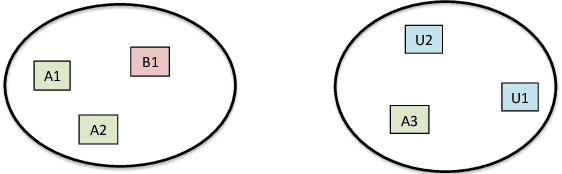
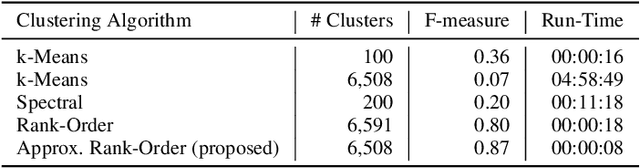
In this work, we attempt to address the following problem: Given a large number of unlabeled face images, cluster them into the individual identities present in this data. We consider this a relevant problem in different application scenarios ranging from social media to law enforcement. In large-scale scenarios the number of faces in the collection can be of the order of hundreds of million, while the number of clusters can range from a few thousand to millions--leading to difficulties in terms of both run-time complexity and evaluating clustering and per-cluster quality. An efficient and effective Rank-Order clustering algorithm is developed to achieve the desired scalability, and better clustering accuracy than other well-known algorithms such as k-means and spectral clustering. We cluster up to 123 million face images into over 10 million clusters, and analyze the results in terms of both external cluster quality measures (known face labels) and internal cluster quality measures (unknown face labels) and run-time. Our algorithm achieves an F-measure of 0.87 on a benchmark unconstrained face dataset (LFW, consisting of 13K faces), and 0.27 on the largest dataset considered (13K images in LFW, plus 123M distractor images). Additionally, we present preliminary work on video frame clustering (achieving 0.71 F-measure when clustering all frames in the benchmark YouTube Faces dataset). A per-cluster quality measure is developed which can be used to rank individual clusters and to automatically identify a subset of good quality clusters for manual exploration.
Face Search at Scale: 80 Million Gallery
Jul 28, 2015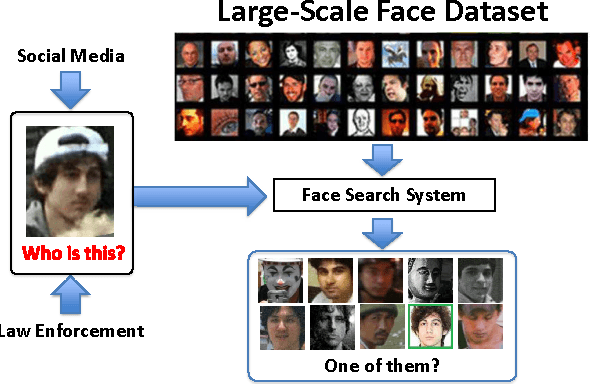
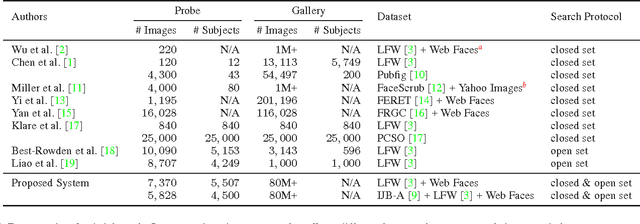
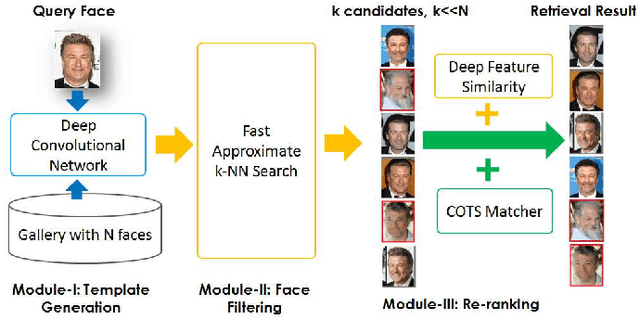
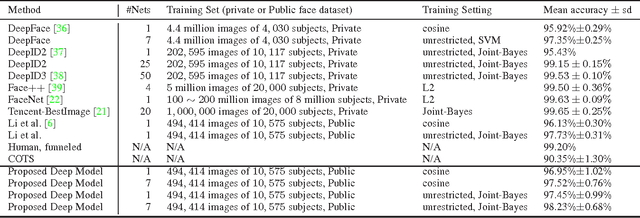
Due to the prevalence of social media websites, one challenge facing computer vision researchers is to devise methods to process and search for persons of interest among the billions of shared photos on these websites. Facebook revealed in a 2013 white paper that its users have uploaded more than 250 billion photos, and are uploading 350 million new photos each day. Due to this humongous amount of data, large-scale face search for mining web images is both important and challenging. Despite significant progress in face recognition, searching a large collection of unconstrained face images has not been adequately addressed. To address this challenge, we propose a face search system which combines a fast search procedure, coupled with a state-of-the-art commercial off the shelf (COTS) matcher, in a cascaded framework. Given a probe face, we first filter the large gallery of photos to find the top-k most similar faces using deep features generated from a convolutional neural network. The k candidates are re-ranked by combining similarities from deep features and the COTS matcher. We evaluate the proposed face search system on a gallery containing 80 million web-downloaded face images. Experimental results demonstrate that the deep features are competitive with state-of-the-art methods on unconstrained face recognition benchmarks (LFW and IJB-A). Further, the proposed face search system offers an excellent trade-off between accuracy and scalability on datasets consisting of millions of images. Additionally, in an experiment involving searching for face images of the Tsarnaev brothers, convicted of the Boston Marathon bombing, the proposed face search system could find the younger brother's (Dzhokhar Tsarnaev) photo at rank 1 in 1 second on a 5M gallery and at rank 8 in 7 seconds on an 80M gallery.
A Framework of Sparse Online Learning and Its Applications
Jul 25, 2015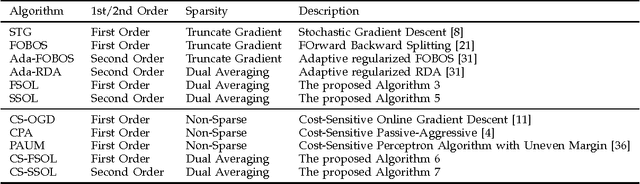
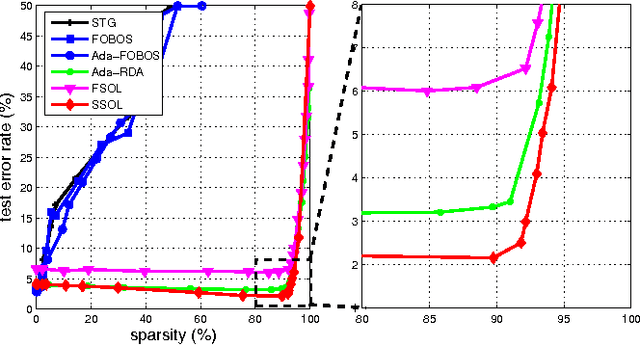
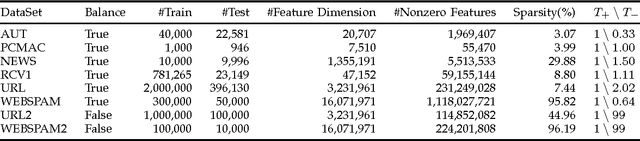
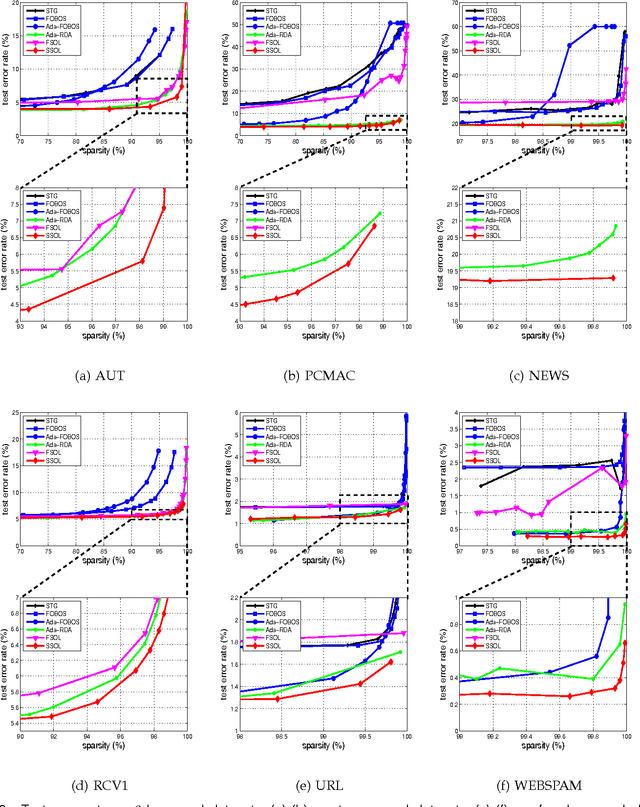
The amount of data in our society has been exploding in the era of big data today. In this paper, we address several open challenges of big data stream classification, including high volume, high velocity, high dimensionality, high sparsity, and high class-imbalance. Many existing studies in data mining literature solve data stream classification tasks in a batch learning setting, which suffers from poor efficiency and scalability when dealing with big data. To overcome the limitations, this paper investigates an online learning framework for big data stream classification tasks. Unlike some existing online data stream classification techniques that are often based on first-order online learning, we propose a framework of Sparse Online Classification (SOC) for data stream classification, which includes some state-of-the-art first-order sparse online learning algorithms as special cases and allows us to derive a new effective second-order online learning algorithm for data stream classification. In addition, we also propose a new cost-sensitive sparse online learning algorithm by extending the framework with application to tackle online anomaly detection tasks where class distribution of data could be very imbalanced. We also analyze the theoretical bounds of the proposed method, and finally conduct an extensive set of experiments, in which encouraging results validate the efficacy of the proposed algorithms in comparison to a family of state-of-the-art techniques on a variety of data stream classification tasks.